The latest review of controllable image generation!

In the rapidly evolving field of visual generation, diffusion models have revolutionized the landscape, marking a major shift in capabilities with their impressive text-guided generation capabilities.
However, relying solely on text to regulate these models cannot fully meet the diverse and complex needs of different applications and scenarios.
Given this shortcoming, many studies aim to control pretrained text-to-image (T2I) models to support new conditions.
In this review, researchers from Beijing University of Posts and Telecommunications conduct a thorough review of the literature on controllable generation of T2I diffusion models, covering both theoretical foundations and practical advances in this field.

Paper: https://arxiv.org/abs/2403.04279 Code: https://github.com/PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models
Our review begins with a brief introduction to denoised diffusion probabilistic models (DDPMs) and the basis of widely used T2I diffusion models.
We then reveal the control mechanism of the diffusion model and theoretically analyze how to introduce new conditions into the denoising process for conditional generation.
Furthermore, we provide a thorough overview of the research in this area and organize it into different categories according to the conditional perspective: generation with specific conditions, generation with multiple conditions, and general controllability generation.
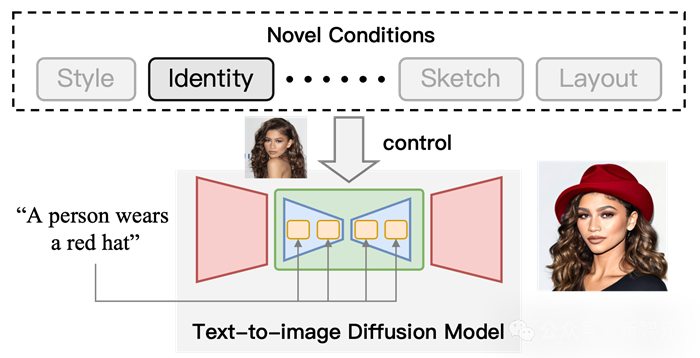
Figure 1 Schematic diagram of controllable generation using T2I diffusion model. On the basis of text conditions, add "identity" conditions to control the output results.
Classification system
The task of leveraging text diffusion models for conditional generation represents a multifaceted and complex field. From a conditional perspective, we divide this task into three subtasks (see Figure 2).
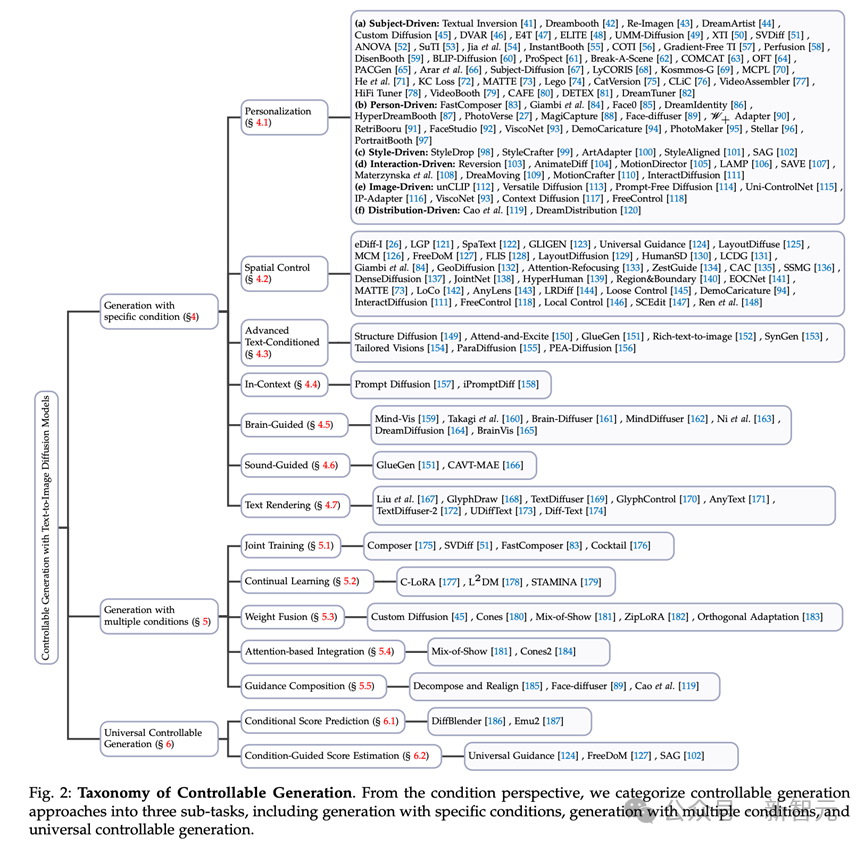
Figure 2 Classification of controllable generation. From a condition perspective, we divide the controllable generation method into three subtasks, including generation with specific conditions, generation with multiple conditions, and general controllable generation.
Most research focuses on how to generate images under specific conditions, such as image-guided generation and sketch-to-image generation.
In order to reveal the theory and characteristics of these methods, we further classify them according to their condition types.
1. Generate using specific conditions: guides the method of introducing specific types of conditions, including customized conditions (Personalization, eg, DreamBooth, Textual Inversion), and more direct conditions, such as ControlNet series, physiological signal-to-Image
2. Multi-condition generation: Using multiple conditions to generate, we subdivide this task from a technical perspective.
3. Unified controllable generation: This task aims to be able to generate using arbitrary conditions (even any number).
How to introduce new conditions in the T2I diffusion model
Please refer to the original paper for details. The mechanisms of these methods are briefly introduced below.
Conditional Score Prediction
In the T2I diffusion model, utilizing a trainable model (such as UNet) to predict the probability score (i.e., noise) in the denoising process is a basic and effective method.
In condition-based score prediction methods, novel conditions are used as inputs to the prediction model to directly predict new scores.

It can be divided into three methods of introducing new conditions:
1. Model-based condition score prediction: This type of method will introduce a model to encode novel conditions, and use the encoding features as the input of UNet (such as acting on the cross-attention layer) to predict the score results under novel conditions;
2. Conditional score prediction based on fine-tuning: This type of method does not use an explicit condition, but fine-tune the parameters of the text embedding and denoising network to learn the information of novel conditions, thereby using the fine-tuned weights to achieve feasible results. control generation. For example, DreamBooth and Textual Inversion are such practices.
3. Conditional score prediction without training: This type of method does not require training the model, and can directly apply conditions to the prediction link of the model. For example, in the Layout-to-Image (layout image generation) task, the cross-attention can be directly modified. The attention map of the layer is used to set the layout of the object.
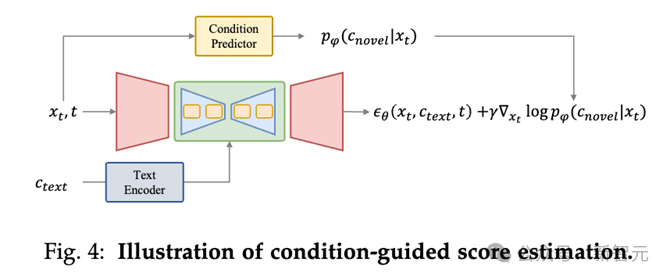
Conditionally guided score evaluation
The score estimation method of conditional guidance estimation is to add conditional guidance during the denoising process by back-propagating the gradient through the conditional prediction model (such as the Condition Predictor above).
Generate using specific conditions

1. Personalization (customization): The customization task aims to capture and utilize concepts as generation conditions for controllable generation. These conditions are not easy to describe through text and need to be extracted from sample images. Such as DreamBooth, Texutal Inversion and LoRA.
2. Spatial Control: Since text is difficult to represent structural information, i.e., location and dense labels, using spatial signals to control text-to-image diffusion methods is an important research area, such as layout, human pose, and human body parsing. Methods such as ControlNet.
3. Advanced Text-Conditioned Generation: Although text plays the role of basic condition in text-to-image diffusion models, there are still some challenges in this field.
First, text misalignment problems are often encountered when performing text-guided synthesis in complex texts involving multiple topics or rich descriptions. In addition, these models are mainly trained on English data sets, resulting in a significant lack of multi-language generation capabilities. To address this limitation, many works have proposed innovative approaches aimed at extending the scope of these model languages.
4. In-Context Generation: In the context generation task, a specific task is understood and performed on a new query image based on a pair of task-specific example images and text guidance.
5. Brain-Guided Generation: Brain-Guided Generation tasks focus on controlling image creation directly from brain activity, such as electroencephalography (EEG) recordings and functional magnetic resonance imaging (fMRI).
6. Sound-Guided Generation: Generate matching images based on sound.
7. Text Rendering: Generating text in images, which can be widely used in application scenarios such as posters, data covers, and emoticons.
Multi-condition generation

The multi-condition generation task aims to generate images based on multiple conditions, such as generating a specific person in a user-defined pose or generating a person in three personalized identities.
In this section, we provide a comprehensive overview of these methods from a technical perspective and classify them into the following categories:
1. Joint Training: Introducing multiple conditions for joint training during the training phase.
2. Continual Learning: Learn multiple conditions in sequence, and do not forget the old conditions while learning new conditions to achieve multi-condition generation.
3. Weight Fusion: Use parameters obtained by fine-tuning under different conditions for weight fusion, so that the model can be generated under multiple conditions at the same time.
4. Attention-based Integration: Set the positions of multiple conditions (usually objects) in the image through attention map to achieve multi-condition generation.
General condition generation
In addition to methods tailored to specific types of conditions, there are also general methods designed to adapt to arbitrary conditions in image generation.
These methods are broadly classified into two groups based on their theoretical foundations: general conditional score prediction frameworks and general conditional guided score estimation.
1. Universal Condition Score Prediction Framework: The Universal Condition Score Prediction Framework works by creating a framework that can encode any given conditions and exploit them to predict noise at every time step during image synthesis.
This approach provides a versatile solution that can be flexibly adapted to a variety of conditions. By directly integrating conditional information into the generative model, this approach allows the image generation process to be dynamically adjusted according to various conditions, making it versatile and applicable to various image synthesis scenarios.
2. General condition-guided score estimation: Other methods utilize condition-guided score estimation to incorporate various conditions into text-to-image diffusion models. The main challenge lies in obtaining condition-specific guidance from latent variables during denoising.
application
Introducing novel conditions can be useful in multiple tasks, including image editing, image completion, image combination, and text/image generation 3D.
For example, in image editing, a customized method can be used to edit the cat appearing in the picture into a cat with a specific identity. For other information, please refer to the paper.
Summarize
This review delves into the field of conditional generation of text-to-image diffusion models, revealing novel conditions that are incorporated into the text-guided generation process.
First, the author provides readers with basic knowledge, introducing denoising diffusion probabilistic models, well-known text-to-image diffusion models, and a well-structured taxonomy. Subsequently, the authors revealed the mechanism for introducing novel conditions into the T2I diffusion model.
Then, the author summarizes previous conditional generation methods and analyzes them from the aspects of theoretical foundation, technical progress, and solution strategies.
In addition, the author explores the practical applications of controllable generation, emphasizing its important role and huge potential in the era of AI content generation.
This survey aims to provide a comprehensive understanding of the current status of the field of controllable T2I generation, thereby promoting the continued evolution and expansion of this dynamic research field.