IO multiplexing, a complete understanding in one article!

IO multiplexing technology is an important knowledge point, whether it is for interviews or daily technical accumulation. Many high-performance technical frameworks have it. So, what is IO multiplexing? What problems does IO multiplexing solve? Let's analyze it together today.

1. Common IO models
There are four common network IO models: synchronous blocking IO (Blocking IO, BIO), synchronous non-blocking IO (NIO), IO multiplexing, and asynchronous non-blocking IO (Async IO, AIO). AIO is asynchronous IO, and the others are synchronous IO.
1. Synchronous blocking IO-BIO
Synchronous blocking IO: During the thread processing, if an IO operation is involved, the current thread will be blocked until the IO operation is completed, and the thread will continue to process the subsequent process. As shown in the figure below, the server will assign a new thread to process each socket of the client. The business processing of each thread is divided into two steps. When the IO operation (such as loading a file) is encountered after the processing of step 1 is completed, the current thread will be blocked until the IO operation is completed, and the thread will continue to process step 2.
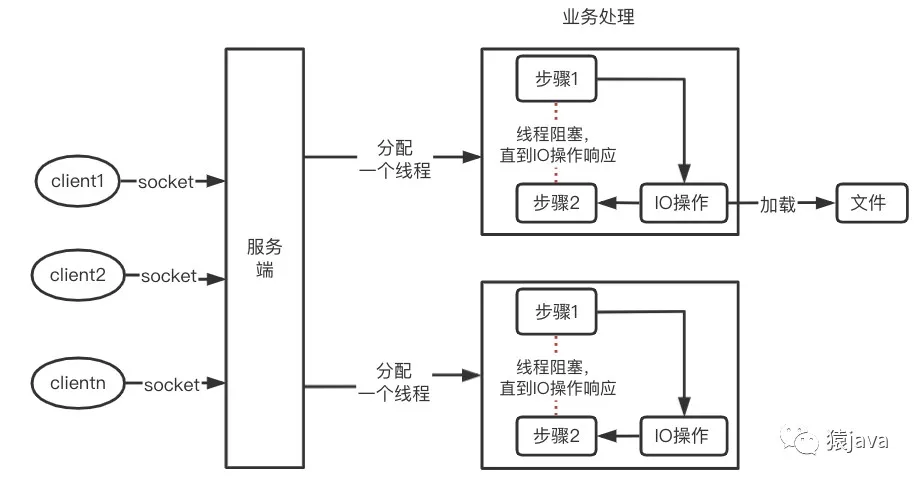
Actual usage scenario: Using the thread pool method in Java to connect to the database uses the synchronous blocking IO model.
Disadvantages of the model: Because each client requires a new thread, it is bound to cause threads to be frequently blocked and switched, which will cause overhead.
2. Synchronous non-blocking IO-NIO (New IO)
Synchronous non-blocking IO: During thread processing, if IO operations are involved, the current thread will not be blocked, but will process other business codes, and then wait for a while to check whether the IO interaction is completed. As shown in the following figure: Buffer is a buffer used to cache read and write data; Channel is a channel responsible for the background connection IO data; and the main function of Selector is to actively query which channels are in the ready state. Selector reuses a thread to query the ready channels, which greatly reduces the overhead of frequent thread switching caused by IO interaction.
Actual usage scenarios: Java NIO is based on this IO interaction model to support business code to implement synchronous non-blocking design for IO, thereby reducing the overhead of frequent thread blocking and switching in the traditional synchronous blocking IO interaction process. The classic case of NIO is the Netty framework, and the underlying Elasticsearch actually adopts this mechanism.
3.IO multiplexing
The following section on what IO multiplexing is will explain this in detail.
4. Asynchronous non-blocking IO-AIO
AIO is the abbreviation of asynchronous IO. For AIO, it does not notify the thread when the IO is ready, but notifies the thread after the IO operation is completed. Therefore, AIO will not block at all. At this time, our business logic will become a callback function, which will be automatically triggered by the system after the IO operation is completed. AIO is used in netty5, but despite great efforts, the performance of netty5 did not make a big leap over netty4, so netty5 was eventually offline.
Next, our protagonist today, IO multiplexing, comes into play
2. What is IO multiplexing?
Presumably, when we learn a new technology or a new concept, the biggest question is the concept itself. IO multiplexing is no exception. To figure out what IO multiplexing is, we can start with the "road" in IO multiplexing.
Road: The original meaning is road, such as: asphalt road in the city, mud road in the countryside, these must be familiar to everyone. So: what does the road in IO refer to?
Don’t be in a hurry, let’s first take a look at what IO is?
In computers, IO stands for input and output. Direct information interaction is achieved through the underlying IO devices. According to different operation objects, it can be divided into disk I/O, network I/O, memory mapping I/O, etc. As long as there is an interactive system of input and output type, it can be considered as an I/O system. Finally, let's take a look at "path" and "multipath"
In socket programming, the five elements [ClientIp, ClientPort, ServerIp, ServerPort, Protocol] can uniquely identify a socket connection. Based on this premise, a port of the same service can establish socket connections with n clients, which can be roughly described by the following figure:

Therefore, each socket connection between a client and a server can be considered as "one path", and multiple socket connections between multiple clients and the server are "multiple paths". Thus, IO multiplexing is the input and output streams on multiple socket connections, and multiplexing is the input and output streams on multiple socket connections being processed by one thread. Therefore, IO multiplexing can be defined as follows:
IO multiplexing in Linux means that one thread handles multiple IO streams.
3. What are the implementation mechanisms of IO multiplexing?
Let's first look at the basic socket model to contrast it with the IO multiplexing mechanism below. The pseudo code is as follows
listenSocket = socket(); //系统调用socket()函数,调用创建一个主动socket
bind(listenSocket); //给主动socket绑定地址和端口
listen(listenSocket); //将默认的主动socket转换为服务器使用的被动socket(也叫监听socket)
while (true) { //循环监听客户端连接请求
connSocket = accept(listenSocket); //接受客户端连接,获取已连接socket
recv(connsocket); //从客户端读取数据,只能同时处理一个客户端
send(connsocket); //给客户端返回数据,只能同时处理一个客户端
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
The network communication process is as follows:

The basic socket model can realize the communication between the server and the client, but each time the program calls the accept function, it can only handle one client connection. When there are a large number of client connections, the processing performance of this model is relatively poor. Therefore, Linux provides a high-performance IO multiplexing mechanism to solve this dilemma.
In Linux, the operating system provides three IO multiplexing mechanisms: select, poll, and epoll. We mainly analyze the principles of the three multiplexing mechanisms from the following four aspects:
- How many sockets can IO multiplexing monitor?
- What events in the socket can IO multiplexing monitor?
- How does IO multiplexing perceive the ready file descriptor fd?
- How does IO multiplexing achieve network communication?
1.Selection mechanism
An important function in the select mechanism is select(), which takes 4 input parameters and returns an integer. The prototype and parameter details of select() are as follows:
/**
* 参数说明
* 监听的文件描述符数量__nfds、
* 被监听描述符的三个集合*__readfds,*__writefds和*__exceptfds
* 监听时阻塞等待的超时时长*__timeout
* 返回值:返回一个socket对应的文件描述符
*/
int select(int __nfds, fd_set * __readfds, fd_set * __writefds, fd_set * __exceptfds, struct timeval * __timeout)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
(1) How many sockets can select monitor?
Answer: 1024
(2) Which socket events can select monitor?
Answer: The select() function has three fd_set sets, which represent the three types of events to be monitored, namely read data events (__readfds set), write data events (__writefds set) and exception events (__exceptfds set). When the set is NULL, it means that the corresponding event does not need to be processed.
(3) How does select perceive the ready fd?
Answer: You need to traverse the fd set to find the ready descriptor.
(4) How does the select mechanism achieve network communication?
Code:
int sock_fd,conn_fd; //监听socket和已连接socket的变量
sock_fd = socket() //创建socket
bind(sock_fd) //绑定socket
listen(sock_fd) //在socket上进行监听,将socket转为监听socket
fd_set rset; //被监听的描述符集合,关注描述符上的读事件
int max_fd = sock_fd
//初始化rset数组,使用FD_ZERO宏设置每个元素为0
FD_ZERO(&rset);
//使用FD_SET宏设置rset数组中位置为sock_fd的文件描述符为1,表示需要监听该文件描述符
FD_SET(sock_fd,&rset);
//设置超时时间
struct timeval timeout;
timeout.tv_sec = 3;
timeout.tv_usec = 0;
while(1) {
//调用select函数,检测rset数组保存的文件描述符是否已有读事件就绪,返回就绪的文件描述符个数
n = select(max_fd+1, &rset, NULL, NULL, &timeout);
//调用FD_ISSET宏,在rset数组中检测sock_fd对应的文件描述符是否就绪
if (FD_ISSET(sock_fd, &rset)) {
//如果sock_fd已经就绪,表明已有客户端连接;调用accept函数建立连接
conn_fd = accept();
//设置rset数组中位置为conn_fd的文件描述符为1,表示需要监听该文件描述符
FD_SET(conn_fd, &rset);
}
//依次检查已连接socke的文件描述符
for (i = 0; i < maxfd; i++) {
//调用FD_ISSET宏,在rset数组中检测文件描述符是否就绪
if (FD_ISSET(i, &rset)) {
//有数据可读,进行读数据处理
}
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- twenty one.
- twenty two.
- twenty three.
- twenty four.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
Select to implement network communication process as shown below:

The shortcomings of the select function:
- First of all, the select() function has a limit on the number of file descriptors that a single process can monitor. The number of file descriptors it can monitor is determined by __FD_SETSIZE, and the default value is 1024.
- Secondly, after the select function returns, the descriptor set needs to be traversed to find the ready descriptor. This traversal process will generate a certain amount of overhead, thereby reducing the performance of the program.
2. Poll mechanism
The main function of the poll mechanism is the poll() function. The prototype definition of the poll() function is
/**
* 参数 *__fds 是 pollfd 结构体数组,pollfd 结构体里包含了要监听的描述符,以及该描述符上要监听的事件类型
* 参数 __nfds 表示的是 *__fds 数组的元素个数
* __timeout 表示 poll 函数阻塞的超时时间
*/
int poll (struct pollfd *__fds, nfds_t __nfds, int __timeout);
pollfd结构体的定义
struct pollfd {
int fd; //进行监听的文件描述符
short int events; //要监听的事件类型
short int revents; //实际发生的事件类型
};- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
The pollfd structure contains three member variables: fd, events, and revents, which represent the file descriptor to be monitored, the event type to be monitored, and the actual event type.
(11) How many sockets can poll monitor?
Answer: Customized, but the system needs to be able to withstand
(2) What events in the socket can poll monitor?
The event types to be monitored and actually occurred in the pollfd structure are represented by the following three macro definitions: POLLRDNORM, POLLWRNORM, and POLLERR, which represent readable, writable, and error events, respectively.
#define POLLRDNORM 0x040 //可读事件
#define POLLWRNORM 0x100 //可写事件
#define POLLERR 0x008 //错误事件- 1.
- 2.
- 3.
(3) How does poll obtain the ready fd?
Answer: Similar to select, you need to traverse the fd set to find the ready descriptor.
(4) How does the poll mechanism achieve network communication?
Poll implementation code:
int sock_fd,conn_fd; //监听套接字和已连接套接字的变量
sock_fd = socket() //创建套接字
bind(sock_fd) //绑定套接字
listen(sock_fd) //在套接字上进行监听,将套接字转为监听套接字
//poll函数可以监听的文件描述符数量,可以大于1024
#define MAX_OPEN = 2048
//pollfd结构体数组,对应文件描述符
struct pollfd client[MAX_OPEN];
//将创建的监听套接字加入pollfd数组,并监听其可读事件
client[0].fd = sock_fd;
client[0].events = POLLRDNORM;
maxfd = 0;
//初始化client数组其他元素为-1
for (i = 1; i < MAX_OPEN; i++)
client[i].fd = -1;
while(1) {
//调用poll函数,检测client数组里的文件描述符是否有就绪的,返回就绪的文件描述符个数
n = poll(client, maxfd+1, &timeout);
//如果监听套件字的文件描述符有可读事件,则进行处理
if (client[0].revents & POLLRDNORM) {
//有客户端连接;调用accept函数建立连接
conn_fd = accept();
//保存已建立连接套接字
for (i = 1; i < MAX_OPEN; i++){
if (client[i].fd < 0) {
client[i].fd = conn_fd; //将已建立连接的文件描述符保存到client数组
client[i].events = POLLRDNORM; //设置该文件描述符监听可读事件
break;
}
}
maxfd = i;
}
//依次检查已连接套接字的文件描述符
for (i = 1; i < MAX_OPEN; i++) {
if (client[i].revents & (POLLRDNORM | POLLERR)) {
//有数据可读或发生错误,进行读数据处理或错误处理
}
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- twenty one.
- twenty two.
- twenty three.
- twenty four.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
The network communication process implemented by poll is as follows:
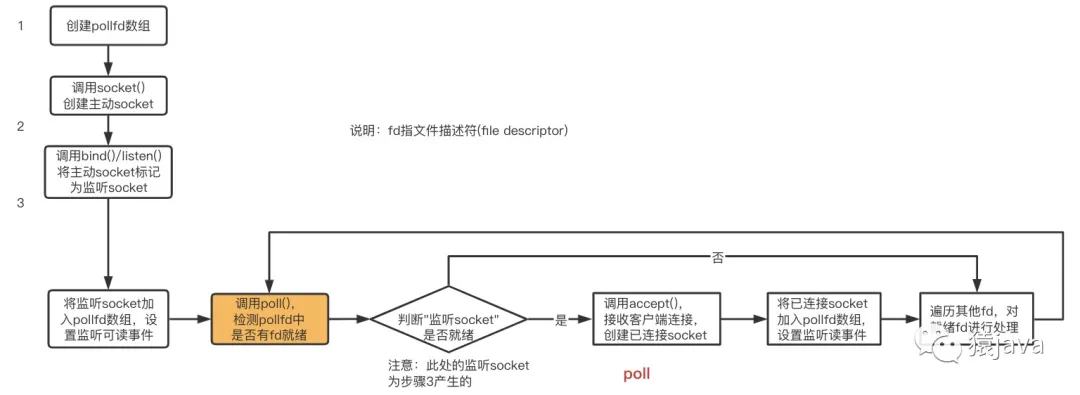
The poll mechanism solves the limitation that a single select process can only listen to 1024 sockets at most, but it does not solve the problem of polling to obtain ready fd.
3.epoll mechanism
(1) The structure of epoll
epoll was proposed in the 2.6 kernel, and uses the epoll_event structure to record the fd to be monitored and the event type it monitors.
Definition of epoll_event structure and epoll_data structure:
typedef union epoll_data
{
...
int fd; //记录文件描述符
...
} epoll_data_t;
struct epoll_event
{
uint32_t events; //epoll监听的事件类型
epoll_data_t data; //应用程序数据
};- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
The epoll interface is relatively simple, with three functions:
① int epoll_create(int size);
Create an epoll handle, and size is used to tell the kernel how many listeners there are. The epoll instance maintains two structures inside, one for recording the fd to be monitored and the other for the ready fd. For the ready file descriptors, they will be returned to the user program for processing.
② int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
epoll's event registration function, epoll_ctl, adds, modifies, or deletes events of interest to the epoll object, and returns 0 if successful, otherwise returns -1. At this time, the error type needs to be determined based on the errno error code. It is different from select(), which tells the kernel what type of event to listen for when listening for events, but registers the event type to be listened for here first. The events returned by the epoll_wait method must have been added to epoll through epoll_ctl.
③ int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
Waiting for events to be generated is similar to the select() call. The events parameter is used to get the event set from the kernel, maxevents is the size of the events set, and is not greater than the size of epoll_create(), and the timeout parameter is the timeout (in milliseconds, 0 will return immediately, -1 will be uncertain, and some say it is permanently blocked). The function returns the number of events that need to be processed, 0 means timeout, and -1 means error. You need to check the errno error code to determine the error type.
(2) About epoll's ET and LT working modes
epoll has two working modes: LT (level triggered) mode and ET (edge triggered) mode.
By default, epoll works in LT mode, which can handle blocking and non-blocking sockets. The EPOLLET in the above table indicates that an event can be changed to ET mode. ET mode is more efficient than LT mode, and it only supports non-blocking sockets.
(3) Differences between ET mode and LT mode
When a new event arrives, the event can be obtained from the epoll_wait call in ET mode. However, if the socket buffer corresponding to the event is not processed completely this time, and no new event arrives again on this socket, the event cannot be obtained from the epoll_wait call again in ET mode. On the contrary, in LT mode, as long as there is data in the socket buffer corresponding to an event, the event can always be obtained from epoll_wait. Therefore, it is simpler to develop epoll-based applications in LT mode and less prone to errors. In ET mode, if the buffer data is not processed thoroughly when an event occurs, the user request in the buffer will not be responded to.
(4) FAQ
How many sockets can epoll monitor?
Answer: Customized, but the system needs to be able to withstand
How does epoll get the ready fd?
Answer: The epoll instance maintains two structures inside, which record the fd to be monitored and the fd that is ready.
How does epllo achieve network communication?
The following code implements it:
int sock_fd,conn_fd; //监听socket和已连接socket的变量
sock_fd = socket() //创建主动socket
bind(sock_fd) //绑定socket
listen(sock_fd) //在socket进行监听,将socket转为监听socket
epfd = epoll_create(EPOLL_SIZE); //创建epoll实例,
//创建epoll_event结构体数组,保存socket对应文件描述符和监听事件类型
ep_events = (epoll_event*)malloc(sizeof(epoll_event) * EPOLL_SIZE);
//创建epoll_event变量
struct epoll_event ee
//监听读事件
ee.events = EPOLLIN;
//监听的文件描述符是刚创建的监听socket
ee.data.fd = sock_fd;
//将监听socket加入到监听列表中
epoll_ctl(epfd, EPOLL_CTL_ADD, sock_fd, &ee);
while (1) {
//等待返回已经就绪的描述符
n = epoll_wait(epfd, ep_events, EPOLL_SIZE, -1);
//遍历所有就绪的描述符
for (int i = 0; i < n; i++) {
//如果是监听socket描述符就绪,表明有一个新客户端连接到来
if (ep_events[i].data.fd == sock_fd) {
conn_fd = accept(sock_fd); //调用accept()建立连接
ee.events = EPOLLIN;
ee.data.fd = conn_fd;
//添加对新创建的已连接socket描述符的监听,监听后续在已连接socket上的读事件
epoll_ctl(epfd, EPOLL_CTL_ADD, conn_fd, &ee);
} else { //如果是已连接socket描述符就绪,则可以读数据
...//读取数据并处理
}
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- twenty one.
- twenty two.
- twenty three.
- twenty four.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
The process of epoll network communication is as follows:

4. Differences among the three
The differences between select, poll, and epoll can be summarized in the following table:
IO multiplexing mechanism | Maximum limit of listening file descriptors | How to find ready file descriptors |
select | 1024 | Iterate over the file descriptor set |
poll | customize | Iterate over the file descriptor set |
epoll | customize | epoll_wait returns a ready file descriptor |
The comparison chart of the three to achieve network communication is convenient for everyone to see the differences:

Technical framework using IO multiplexing
- redis: Redis's ae_select.c and ae_epoll.c files use the select and epoll mechanisms respectively to implement IO multiplexing;
- nginx: Nginx supports various IO multiplexing methods under different operating systems, such as epoll, select, and kqueue; Nginx uses epoll in ET mode.
- Reactor framework, Netty: Whether in C++ or Java, most high-performance network programming frameworks are based on the Reactor model. The most typical one is Java's Netty framework, and the Reactor model is based on IO multiplexing.
Summarize
This article analyzes a variety of IO models, focusing on the principle of IO multiplexing and source code analysis of each method. Because the IO multiplexing model is very helpful for understanding high-performance frameworks such as Redis and Nginx, it is recommended that you refer to the source code and study it more.