如何探索和視覺化用於影像中物體檢測的ML 數據
2024.02.17

本文介紹如何使用Renumics Spotlight,來建立互動式的物件偵測視覺化。預訓練模型和Spotlight 等工具的使用,可以讓我們的物件偵測視覺化過程變得更加容易,進而增強資料科學的工作流程。
近年來,人們越來越認識到深入理解機器學習資料(ML-data)的必要性。不過,鑑於檢測大型資料集往往需要耗費大量人力物力,它在電腦視覺(computer vision)領域的廣泛應用,尚有待進一步開發。
通常,在物體偵測(Object Detection,屬於電腦視覺的子集)中,透過定義邊界框,來定位影像中的物體,不僅可以辨識物體,還能夠了解物體的上下文、大小、以及與場景中其他元素的關係。同時,針對類別的分佈、物體大小的多樣性、以及類別出現的常見環境進行全面了解,也有助於在評估和調試中發現訓練模型中的錯誤模式,從而更有針對性地選擇額外的訓練數據。
在實踐中,我往往會採取以下方法:
- 利用預先訓練的模型或基礎模型的增強功能,為資料添加結構。例如:建立各種影像嵌入,並採用 t-SNE 或 UMAP 等降維技術。這些都可以產生相似性的地圖,從而方便數據的瀏覽。此外,使用預先訓練的模型進行偵測,也可以方便地擷取情境。
- 使用能夠將此類結構與原始資料的統計和審查功能整合在一起的視覺化工具。
下面,我將介紹如何使用Renumics Spotlight,來建立互動式的物件偵測視覺化。作為示例,我將試著:
- 為影像中的人物探測器建立視覺化。
- 視覺化包括相似性地圖、篩選器和統計數據,以便瀏覽數據。
- 透過地面實況(Ground Truth)和 Ultralytics YOLOv8 的檢測詳細,查看每一張影像。
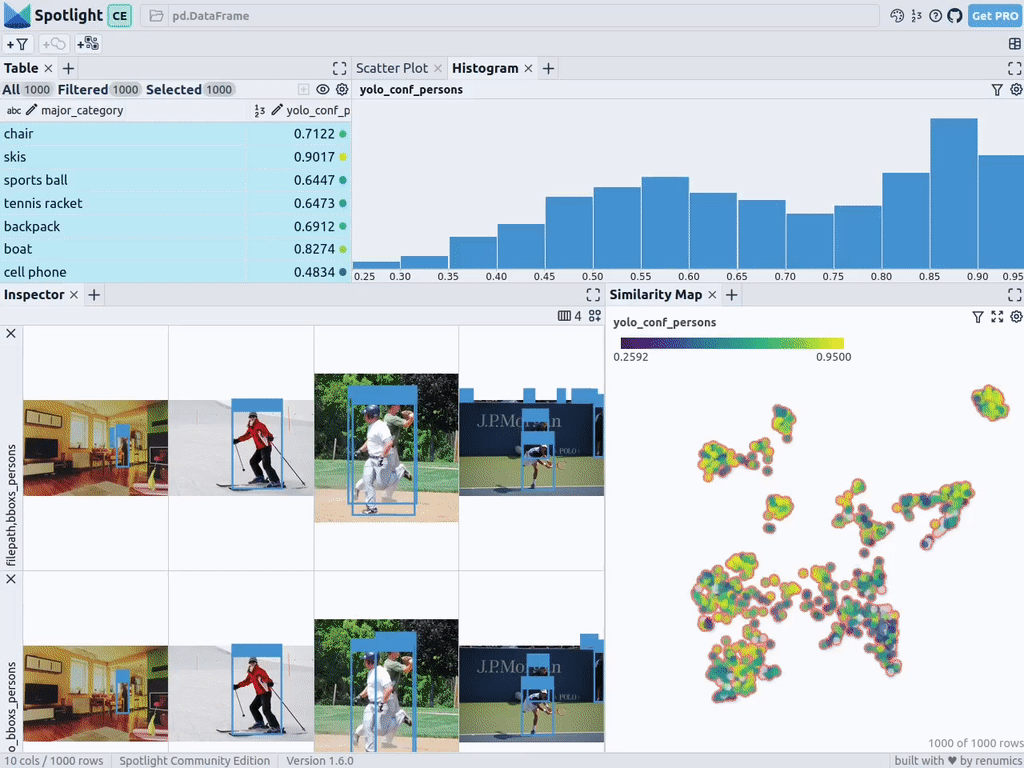
在Renumics Spotlight上的目標視覺化。資料來源:作者創建
下載COCO資料集中的人物影像
首先,透過以下命令安裝所需的軟體包:
!pip install fiftyone ultralytics renumics-spotlight- 1.
利用FiftyOne的可恢復性下載功能,您可以從COCO 資料集下載各種影像。透過簡單的參數設置,我們即可下載包含一到多個人物的 1,000 張影像。具體代碼如下:
importpandasaspd
importnumpyasnp
importfiftyone.zooasfoz
# 从 COCO 数据集中下载 1000 张带人的图像
dataset = foz.load_zoo_dataset(
"coco-2017"、
split="validation"、
label_types=[
"detections"、
],
classes=["person"]、
max_samples=1000、
dataset_name="coco-2017-person-1k-validations"、
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
接著,您可以使用以下程式碼:
def xywh_too_xyxyn(bbox):
"" convert from xywh to xyxyn format """
return[bbox[0], bbox[1], bbox[0] + bbox[2], bbox[1] + bbox[3]].
行 = []
fori, samplein enumerate(dataset):
labels = [detection.labelfordetectioninsample.ground_truth.detections] bboxs = [...
bboxs = [
xywh_too_xyxyn(detection.bounding_box)
fordetectioninsample.ground_truth.detections
]
bboxs_persons = [bboxforbbox, labelin zip(bboxs, labels)iflabel =="person"] 行。
row.append([sample.filepath, labels, bboxs, bboxs_persons])
df = pd.DataFrame(row, columns=["filepath","categories", "bboxs", "bboxs_persons"])
df["major_category"] = df["categories"].apply(
lambdax:max(set(x) -set(["person"]), key=x.count)
if len(set(x)) >1
else "only person"。
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
將資料準備為 Pandas DataFrame,其中的列包括有:文件路徑、邊框盒(bounding boxe)類別、邊框盒、邊框盒包含的人物、以及主要類別(儘管有人物),以指定圖像中人物的上下文:
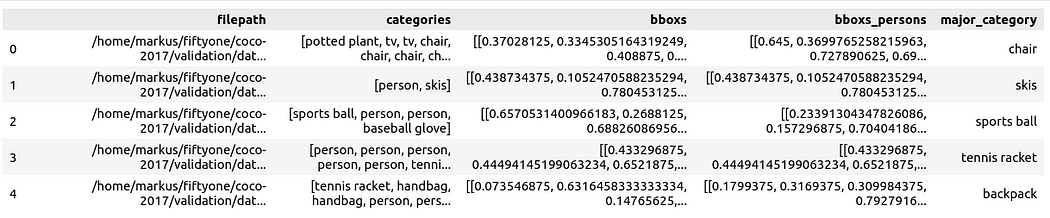
然後,您可以透過 Spotlight 將其視覺化:
From renumics import spotlight
spotlight.show(df)- 1.
- 2.
您可以使用檢查器視圖中的新增視圖按鈕,並在邊框視圖中選擇bboxs_persons和filepath,以顯示帶有圖像的對應邊框:
嵌入豐富的數據
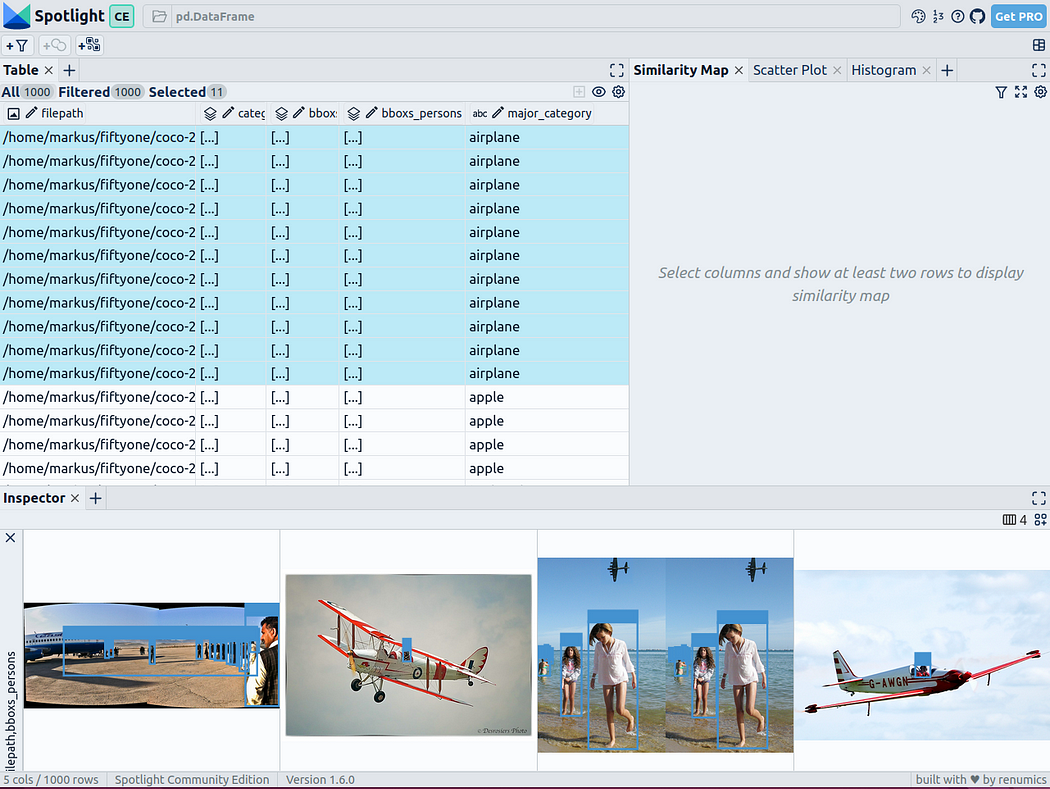
要使得資料具有結構性,我們可以採用各種基礎模型的影像嵌入(即:密集向量表示)。為此,您可以使用 UMAP 或 t-SNE 等進一步降維技術,將整個影像的Vision Transformer(ViT)嵌入應用於資料集的結構化,從而提供影像的二維相似性圖。此外,您還可以使用預先訓練物件偵測器的輸出結果,依照包含物件的大小或數量,將資料分類,進而建構資料。由於 COCO 資料集已經提供了此方面的信息,因此我們完全可以直接使用它。
由於Spotl ight 整合了對google/vit-base-patch16-224-in21k(ViT)模型和UMAP的支持,因此當您使用檔案路徑建立各種嵌入時,它將會自動套用:
spotlight.show(df, embed=["filepath"])- 1.
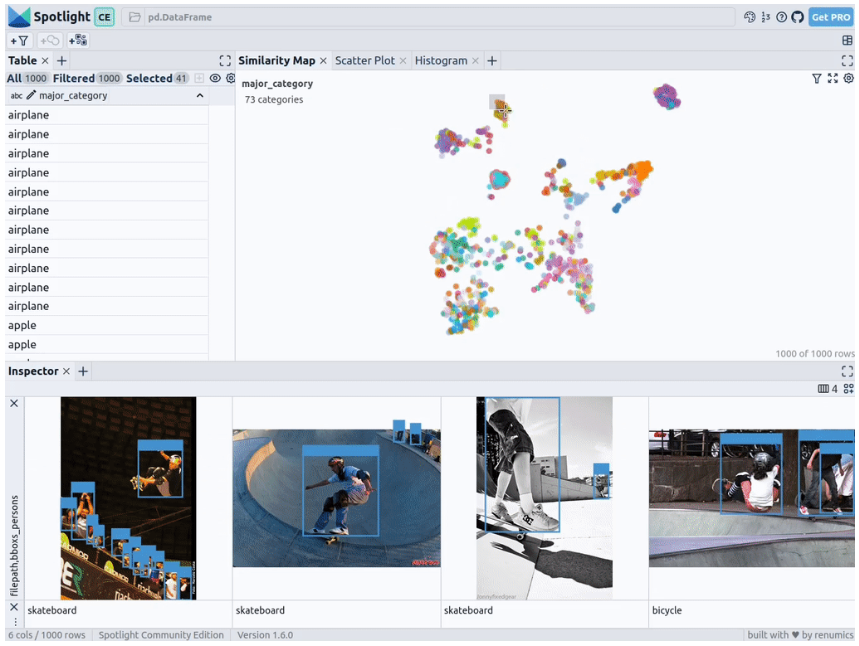
透過上述程式碼,Spotlight 將各種嵌入進行計算,並應用 UMAP 在相似性地圖中顯示結果。其中,不同的顏色代表了主要的類別。據此,您可以使用相似性地圖來瀏覽資料:
預訓練YOLOv8的結果
可用於快速辨識物體的Ultralytics YOLOv8,是一套先進的物體偵測模型。它專為快速影像處理而設計,適用於各種即時檢測任務,特別是在應用於大量資料時,使用者無需浪費太多的等待時間。
為此,您可以先載入預訓練模型:
From ultralytics import YOLO
detection_model = YOLO("yolov8n.pt")- 1.
- 2.
並執行各種檢測:
detections = []
forfilepathindf["filepath"].tolist():
detection = detection_model(filepath)[0]
detections.append(
{
"yolo_bboxs":[np.array(box.xyxyn.tolist())[0]forboxindetection.boxes]、
"yolo_conf_persons": np.mean([
np.array(box.conf.tolist())[0].
forboxindetection.boxes
ifdetection.names[int(box.cls)] =="person"]), np.mean(
]),
"yolo_bboxs_persons":[
np.array(box.xyxyn.tolist())[0]
forboxindetection.boxes
ifdetection.names[int(box.cls)] =="person
],
"yolo_categories": np.array(
[np.array(detection.names[int(box.cls)])forboxindetection.boxes], "yolo_categories": np.array(
),
}
)
df_yolo = pd.DataFrame(detections)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
在12gb的GeForce RTX 4070 Ti上,上述過程在不到20秒的時間內便可完成。接著,您可以將結果包含在DataFrame中,並使用Spotlight將其視覺化。請參考如下程式碼:
df_merged = pd.concat([df, df_yolo], axis=1)
spotlight.show(df_merged, embed=["filepath"])- 1.
- 2.
下一步,Spotlight將再次計算各種嵌入,並套用UMAP到相似度圖中顯示結果。不過這次,您可以為檢測到的物件選擇模型的置信度,並使用相似度圖在置信度較低的叢集中導航檢索。畢竟,鑑於這些圖像的模型是不確定的,因此它們通常具有一定的相似度。
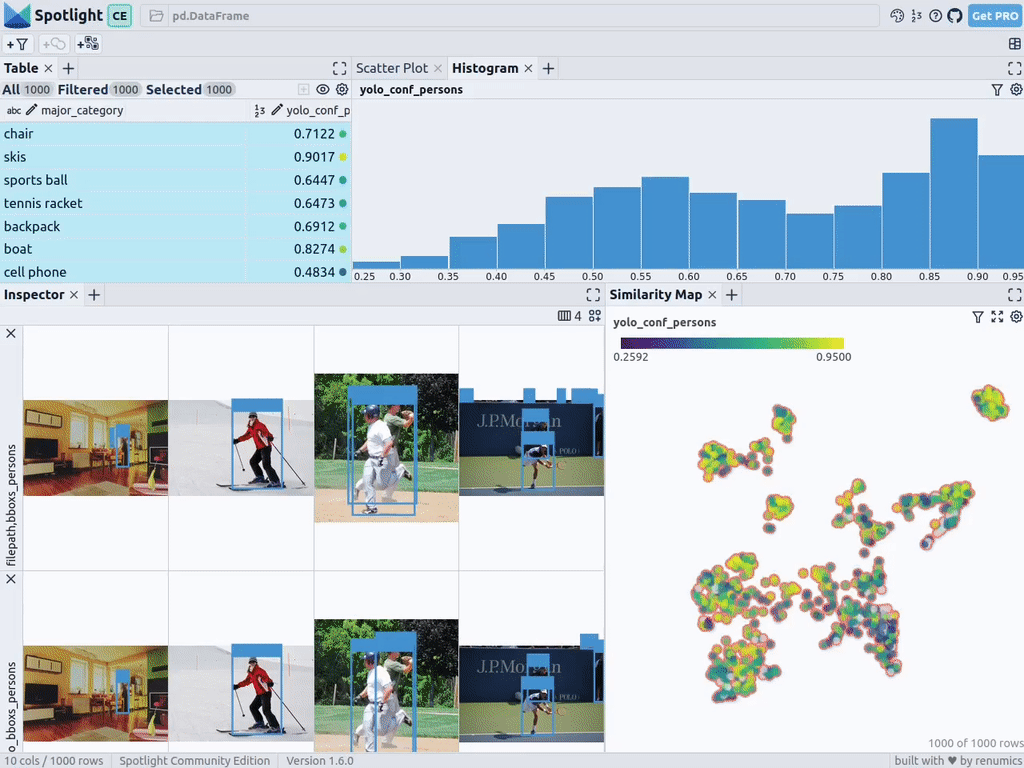
當然,上述簡短的分析也顯示了,此類模型在以下場景中會遇到系統性的問題:
- 由於列車體積龐大,站在車廂外的人顯得非常渺小
- 對於巴士和其他大型車輛而言,車內的人員幾乎看不到
- 有人站在飛機的外面
- 食物的特寫圖片上有人的手或手指
您可以判斷這些問題是否真的會影響您的人員檢測目標,如果是的話,則應考慮使用額外的訓練數據,來增強數據集,以優化模型在這些特定場景中的性能。
小結
綜上所述,預訓練模型和 Spotlight 等工具的使用,可以讓我們的物件偵測視覺化過程變得更加容易,進而增強資料科學的工作流程。您可以使用自己的資料去嘗試和體驗上述程式碼。
譯者介紹
陳峻(Julian Chen),51CTO社群編輯,具有十多年的IT專案實施經驗,善於對內外部資源與風險實施管控,專注傳播網路與資訊安全知識與經驗。
原文標題:How to Explore and Visualize ML-Data for Object Detection in Images,作者:Markus Stoll
連結:https://itnext.io/how-to-explore-and-visualize-ml-data-for-object-detection-in-images-88e074f46361。