When "software-defined cars" encounter software performance issues
2024.06.19

Author: Zhang Xuhai
Compared with cars a few years ago, although the main purpose of today's cars as vehicles has not changed much, there has been a qualitative leap in driving experience, intelligence level and interaction methods.
In order to support the level of intelligent services provided by the new generation of cars, it is obvious that:
The software platform and the hardware platform need to be separated and abstracted from each other to improve flexibility.
This design approach, called Software Defined Vehicle (SDV), uses more flexible and easily scalable software as the core of the car, upgrading traditional cars into a "third space" with capabilities such as intelligent driving, deep entertainment, and personalized human-computer interaction.
SDV has brought about a series of revolutionary leaps in automotive design, but it has also introduced a variety of new difficulties. Long-standing cross-domain and cross-business challenges in the software field, such as performance, reliability, safety, and ease of use, have been introduced into the automotive field along with SDV.

1. Why is it difficult for car companies to improve software performance
"Car computer freeze" failures always have a place on the car complaint list. In addition to affecting the driving experience, performance problems can even cause danger in some cases. For example, the freeze of the navigation system can seriously interfere with the driver's decision-making.
Since both the automotive industry and the software industry have been developing for many years, why is it difficult for car companies to improve software performance after software defines cars?
1. Inevitable Intrinsic Complexity
There is nothing new in the software field. From monolithic to distributed, from multi-tasking to multi-instance, the challenges faced by the software field are always accompanied by the development of business and organizational forms.
All problems stem from complexity. Just like scalability and performance, as the scale of software increases, poor scalability will reduce R&D efficiency, while the layers of abstraction required by scalability will become a constraint on software performance design.
Due to the flexibility of the software architecture, its functional structure is very easy to modify and expand, which makes it seem that the scale of the software can be expanded without limit. However, the cognitive boundary of the human brain leads to the expansion of the scale of software, which also means the expansion of the scale of collaboration. This large-scale software collaboration system increases the complexity of the software exponentially.
Any software that scales is susceptible to two types of inherent complexity:
- Obscurity: The process of software development can be seen as a process of knowledge transfer and conversion. The domain knowledge of large-scale software is not mastered by any single individual, and the more complex division of labor also causes distortion in the process of knowledge transfer. If not managed, this obscurity will eventually make the entire software system incomprehensible.
- Dependency: Large-scale software usually contains a very complex hierarchical structure, and its modules and components are interdependent through various forms of interface coupling to form a whole. However, this dependency is cascading in most cases. If it is not handled properly, the modification of a marginal component may suddenly cause other seemingly unrelated components to fail.
Not surprisingly, in order to realize various high-level intelligent features, the SDV-driven automotive software system meets all the characteristics of a complex software system.
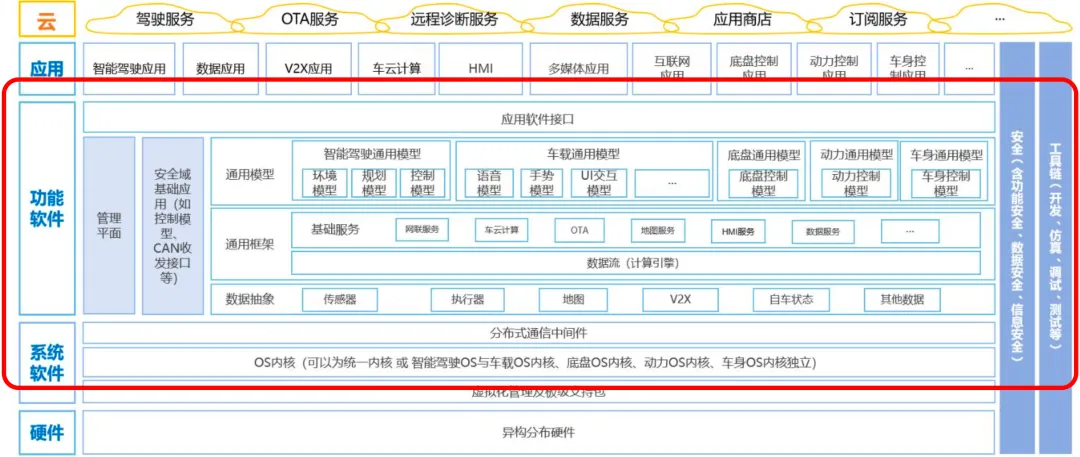
Source: Intelligent Connected Vehicle Electronic and Electrical Architecture Industry Technology Roadmap
Taking the functional architecture of automotive software shown in the figure above as an example, the architecture of automotive software is characterized by complex business, deep technology stack, and high security requirements. Compared with the software and hardware architecture of other industries such as mobile phone manufacturing and Internet platforms, the degree of standardization of automotive software in each architectural level is lower, and there are more customized R&D scenarios, and various suppliers in the entire automotive industry chain are emerging in an endless stream.
The above situation determines that the business interaction, architecture design and team collaboration in the process of automotive software development are complex.
2. Performance is an architectural feature that spans the entire software business and life cycle
Architecture Characteristics are software characteristics that architects need to consider when designing software that are not related to domain or business requirements, such as auditability, performance, security, scalability, reliability, etc. In many cases, we also call them non-functional requirements or quality attributes.
In ISO/IEC 25010:2011, performance efficiency is a key architectural characteristic in the software quality model, which describes performance efficiency more specifically as the "time characteristics", "resource utilization" and "capacity" of the software.
Obviously, software performance is a common architectural feature that spans the business and software life cycle. The quality of software performance determines customers' willingness to use it in many key business scenarios. In order to build a high-performance software system, performance needs to be considered from the beginning of software design.
When performance characteristics need to span complex automotive software systems, three types of challenges arise: across technical areas, across business areas, and across teams.
Take the navigation function as an example: as a critical application in the car, if there are problems such as lag, freeze, and exit, it will seriously affect the user's driving experience. Therefore, in order to ensure the smoothness of navigation, more system resources and a more stable operating environment are required during operation.
Fast operation response requires a higher scheduling priority for the navigation process. Continuous map reading requires short IO queue time. Screen rendering involves third-party libraries such as Unity3D and GPU resources. In addition, some auxiliary functions in navigation such as AI voice and screen sharing require the ability to call other components.
Therefore, for the key function of navigation, if a performance failure is found, the process of locating and optimizing it may involve multiple business areas and multiple technical layers including the application layer, middleware layer, and system layer. In addition, it may also involve many issues such as information security, experience consistency, and system reliability.
2. Engineering methods for continuous performance improvement
As a cross-domain architectural feature in a complex software environment, performance optimization work can easily fall into a cycle of "poor performance -> problem delay -> intermittent optimization -> degradation again".
We hope to manage and operate software performance through an engineering approach to achieve continuous performance protection and improvement.
Engineering methods generally refer to improving the efficiency and quality of projects through scientific methods and standardized processes. Therefore, for a topic like "performance optimization", engineering can be achieved through the following five practices, namely performance engineering.
- Systematic methodology: A systematic approach to performance optimization. You can refer to performance analysis and optimization methodologies such as "Peak Performance".
- Standardized processes and specifications: Define standardized processes such as performance modeling and automation methods (such as fitness functions) to improve efficiency.
- Mature technical support: required knowledge, technical capabilities and talents, among which domain experts, performance experts and engineering experts are critical.
- Full life cycle management: Similar to the DevOps approach, performance optimization activities throughout the software life cycle are defined.
- Continuous improvement: Keep performance optimization practices running continuously through continuous observation, continuous care, etc.
For more details on performance engineering, see What is Performance Engineering ?
The following article will introduce the implementation of the five aspects of the above engineering methods in SDV R&D from the three perspectives of performance observation, performance tuning, and performance team.
1. Continuous performance observation
The premise of performance optimization is to be able to objectively evaluate performance. By building the ability to observe the system, we can understand the current status of the system as much as possible, thereby providing an evaluation basis for subsequent performance care and optimization.
(1) Establishing an evaluation model
As one of the outputs of performance modeling activities, the performance evaluation model can be started at the beginning of system construction. At the same time, the evaluation model also needs to incorporate more business and technical indicators as the product is continuously iterated to accurately describe the system performance requirements.
The indicator model can generally be divided into business indicators, system indicators and resource indicators.
- Business indicators are more like black box indicators, describing product performance characteristics from the perspective closest to user usage.
- System indicators are closer to white box indicators, describing the internal state of the system during operation, and they will indirectly affect business indicators.
- Resource indicators are a supplement to the first two indicators. It is meaningless to evaluate resource indicators independently, but they can more accurately describe the system status when combined with other indicators.

The most difficult part of trying to implement continuous performance optimization is to establish an evaluation model, because the evaluation model represents the performance target. (For the establishment of the evaluation model, please refer to "Evaluation and Improvement of Intelligent Cockpit Software Performance and Reliability")
If the evaluation model is designed with deviations, it is easy to spend a lot of time to build a model without including key performance points. Optimization iteration based on such a model will give the team an illusion that the observation system that has been built with great effort is useless, because even if the observed indicators are improving, the system performance still seems to be poor.
This in turn will make the team doubt: Is performance observation related to performance optimization? In this self-doubt, the work of the performance team can easily fall into some anti-patterns mentioned in "Peak Performance", such as street lamp fraud method or random change fraud method.
(2) Customized and scalable observation tools
In order to effectively evaluate the system, observation tools are essential. Most of the indicators in the evaluation model can be collected through existing tools. In order to better discover problems, there are also many tracking tools in the industry that can analyze the system.
Therefore, the main goal of establishing an observation system is to integrate various scattered observation tools to form a complete and easy-to-use system performance observation capability. In addition to traditional tool integration, the customizability and cost of the observation system are also worthy of attention.
The simplest observation system can be divided into a probe front-end on the device and an analysis back-end on the host computer or server. Since the probe runs directly on the device, the overhead of the probe itself cannot be ignored. Therefore, performance probes usually include fine-grained configuration capabilities. In the R&D or testing phase, all or most switches are turned on, while in the production operation phase, only some low-overhead information collection functions are turned on.
In order to expand the system-level observation capabilities of the probe, observing kernel behavior through eBPF is a safe and efficient way. Based on eBPF, customized observations of scheduling, memory, IO, and network can be easily performed.
In addition to the overhead, during the production phase, it is also necessary to consider data privacy compliance and network traffic restrictions. Therefore, data desensitization, encryption, and compression should also be important design considerations.
(3) Performance care
After having the evaluation model, by establishing the system's performance baseline through the model, it is possible to continuously evaluate whether the system's performance is optimized or degraded during the system iteration process.
As we can see from the previous article, the evaluation model contains a set of indicators used to describe the characteristics of different systems, so the actual performance baseline established is a set of indicator vectors. Obviously, the establishment of a performance indicator baseline requires repeated and extensive performance testing of the system, and then taking the statistical value as the baseline is of evaluation value.
Whether it is to establish a performance baseline or to perform performance monitoring based on two different sets of indicator vectors, some basic statistical methods should be used to make the evaluation and monitoring more objective.
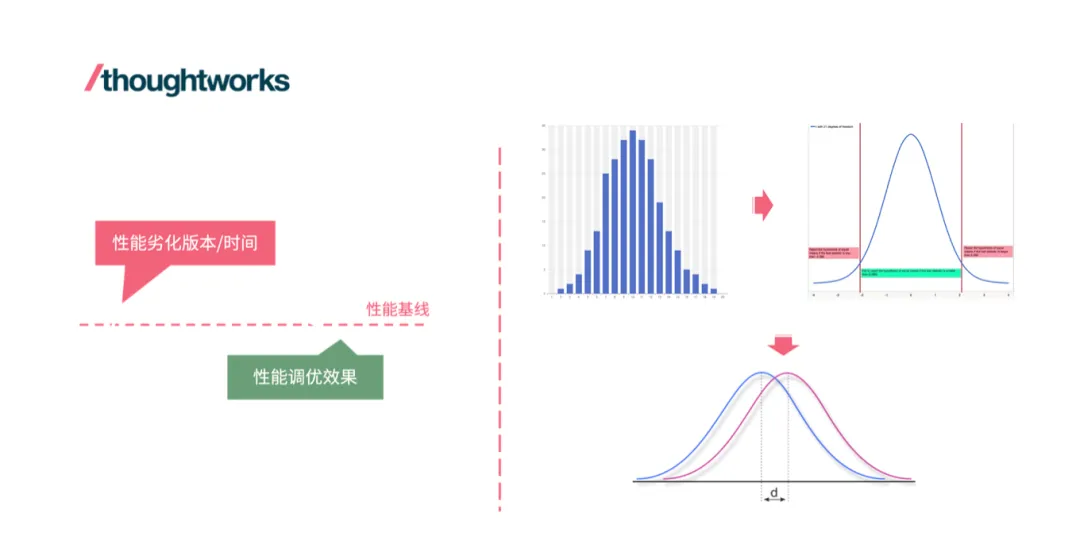
First, the collected indicator samples need to be tested for normality. If the indicator samples do not conform to the normal distribution, it is necessary to correct the sample data or investigate whether there is skewness in the sampling process. Samples that conform to the normal distribution are the prerequisite for further statistical comparison.
2. Continuous performance improvement
After discovering performance problems, how to improve and continuously improve performance becomes the top priority.
(1) TopDown analysis and problem modeling
Generally speaking, performance problems are caused by business phenomena or abnormal black box indicators. The characteristic of such problems is that the underlying causes are often covered by various complex noises. When encountering such problems, the first idea that comes to mind is random trial and error. At this time, we will extremely believe in the first possible cause that comes to our mind and have a strong urge to give it a try.
However, random trial and error is not only one-sided, but also inefficient. A more scientific analysis method is to model the problem, define the problem more accurately from the perspective of load and resources, and then perform a top-down analysis based on the architecture of the system under test, and use objective testing methods to verify the hypothesis after making it.
Here is a simple example of problem modeling. The system is considered by the test users to be not smooth. Before analyzing the problem, we first need to define the problem clearly: What is the load like when the system is not smooth? Frame rate is a black box indicator that can describe the rendering load of the system. If it is lower than the normal value, it indicates that there is a high load in the rendering process. Otherwise, it is necessary to further investigate the completion time of each business stage. In addition, what are the resources like when the system is not smooth? Analyzing the contention of hardware resources (CPU, memory, disk) and software resources (locks, threads, connections) can further describe the state of the system.
(2) Building microbenchmarks
After modeling the performance problem, possible optimization paths may have gradually become clear, but before trying to implement the optimization, it is also necessary to design relevant micro-benchmarks. Compared with business phenomena or black box indicators that reveal performance problems, micro-benchmarks can test the system from a more fine-grained direction. It eliminates irrelevant noise interference and can focus on testing the indicators affected by the performance optimization points.
For example, when optimizing the stuttering problem of foreground applications, after modeling and analysis, we assume that the cause of the stuttering may be that when the system load is high, the rendering thread is difficult to be scheduled to the CPU in time, resulting in untimely rendering. So for this assumption, we need to build a set of benchmarks, including a load generator that can impose a certain degree of load on the system to meet the test conditions. It also includes a tool that can detect and record application scheduling delays. Then, through a test script, while generating load, run the application under test, and after the test is completed, the scheduling delay changes in the process can be printed. Based on such a set of micro-benchmarks, the degree of optimization of the foreground application scheduling delay can be tested relatively independently.
(3) Optimization drive model iteration
In performance optimization work, we must recognize the iterative nature of software. With the continuous iteration and update of software, the effect of the originally available optimization methods may gradually deteriorate or even become ineffective. Therefore, the care of the optimization itself is also critical.
For example, IO pre-reading is a method to shorten the system startup time by combining a small number of multiple IO operations during the startup process to reduce the overall overhead, thereby achieving the purpose of shortening the time. However, pre-reading optimization requires that the files actually read and written by all codes during the startup process can be known in advance. This information is bound to change with software iterations, so the pre-read content also needs to be updated to ensure effectiveness.
In order to promptly detect the weakening of the optimization effect, we can extract the relevant detection items based on the optimization itself and incorporate them into the evaluation model as white box indicators. It is best to automatically evaluate them through the corresponding fitness function. Back to the example of pre-reading, in order to make the pre-reading content keep up with the changes in the software itself, we can build an automated fitness function:
After each new version is released, it is automatically executed once to obtain the read and write file list of the startup process, and compare it with the optimized file list (this is the baseline). If the difference is greater than 30%, an alarm will be issued.
In this way, the effectiveness of the optimization can be continuously ensured and no manual intervention is required once established.
3. Performance Engineering Team
For the performance engineering methods mentioned above, it is difficult to take root in the organization without a professional team to promote them. As mentioned in the five engineering practices, mature technical support is essential.
To build performance engineering, it is necessary to form a professional team that includes domain experts, performance experts, and engineering experts.
In Team Topologies, Matthew Skelton and Manuel Pais describe four basic types of teams:
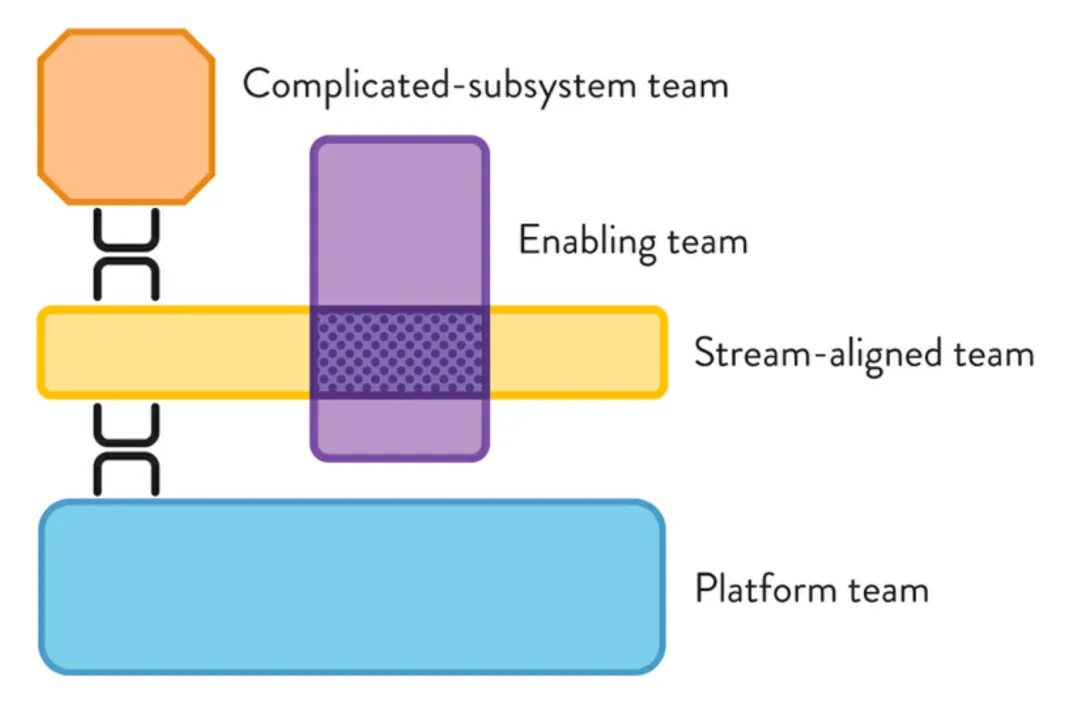
Image source: Organizing Agile Teams and ARTs: Team Topologies at Scale
- Business Stream Team: An end-to-end delivery team that matches business domain and organizational capabilities.
- Empowerment team: Experts in specific technical or product areas empower the business flow team.
- Complex Subsystem Teams: Build and maintain subsystems within the system that rely heavily on specialized domain knowledge.
- Platform team: Builds basic capabilities to provide self-service for product-oriented teams.
Interestingly, in the practice of performance engineering, we found that the performance engineering team is a combination of three types of teams: "enablement", "complex subsystem" and "platform":
- The performance engineering team is an enabling team when it is responsible for assisting the business flow team in diagnosing and optimizing the performance of specific products or components;
- When implementing performance optimization at the system level, the performance engineering team becomes a complex subsystem team;
- When building platform capabilities such as performance modeling and performance observation, the performance engineering team becomes a platform team.
The ability to effectively undertake the above job responsibilities is closely related to the composition of the team itself.
In the context of SDV, domain experts need to be familiar with the business composition and performance requirements of the vehicle system in different scenarios. The business indicators in the performance evaluation model are also mostly given by domain experts based on business experience. Domain experts do not necessarily work in the performance engineering team for a long time. They may be technical architects, business analysts or product managers, but the cross-domain ability to combine business and performance is very critical.
Performance experts are well versed in the various principles, methods, and practices of performance observation and performance optimization, and they also need to be familiar with the entire system architecture. In the vehicle software architecture, due to the different real-time requirements of different functional domains, virtualization technology is usually used to run multiple systems on the same hardware platform. The resource abstraction and isolation generated by virtualization will have a great impact on performance optimization. For example, if performance experts do not understand the abstraction of computing resources by the virtualization layer, blindly performing optimizations such as large and small cores and frequency modulation in the Guest system may not be effective and may also lead to unknown behaviors.
Engineering experts are mainly involved in optimization implementation, platform construction, and empowerment of business teams. Engineering experts are experienced engineers. Troubleshooting performance failures of business teams requires them to be familiar with Android, Linux, or AUTOSAR development; building observation systems and platform capabilities requires them to be familiar with data engineering, network communications, cloud native services, etc. R&D-related capabilities including compilation tool chains, DevOps, and test tool development are also indispensable.
Of course, it is not easy to build such a "hexagonal" team in one step, but as long as the organization tries to start building performance engineering, I believe that the initially incompetent team will eventually become a competent team as the maturity of performance engineering continues to improve.
Summarize
In conclusion, due to the huge functional differences between smart connected cars and traditional cars, the concept of software-defined cars is imperative for flexibility and iteration speed. However, the two essential complexities of software, obscurity and dependency, and the cross-domain characteristics of performance itself make it difficult for car companies to do a good job in software performance.
We try to continuously improve the performance of automotive software through engineering means, which includes the following practices:
- Build system observation capabilities, understand the current status of the system, and provide an evaluation basis for performance maintenance and optimization.
- Continuously optimize the performance of the software system through analytical modeling, test verification, and iterative optimization.
- Establish a performance engineering team to professionally solve performance problems, empower business teams and build platforms.
We are still continuously exploring and practicing software performance engineering. We hope this article can help you.