可控影像生成最新綜述!北郵開源20頁249篇文獻,包辦Text-to-Image Diffusion領域各種「條件」
2024.03.19

在視覺生成領域迅速發展的過程中,擴散模型已經徹底改變了這一領域的格局,透過其令人印象深刻的文本引導生成功能標誌著能力方面的重大轉變。
然而,僅依賴文字來調節這些模型並不能完全滿足不同應用和場景的多樣化和複雜需求。
鑑於這種不足,許多研究旨在控制預訓練文字到圖像(T2I)模型以支持新條件。
在這篇綜述中,來自北京郵電大學的研究人員對具有T2I 擴散模型可控性生成的文獻進行了徹底審查,涵蓋了該領域內理論基礎和實際進展。

論文:https://arxiv.org/abs/2403.04279程式碼:https://github.com/PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models
我們的回顧從簡要介紹去噪擴散機率模型(DDPMs)和廣泛使用的T2I 擴散模型基礎開始。
然後我們揭示了擴散模型的控制機制,並從理論上分析如何將新條件引入去雜訊過程以進行有條件生成。
此外,我們提供了對該領域研究情況詳盡概述,並根據條件角度將其組織為不同類別:具有特定條件生成、具有多個條件生成以及通用可控性生成。
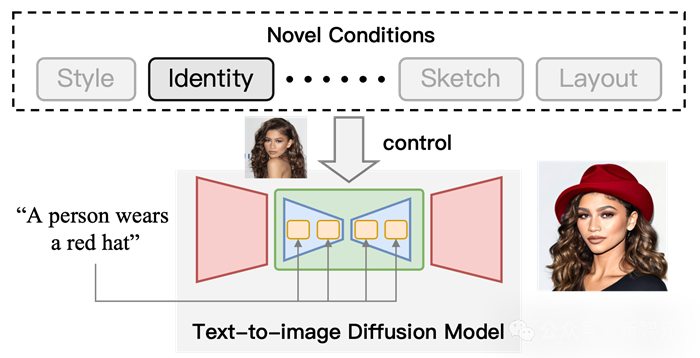
圖1 利用T2I擴散模型可控生成示意圖。在文字條件的基礎上,加入「身份」條件來控制輸出的結果。
分類體系
利用文本擴散模型進行條件生成的任務代表了一個多面向和複雜的領域。從條件角度來看,我們將這個任務分成三個子任務(參見圖2)。
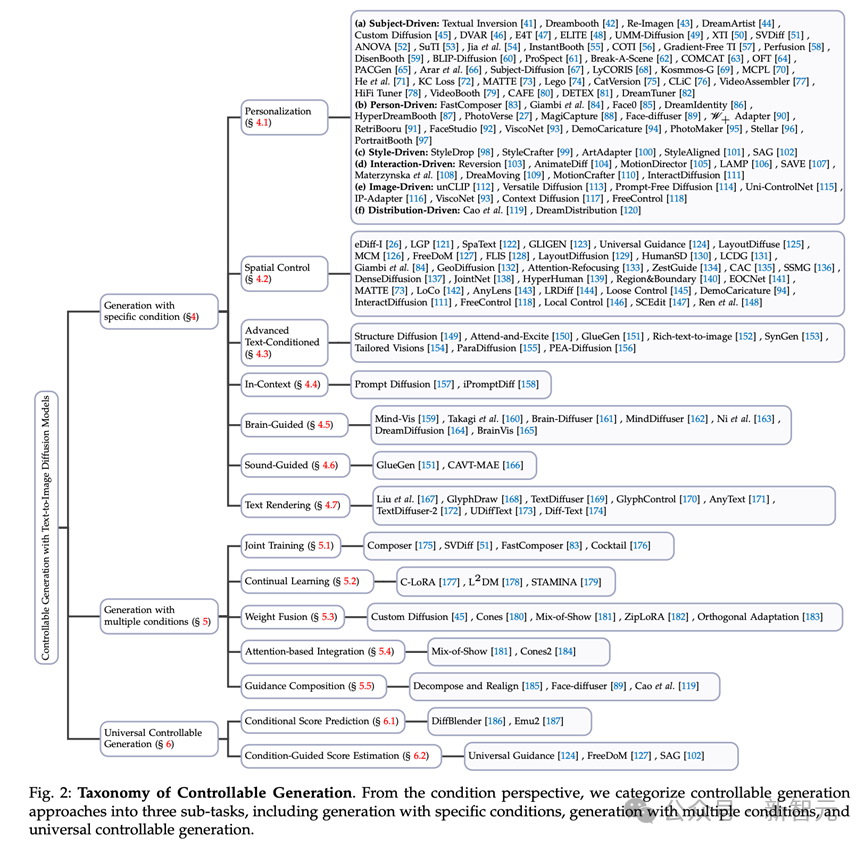
圖2 可控制生成的分類。從條件角度來看,我們將可控生成方法分為三個子任務,包括具有特定條件的生成、具有多個條件的生成和通用可控生成。
大多數研究致力於如何在特定條件下生成圖像,例如基於圖像引導的生成和草圖到圖像的生成。
為了揭示這些方法的理論和特徵,我們根據它們的條件類型進一步對其進行分類。
1. 利用特定條件生成:指引入了特定類型條件的方法,既包括定制的條件(Personalization, eg, DreamBooth, Textual Inversion),也包含比較直接的條件,例如ControlNet系列、生理信號-to-Image
2. 多條件生成:利用多個條件進行生成,對這項任務我們在技術的角度對其進行細分。
3. 統一可控生成:這個任務旨在能夠利用任意條件(甚至任意數量)進行生成。
如何在T2I擴散模型中引入新的條件
細節請參考論文原文,以下對這些方法機制進行簡單介紹。
條件分數預測(Conditional Score Prediction)
在T2I擴散模型中,利用可訓練模型(例如UNet)來預測去雜訊過程中的機率分數(即雜訊)是一種基本且有效的方法。
在基於條件得分預測方法中,新穎條件會作為預測模型的輸入,直接預測新的得分。

其可劃分三種引入新條件的方法:
1. 基於模型的條件分數預測:這類方法會引入一個用來編碼新穎條件的模型,並將編碼特徵作為UNet的輸入(如作用在cross-attention層),來預測新穎條件下的得分結果;
2. 基於微調的條件分數預測:這類方法不使用一個顯式的條件,而是微調文字嵌入和去噪網路的參數,來使其學習新穎條件的信息,從而利用微調後的權重來實現可控生成。例如DreamBooth和Textual Inversion就是這類做法。
3. 無需訓練的條件分數預測:這類方法無需對模型進行訓練,可以直接將條件作用於模型的預測環節,例如在Layout-to-Image(佈局圖像生成)任務中,可以直接修改cross-attention層的attention map來實現設定物體的佈局。
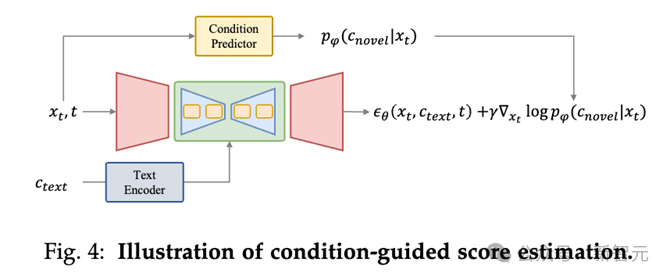
條件引導的得分評估
條件導引估計的得分估計方法是透過條件預測模型(如上圖Condition Predictor)反傳梯度來在去噪過程中增加條件指導。
利用特定條件生成

1. Personalization(客製化):客製化任務旨在捕捉和利用概念作為生成條件行可控生成,這些條件不容易透過文字描述,需要從範例圖像中進行提取。如DreamBooth,Texutal Inversion和LoRA。
2. Spatial Control(空間控制):由於文字很難表示結構訊息,即位置和密集標籤,因此使用空間訊號控製文字到圖像擴散方法是一個重要的研究領域,例如佈局、人體姿勢、人體解析。方法例如ControlNet。
3. Advanced Text-Conditioned Generation(增強的文本條件生成):儘管文本在文本到圖像擴散模型中起著基礎條件的作用,但該領域仍存在一些挑戰。
首先,在涉及多個主題或豐富描述的複雜文字中進行文字引導合成時,通常會遇到文字不對齊的問題。此外,這些模型主要在英語資料集上訓練,導致了多語言生成能力明顯不足。為解決這一限制,許多工作提出了旨在擴大這些模型語言範圍的創新方法。
4. In-Context Generation(上下文生成):在上下文生成任務中,根據一對特定任務範例圖像和文字指導,在新的查詢圖像上理解並執行特定任務。
5. Brain-Guided Generation(腦訊號引導產生):腦訊號引導產生任務專注於直接從大腦活動控製影像創建,例如腦電圖(EEG)記錄和功能性磁振造影(fMRI)。
6. Sound-Guided Generation(聲音引導產生):以聲音為條件產生相符的影像。
7. Text Rendering(文字渲染):在圖像中產生文本,可以廣泛地應用到海報、資料封面、表情符號等應用場景。
多條件生成

多條件生成任務旨在根據多種條件生成圖像,例如在用戶定義的姿勢下生成特定人物或以三種個人化身份生成人物。
在本節中,我們從技術角度對這些方法進行了全面概述,並將它們分類以下類別:
1. Joint Training(聯合訓練):在訓練階段就引入多個條件進行聯合訓練。
2. Continual Learning(持續學習):有順序的學習多個條件,在學習新條件的同時不遺忘舊的條件,以實現多條件生成。
3. Weight Fusion(權重融合):以不同條件微調得到的參數進行權重融合,以使模型同時具備多個條件下的生成。
4. Attention-based Integration(基於注意力的整合):透過attention map設定多個條件(通常為物體)在影像中的位置,以實現多條件生成。
通用條件生成
除了針對特定類型條件量身定制的方法之外,還存在旨在適應影像生成中任意條件的通用方法。
這些方法根據它們的理論基礎被廣泛分類為兩組:通用條件分數預測框架和通用條件引導分數估計。
1. 通用條件分數預測框架:通用條件分數預測框架透過創建一個能夠編碼任何給定條件並利用它們來預測影像合成過程中每個時間步的雜訊的框架。
這種方法提供了一種通用解決方案,可以靈活地適應各種條件。透過直接將條件資訊整合到生成模型中,該方法允許根據各種條件動態調整影像生成過程,使其多才多藝且適用於各種影像合成場景。
2. 通用條件引導分數估計:其他方法利用條件引導的分數估計將各種條件納入文字到影像擴散模型中。主要挑戰在於去噪過程中從潛在變數獲得特定條件的指導。
應用
引入新穎條件可以在多個任務中發揮用處,其中包括影像編輯、影像補全、影像組合、文/圖生成3D。
例如,在影像編輯中,可以利用客製化方法,將圖中出現貓編輯為特具有定身份的貓。其他內容請參考論文。
總結
這篇綜述深入探討了文本到圖像擴散模型的條件生成領域,揭示了融入文本引導生成過程中的新穎條件。
首先,作者為讀者提供基礎知識,介紹去噪擴散機率模型、著名的文本到圖像擴散模型以及一個結構良好的分類法。隨後,作者揭示了將新穎條件引入T2I擴散模型的機制。
然後,作者總結了先前的條件生成方法,並從理論基礎、技術進展和解決方案策略等方面對它們進行分析。
此外,作者探索可控生成的實際應用,在AI內容生成時代強調其在其中發揮重要作用和巨大潛力。
這項調查旨在全面了解目前可控T2I生成領域的現狀,從而促進這一充滿活力研究領域持續演變和拓展。
責任編輯:張燕妮來源: 新智元