FisheyeDetNet: the first target detection algorithm based on fisheye camera

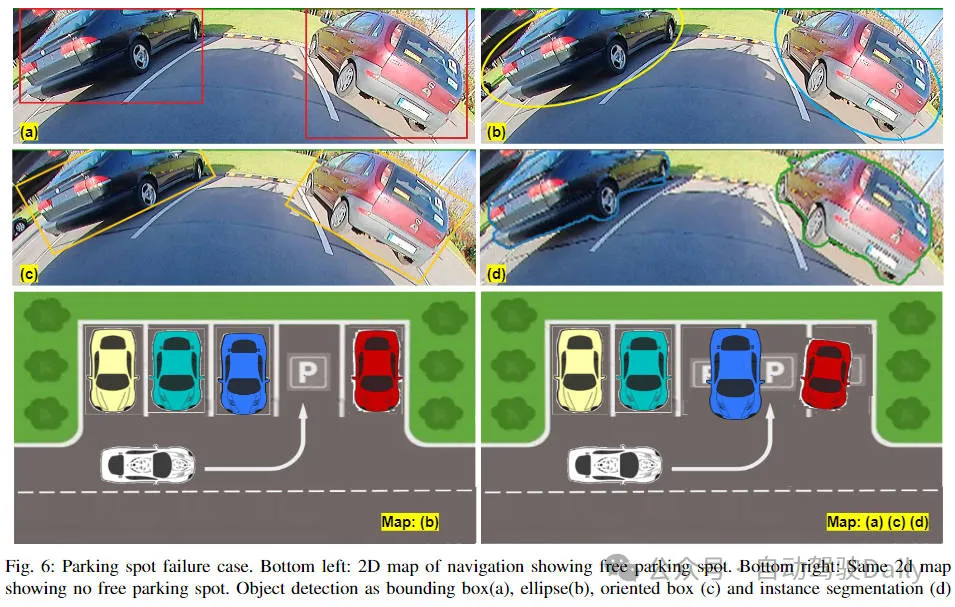
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, the perception of short distances using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the related issues mentioned above, we explore the standard object detection output representation of extended bounding boxes. We design rotated bounding boxes, ellipses, and general polygons as polar arc/angle representations, and define an instance segmentation mIOU metric to analyze these representations. The proposed model with polygons, FisheyeDetNet, outperforms other models while achieving a mAP metric of 49.5% on the Valeo fisheye camera dataset for autonomous driving. Currently, this is the first study on target detection algorithms based on fisheye cameras in autonomous driving scenarios.
Article link: https://arxiv.org/pdf/2404.13443.pdf
Network structure
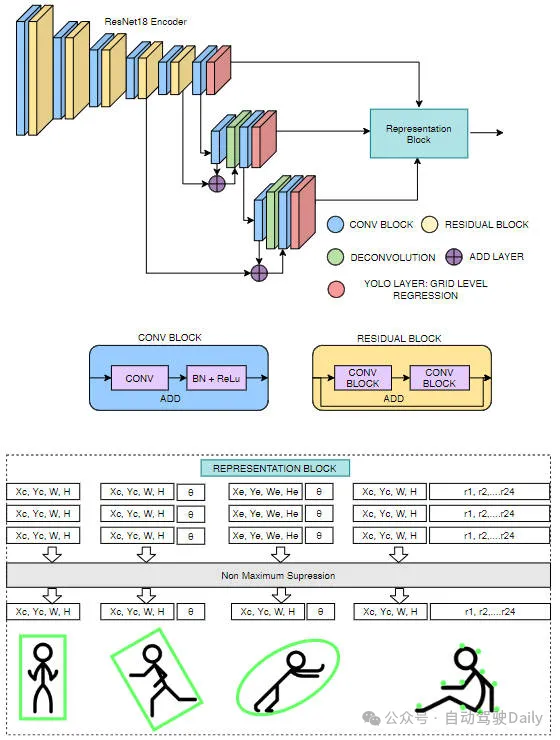
Our network structure is based on the YOLOv3 network model and provides multiple representations of bounding boxes, rotated bounding boxes, ellipses, and polygons. To enable the network to be ported to low-power automotive hardware, we use ResNet18 as the encoder. Compared with the standard Darknet53 encoder, the parameters are reduced by nearly 60%. The proposed network architecture is shown in the figure below.
Bounding box detection
Our bounding box model is the same as YOLOv3, except that the Darknet53 encoder is replaced by a ResNet18 encoder. Similar to YOLOv3, object detection is performed at multiple scales. For each grid in each scale, predict object width (), height (), object center coordinates (,), and object class. Finally, non-maximum suppression is used to filter redundant detections.
Rotated bounding box detection
In this model, the box orientation is regressed together with regular box information (,,,). The directional ground truth range (-180 to +180°) is normalized between -1 and +1.
Ellipse detection
Ellipse regression is the same as oriented box regression. The only difference is the output representation. So the loss function is also the same as the directed box loss.
polygon detection
Our proposed polygon-based instance segmentation method is very similar to the PolarMask and PolyYOLO methods. Instead use sparse polygon points and single-scale predictions like PolyYOLO. We use dense polygon annotation and multi-scale prediction.
Experimental comparison
We evaluate on the Valeo fisheye dataset, which has 60K images captured from 4 surround-view cameras in Europe, North America and Asia.
All models are compared using the mean precision metric (mAP) with an IoU threshold of 50%. The results are shown in the table below. Each algorithm is evaluated based on two criteria—identical representation and performance of instance segmentation.