Content delivery network (CDN) system design

Content delivery network (CDN) system design
A CDN is a geographically distributed set of proxy servers. A proxy server is an intermediary server between the client and the origin server. These proxy servers are located at the edge of the network, close to end users. The placement of proxy servers helps deliver content to end users quickly by reducing latency and saving bandwidth. CDNs also feature additional intelligence for optimizing traffic routing and enforcing rules to protect against DDoS attacks or other unusual network events.

Essentially, CDN solves two problems:
- High latency. If your service is deployed in the United States, latency will be higher in Asia due to the physical distance from the providing data center.
- Data-intensive applications: They transfer large amounts of data. Over longer distances, problems can arise due to the presence of multiple internet service providers in the path. Some of them may have smaller links, congestion, packet loss, and other issues. The longer the distance, the more service providers are on the path and the higher the chance that one of them will have a problem.
Let's start with high-level component design and main workflow.
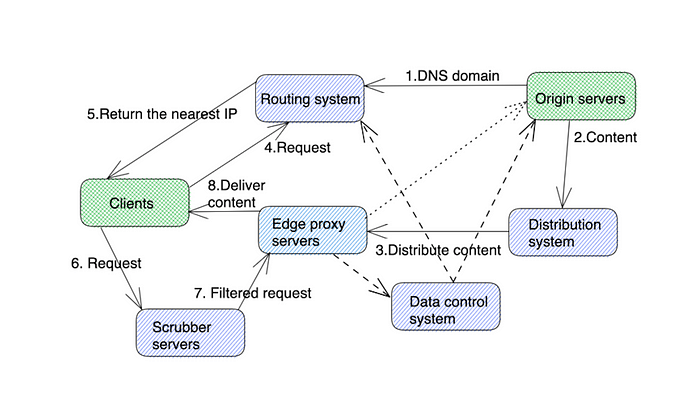
High level architecture
- The routing system directs clients to the nearest or optimal CDN location. To perform this function efficiently, this component receives input from various systems to understand where the request is coming from, where the content is located, how busy the data center is, and more. There are two most popular routing systems: DNS with load balancing and Anycast. We will discuss them in the video.
- Scrubber servers are used to separate good traffic from malicious traffic to protect against DDoS attacks. Scrubber servers are typically only used when an attack is detected. Today, Scrubber servers are very sophisticated, allowing clients to push very fine-grained firewall rules and apply them across all data centers in real time.
- Proxy or edge proxy servers serve content to end users. They typically cache content and provide fast retrieval from RAM.
- The content distribution system is responsible for distributing content to all edge proxy servers in different CDN facilities. Typically a tree distribution model is used. More on that later in the video.
- An origin server is the user infrastructure that hosts original content distributed on a CDN.
- Data control systems are used to observe resource usage and statistics. This component measures metrics such as latency, downtime, packet loss, server load, and more. This is then fed back to the routing system for optimal routing.
Let's walk through the main workflow:
- We start with the origin server providing content delegation for a specific DNS domain or a specific DNS name. It tells the CDN that all requests to a specific URL will be proxied.
- The origin server publishes content to a distribution system, which is responsible for distributing the content across a set of edge proxy servers. Typically "push" and "pull" models are used, often both are used.
- The distribution system sends qualified content to proxy servers while keeping track of which content is cached on which proxy server. It also understands what content is static and dynamic, the TTL of data that needs to be refreshed, content leases, and more.
- The client requests the appropriate proxy server IP from the routing system, or uses Anycast IP to route to the nearest location.
- Client requests go through the Scrubber server.
- Scrubber servers forward good traffic to edge proxies.
- Edge proxy servers serve client requests and periodically forward their health information to the data control system. If content is not available in the proxy, it is routed to the origin server.
Now imagine that you have a single website that needs to distribute content to 20 regions, each with 20 proxies that need to be stored. 20 regions + 20 replicas, which means you need to transfer data to the CDN 400 times, which is very inefficient. To solve this problem, you can use a tree-like replication model.
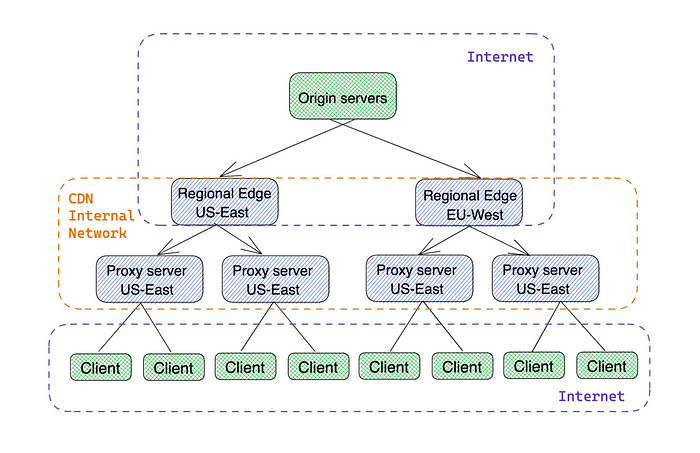
Tree content distribution
Data is sent to a regional edge proxy server and then replicated to sub-proxy servers in the same region using the CDN's internal network. This way, we only need to copy the content once per region or geographic area. Depending on the scale, a region can be a specific data center or a larger geographic area where we have two levels of parent proxy servers.
It is crucial for users to get their data from the nearest proxy server because the goal of a CDN is to reduce latency by moving data closer to the user. CDN companies generally use two routing models. The first one is based on DNS with load balancing and is historically the most popular. What I think is newer and more efficient is the Anycast model, which delegates routing and load balancing to the Internet's BGP protocol. Let's take a look at them.
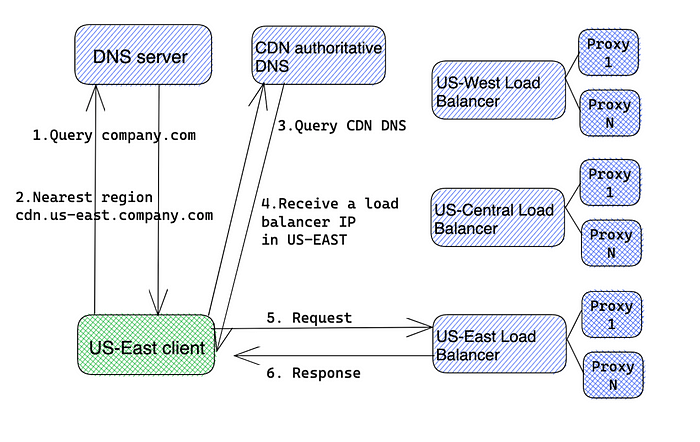
In a typical DNS resolution, we use the DNS system to obtain the IP corresponding to a human-readable name. In our case we will use DNS to return another DNS name to the client. This is called a DNS redirect and is used by content providers to send clients to a specific CDN zone. For example, if a client tries to resolve company.com, the authoritative DNS server provides another URL (such as cdn.us-east.company.com). The client performs another DNS resolution and obtains the IP address of the appropriate CDN proxy server in the US-East region. Depending on the user's location, the DNS response will be different.
Therefore, clients are first mapped to the appropriate datacenter based on the user's location. In the second step, it calls one of the load balancers to distribute the load across the proxy servers. To move customers from one zone to another, a DNS change must be made to remove the load balancer IP in the difficult zone. For this to work properly, the DNS TTL must be set to a minimum so that clients pick up changes as quickly as possible.
But there will still be some traffic passing through, and if that area fails, traffic will be affected. I discuss similar issues in another video about scalable API gateways and edge design. I'll put a link to the video in the description.
A more efficient approach is Anycast design.
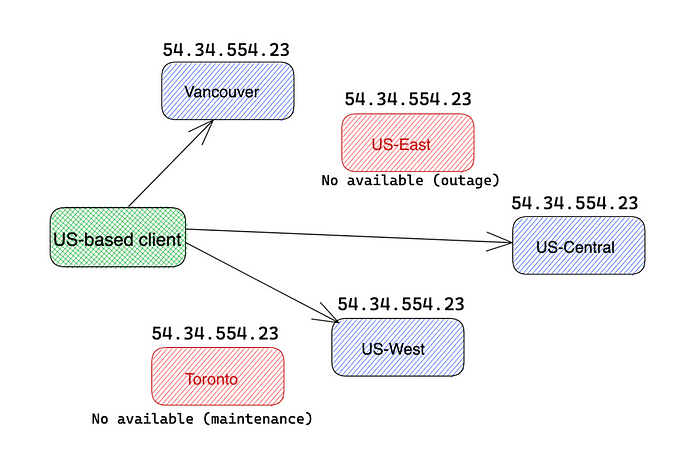
Anycast is a routing method where all edge servers located in multiple locations share the same single IP address. It utilizes the Border Gateway Protocol, or BGP, to route clients based on the natural network flow of the Internet. CDN uses the Anycast routing model to route Internet traffic to the nearest data center to ensure improved response times and prevent any data center from being affected by traffic overload in the event of special needs, such as DDoS attacks.
When a request is sent to an Anycast IP address, the router will direct it to the nearest machine on the network. If an entire data center fails or undergoes maintenance, the Anycast network can respond to the failure similar to how a load balancer distributes traffic across multiple servers or regions; data will be moved from the failed location to another that is still online and functioning properly. data center.
Anycast的可靠性
使用DNS和负载均衡器的Unicast IP使用单一机器,单一IP。大多数互联网都是通过Unicast路由模型工作的,其中网络上的每个节点都会获得一个唯一的IP地址。
Anycast是——许多机器,一个IP
虽然Unicast是运行网络的最简单方法,但不是唯一的方法。使用Anycast意味着网络可以非常有弹性。因为流量将找到最佳路径,我们可以将整个数据中心脱机,流量将自动流向下一个最近的数据中心。
Anycast的最后一个好处是它也可以帮助缓解DDoS攻击。在大多数DDoS攻击中,使用许多被攻陷的“僵尸”计算机来形成所谓的僵尸网络。这些机器可以分散在网络中,并生成大量流量,以至于它们可以淹没典型的Unicast连接的机器。Anycasted网络的性质在于,它在固有地增加了吸收此类攻击的表面积。分布式僵尸网络将其服务拒绝服务的流量的一部分吸收到每个具有容量的数据中心中。
现实世界中的例子是Cloudflare,它构建了一个遍布全球数百个地方的全球代理网络。它声称使他们与全球95%的互联网连接人口约相距50毫秒。由于网络也建立在Anycast IP上,它提供了总容量超过170 Tbps。这意味着他们不仅能为大量客户提供服务,还能通过将恶意流量分散到多个位置来处理最大的DDoS攻击。