CVPR 2024 | LiDAR diffusion model for photorealistic scene generation

Thesis idea:
Diffusion models (DMs) excel in photorealistic image synthesis, but adapting them to lidar scene generation faces significant challenges. This is mainly because DMs operating in point space have difficulty maintaining the curve pattern and three-dimensional geometric properties of lidar scenes, which consumes most of their representation capabilities. This paper proposes LiDAR diffusion models (LiDMs), which can generate realistic LiDAR scenes from a latent space tailored to capture the realism of LiDAR scenes by incorporating geometric priors into the learning process. The approach of this article addresses three main aspirations: authenticity of patterns, authenticity of geometry, and authenticity of objects. Specifically, this paper introduces curve compression to simulate real-world lidar patterns, point-wise coordinate supervision to learn scene geometry, and patch-wise encoding to obtain complete 3D object context. With these three core designs, this paper establishes a new SOTA in unconditional lidar-generated 64-line scenes while maintaining high efficiency (up to 107 times faster) compared to point-based DMs. Furthermore, by compressing lidar scenes into latent space, this paper enables DMs to be controlled under various conditions, such as semantic maps, camera views, and text prompts.
Main contributions:
This paper proposes a novel LiDAR Diffusion Model (LiDM), a generative model capable of realistic LiDAR scene generation based on arbitrary input conditions. To the best of our knowledge, this is the first method capable of generating lidar scenes from multimodal conditions.
This paper introduces curve-level compression to maintain realistic lidar patterns, point-level coordinate supervision to normalize the model for scene-level geometry, and block-level encoding to fully capture the context of 3D objects.
This paper introduces three metrics to comprehensively and quantitatively evaluate the quality of generated lidar scenes in perceptual space, comparing multiple representations including range images, sparse volumes, and point clouds.
The method in this paper achieves the state-of-the-art in unconditional scene synthesis of 64-line lidar scenes, and achieves a speed increase of up to 107 times compared to the point-based diffusion model.
Web design:
In recent years, there has been rapid development of conditional generative models that are capable of generating visually appealing and highly realistic images. Among these models, diffusion models (DMs) have become one of the most popular methods due to their impeccable performance. To achieve generation under arbitrary conditions, latent diffusion models (LDMs) [51] combine cross-attention mechanisms and convolutional autoencoders to generate high-resolution images. Its subsequent extensions (e.g., Stable Diffusion [2], Midjourney [1], ControlNet [72]) further enhanced its potential for conditional image synthesis.
This success triggered the thinking of this paper: Can we apply controllable diffusion models (DMs) to lidar scene generation in autonomous driving and robotics? For example, given a set of bounding boxes, can these models synthesize corresponding lidar scenes, thereby converting these bounding boxes into high-quality and expensive annotation data? Alternatively, is it possible to generate a 3D scene from just a set of images? Even more ambitiously, could we design a language-driven lidar generator for controlled simulation? To answer these intertwined questions, the goal of this paper is to design a diffusion model that can combine multiple conditions (e.g., layout, camera view, text) to generate realistic lidar scenes.
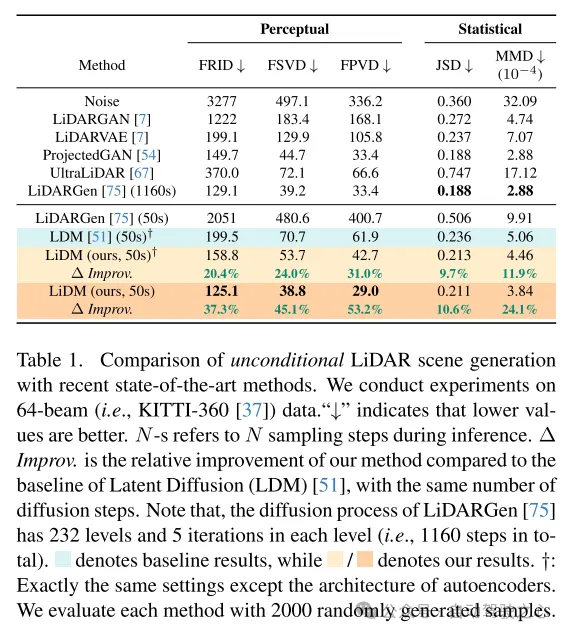
To this end, this paper draws some insights from recent work on diffusion models (DMs) in the field of autonomous driving. In [75], a point-based diffusion model (i.e., LiDARGen) is introduced for unconditional lidar scene generation. However, this model often produces noisy backgrounds (e.g. roads, walls) and blurry objects (e.g. cars), resulting in generated lidar scenes that are far from reality (see Figure 1). Additionally, spreading points without any compression makes the inference process computationally slower. Moreover, directly applying patch-based diffusion models (i.e., Latent Diffusion [51]) to lidar scene generation fails to achieve satisfactory performance, both qualitatively and quantitatively (see Figure 1).
为了实现条件化的逼真激光雷达场景生成,本文提出了一种基于曲线的生成器,称为激光雷达扩散模型(LiDMs),以回答上述问题并解决近期工作中的不足。LiDMs 能够处理任意条件,例如边界框、相机图像和语义地图。LiDMs 利用距离图像作为激光雷达场景的表征,这在各种下游任务中非常普遍,如检测[34, 43]、语义分割[44, 66]以及生成[75]。这一选择是基于距离图像与点云之间可逆且无损的转换,以及从高度优化的二维卷积操作中获得的显著优势。为了在扩散过程中把握激光雷达场景的语义和概念本质,本文的方法在扩散过程之前,将激光雷达场景的编码点转换到一个感知等效的隐空间(perceptually equivalent latent space)中。
To further improve the realistic simulation of real-world lidar data, this paper focuses on three key components: pattern realism, geometric realism, and object realism. First, this paper utilizes curve compression to maintain the curve pattern of points during automatic encoding, which is inspired by [59]. Secondly, in order to achieve geometric authenticity, this paper introduces point-level coordinate supervision to teach our autoencoder to understand the scene-level geometric structure. Finally, we expand the receptive field by adding additional block-level downsampling strategies to capture the complete context of visually larger objects. Enhanced by these proposed modules, the resulting perceptual space enables the diffusion model to efficiently synthesize high-quality lidar scenes (see Figure 1) while also performing well in terms of speed compared to point-based diffusion models. 107x (evaluated on an NVIDIA RTX 3090) and supports any type of image-based and token-based conditions.

Figure 1. Our method (LiDM) establishes a new state-of-the-art in unconditional LiDAR realistic scene generation and marks a milestone in the direction of generating conditional LiDAR scenes from different input modalities.
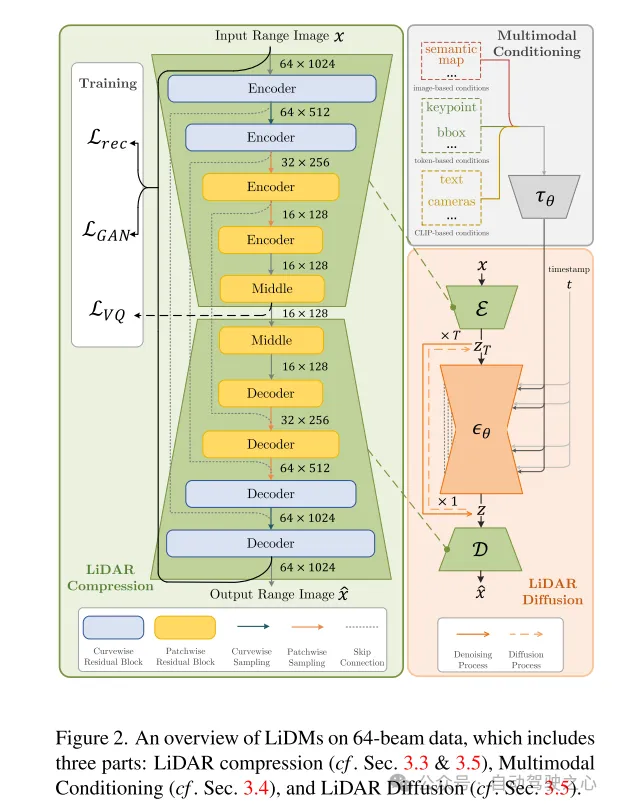
Figure 2. Overview of LiDMs on 64-line data, including three parts: LiDAR compression (see Sections 3.3 and 3.5), multimodal conditioning (see Section 3.4), and LiDAR diffusion (see Section 3.5) .
Experimental results:

Figure 3. Examples of LiDMs from LiDARGen [75], Latent Diffusion [51] and this paper in the 64-line scenario.

Figure 4. Example of LiDMs from this paper in a 32-line scenario.
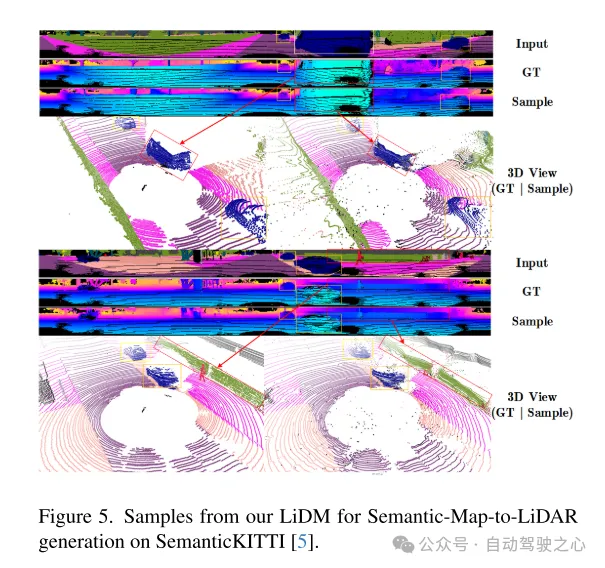
Figure 5. Example of our LiDM for semantic map-to-lidar generation on the SemanticKITTI [5] dataset.
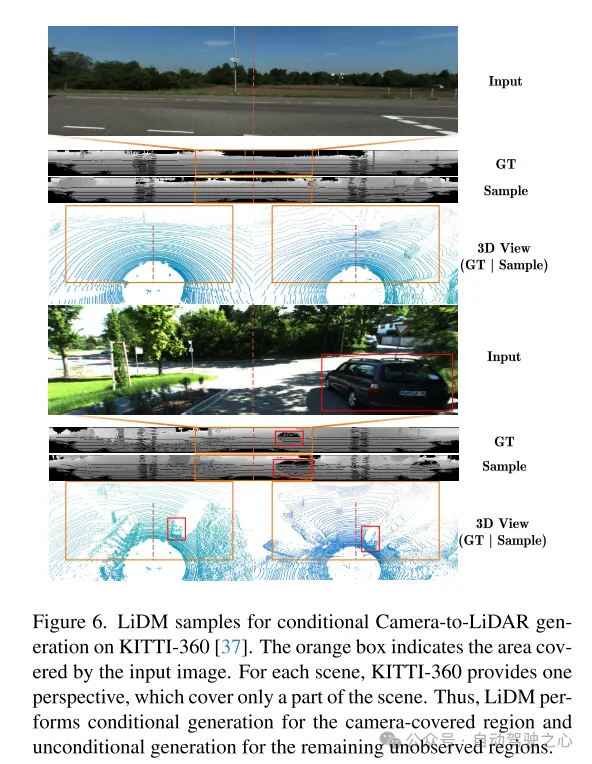
Figure 6. Example of LiDM for conditional camera-to-lidar generation on the KITTI-360 [37] dataset. The orange box indicates the area covered by the input image. For each scene, KITTI-360 provides a perspective that covers only part of the scene. Therefore, LiDM performs conditional generation on the areas covered by the camera and unconditional generation on the remaining unobserved areas.
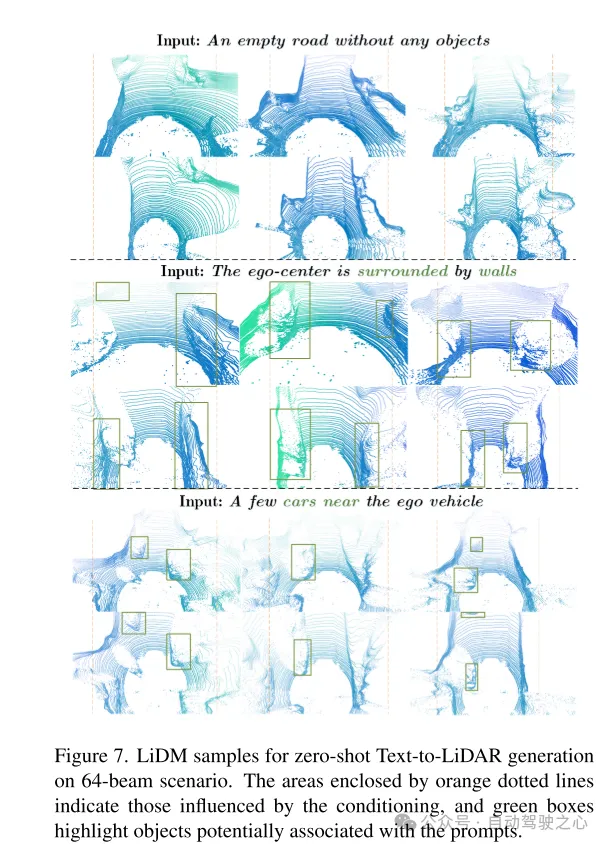
Figure 7. Example of LiDM for zero-shot text-to-lidar generation in a 64-line scenario. The area framed by the orange dashed line represents the area affected by the condition, and the green box highlights objects that may be associated with the cue word.
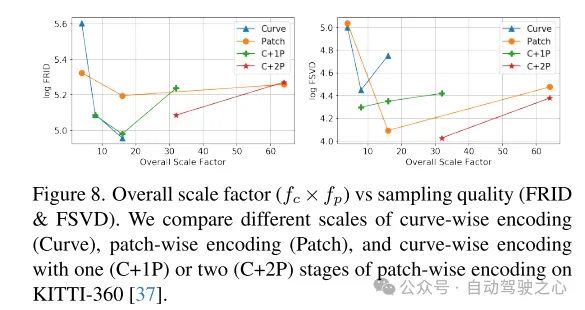
Figure 8. Overall scaling factor ( ) versus sampling quality (FRID and FSVD). This paper compares curve-level coding (Curve), block-level coding (Patch), and curves with one (C+1P) or two (C+2P) stages of block-level coding at different scales on the KITTI-360 [37] dataset. level encoding.
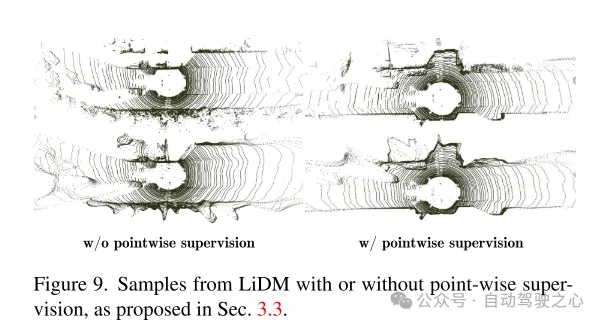
Figure 9. Examples of LiDM with and without point-level supervision, as proposed in Section 3.3.


Summarize:
This paper proposes LiDAR Diffusion Models (LiDMs), a general conditional framework for LiDAR scene generation. The design of this article focuses on retaining the curved pattern and the geometric structure of the scene level and object level, and designs an efficient latent space for the diffusion model to achieve realistic generation of lidar. This design enables the LiDMs in this paper to achieve competitive performance in unconditional generation in a 64-line scenario, and reach the state-of-the-art level in conditional generation. LiDMs can be controlled using a variety of conditions, including semantic maps, Camera view and text prompts. To the best of our knowledge, our method is the first to successfully introduce conditions into lidar generation.