LLM can write code ≠ reasoning + planning! AAAI chairman reveals: The quality of code data is too high|LeCun praises it
2024.01.23

Since the release of ChatGPT, various products based on large models have been quickly integrated into ordinary people's lives. However, even non-AI practitioners can find after using it a few times that large models often make things up and generate wrong facts. .
However, for programmers, using large models such as GPT-4 as a "code-assisted generation tool" is obviously much easier to use than a "fact retrieval tool" because code generation often involves complex logical analysis. etc., so some people attribute this reasoning (generalized planning) ability to the emergence of large language models (LLM).
Academic circles have also been debating the issue of "whether LLM can reason".

Recently, computer scientist and Arizona State University professor Subbarao Kambhampati (Rao) comprehensively summarized the research on language models in reasoning and planning with the title "Can LLMs Really Reason & Plan?" The results also talk about the relationship between LLM's code generation and reasoning capabilities.

Video link: https://www.youtube.com/watch?v=uTXXYi75QCU
PPT link: https://www.dropbox.com/scl/fi/g3qm2zevcfkp73wik2bz2/SCAI-AI-Day-talk-Final-as-given.pdf
To summarize in one sentence: LLM's code generation quality is higher than English (natural language) generation quality. It can only show that "approximate retrieval on GitHub" is easier than "retrieval on general Web", but cannot reflect any underlying reasoning. ability.
There are two main reasons for this difference:
1. The quality of code data used for LLM training is higher than that of text
2. The "distance between syntax and semantics" in formal languages is lower than that in highly flexible natural languages.

Turing Award winner Yann LeCun also agreed: Autoregressive LLM is very helpful for coding, even if LLM really does not have planning capabilities.
Professor Rao is the president of AAAI, a director of IJCAI, and a founding board member of Partnership on AI; his main research directions are:

1. Human-Aware AI Systems: explainable artificial intelligence interaction. Planning and decision-making in artificial intelligence systems. Human-machine teaming. Proactive decision support. Learnable planning models and Model Lite planning. Explainable behavior and interpretation. Human factors assessment.
2. Automated Planning (AI): planning synthesis and heuristic methods in measurement, time, partially accessible and stochastic worlds. Multi-objective optimization of planning. Reason using expressive movements. schedule. Accelerate learning to help planners. Constraint satisfaction and operations research techniques. Planning applications in automated manufacturing and spatial autonomy.
3. Social Media Analysis & Information Integration: Human behavior analysis on social media platforms. Adaptive techniques for query optimization and execution in information integration. Source discovery and source metadata learning.
Code generation ≠ reasoning + planning
The late computer scientist Drew McDermott once said that planning is just automatic programming on a language with primitives corresponding to executable actions .
In other words, planning in a broad sense can be written as a program. If GPT-4 or other large models can generate code correctly, it proves that LLM has planning capabilities.
For example, in May last year, NVIDIA, Caltech and other research teams collaborated to develop the Voyager agent, which is also the first LLM-based embodied, lifelong learning agent (embodied) in Minecraft (the game "Minecraft"). lifelong learning agent) that can continuously explore the world, acquire various skills, and make new discoveries without human intervention.

Paper link: https://arxiv.org/abs/2305.16291
The core idea of Voyager is to let LLM output code to perform tasks and run it in the simulator. It contains three key components: an automatic curriculum that maximizes exploration; executable code for storing and retrieving complex behaviors A growing library of skills; a new iterative prompt mechanism that incorporates environmental feedback, execution errors, and self-validation to improve the program.
Voyager interacts with GPT-4 through black-box queries, eliminating the need to fine-tune model parameters.
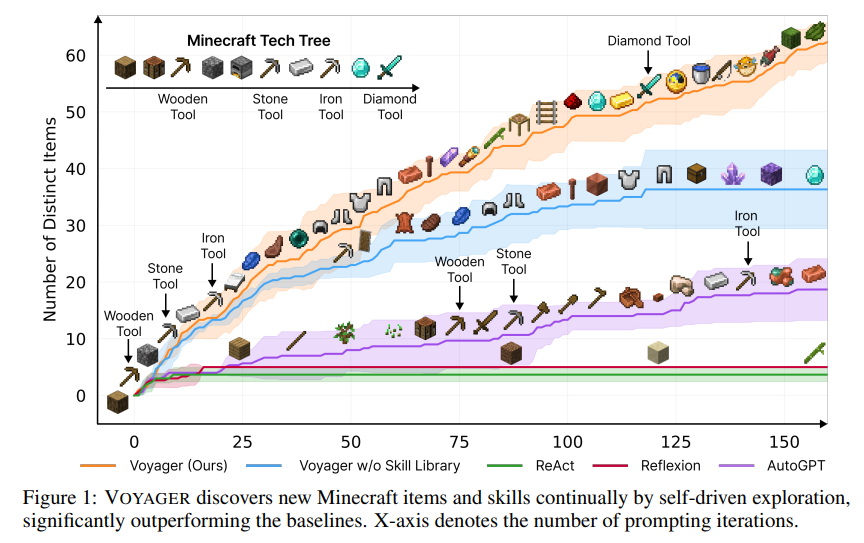
Although there are other jobs similar to Voyager that can use LLM to complete planning through code generation, this does not prove that LLM has planning capabilities.
In principle, LLM is essentially an approximate retrieval, and whether it can be successfully planned depends on the quality of the training data.
In natural language generation, LLM needs to devour massive amounts of data, much of which has very different factual bases or value systems. For example, flat-earth theorists and vaccine opponents also have their own theories and can write convincing article.
In terms of code generation, training data mainly comes from open source code on GitHub, most of which is "valid data", and the value system of software engineers has minimal impact on the quality of the code. This can also explain why the quality of code generation is higher than Text completion is of higher quality.
Despite this, the essence of code generation is still approximate retrieval, and its correctness cannot be guaranteed. Therefore, when using auxiliary tools such as GitHub Copilot, you can often see people complaining that it takes too long to debug the generated code. Code often looks like it's working fine, but it contains bugs underneath.
Part of the reason why the code seems to work can be attributed to two reasons:
1. There is an auxiliary tool (incremental interpreter) in the system that can mark obvious execution exceptions so that human programmers can notice them during debugging;
2. A syntactically correct code segment may also be semantically correct. Although it is not completely guaranteed, syntactically correct is a prerequisite for executability (the same is true for natural languages).
Language model self-validation
In a few cases, such as the Voyager model mentioned above, its developers claim that the quality of the generated code is good enough to run directly in the world, but a closer reading reveals that this effect mainly relies on the world being vague to planning. Sexual tolerance.
Some papers also use "LLM self-verification" (self-verify, self-critique self-criticism) method, that is, try to perform verification once in the target scenario before running the code, but again, there is no reason to believe that LLM has self-verification Ability.
The following two papers question the verification capabilities of the model.

Paper link: https://arxiv.org/abs/2310.12397
This paper systematically studies the effectiveness of iterative prompts for LLMs in the context of graph coloring (a typical NP-complete inference problem), involving proposition satisfiability as well as practical problems such as scheduling and allocation; the paper proposes A principled empirical study is conducted on the performance of GPT4 in solving graph coloring instances or verifying the correctness of candidate colorings.
In iterative mode, researchers ask the model to verify their own answers and validate the proposed solution with an externally correct inference engine.
turn out:
1. LLMs are poor at solving graph coloring instances;
2. No better performance in validating solutions - so in iterative mode, LLMs criticize LLM-generated solutions as invalid;
3. The validity and content of the criticisms (LLMs themselves and external solvers) seem to be largely irrelevant to the performance of iterative hints.
The second paper investigates whether large models can improve planning through self-criticism.

Paper link: https://arxiv.org/abs/2310.08118
The results of this paper show that self-criticism appears to reduce plan generation performance. In the case of GPT-4, both external validators and self-validators produced very many false positives in this system, damaging system reliability.
Moreover, the feedback signal is binary (correct, wrong) and detailed information has little impact on plan generation, that is, the effectiveness of LLM in the framework of self-criticism and iterative planning tasks is questionable.