CVPR 2024 | 面向真實感場景產生的光達擴散模型

論文想法:
擴散模型(DMs)在逼真的圖像合成方面表現出色,但將其適配到雷射雷達場景生成中卻面臨著重大挑戰。這主要是因為在點空間運作的DMs 難以保持雷射雷達場景的曲線樣式和三維幾何特性,這消耗了它們大部分的表徵能力。本文提出了光達擴散模型(LiDMs),這一模型透過在學習流程中融入幾何先驗,能夠從為捕獲光達場景的真實感而定制的隱空間中生成逼真的光達場景。本文的方法針對三個主要願望:模式的真實性、幾何的真實性、物體的真實性。具體來說,本文引入了曲線壓縮來模擬現實世界的雷射雷達模式,點級(point-wise)坐標監督來學習場景幾何,以及區塊級(patch-wise)編碼以獲得完整的三維物體上下文。憑藉這三個核心設計,本文在無條件雷射雷達產生的64線場景中建立了新的SOTA,同時與基於點的DMs相比保持了高效率(最高可快107倍)。此外,透過將雷射雷達場景壓縮到隱空間,本文使DMs 能夠在各種條件下控制,例如語義地圖、相機視圖和文字提示。
主要貢獻:
本文提出了一種新穎的雷射雷達擴散模型(LiDM),這是一種生成模型,能夠用於基於任意輸入條件的逼真雷射雷達場景生成。據本文所知,這是第一個能夠從多模態條件產生雷射雷達場景的方法。
本文引入了曲線級壓縮以保持逼真的光達模式,點級座標監督以規範場景級幾何的模型,並且引入了區塊級編碼以完全捕捉3D物體的上下文。
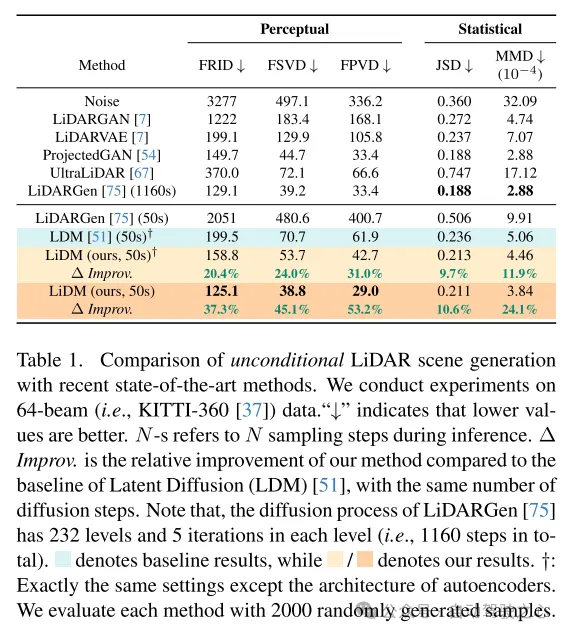
本文引入了三個指標,用於在感知空間中全面且定量地評估生成的雷射雷達場景質量,比較包括距離影像、稀疏體積和點雲等多種表示形式。
本文的方法在64線雷射雷達場景的無條件場景合成上實現了最新水平,並且相比於基於點的擴散模型實現了高達107倍的速度提升。
網路設計:
近年來,條件生成模型的發展迅速,這些模型能夠產生視覺上吸引人且高度逼真的影像。在這些模型中,擴散模型(DMs)憑藉其無可挑剔的性能,已成為最受歡迎的方法之一。為了實現任意條件下的生成,隱擴散模型(LDMs)[51] 結合了交叉注意力機制和卷積自編碼器,以生成高解析度影像。其後續擴展(例如,Stable Diffusion [2], Midjourney [1], ControlNet [72])進一步增強了其條件影像合成的潛力。
這項成功引發了本文的思考:我們能否將可控的擴散模型(DMs)應用於自動駕駛和機器人技術中的雷射雷達場景產生?例如,給定一組邊界框,這些模型能否合成相應的雷射雷達場景,從而將這些邊界框轉化為高品質且昂貴的標註資料?或者,是否有可能僅從一組影像生成一個3D場景?甚至更有野心地,我們能設計出一個由語言驅動的光達產生器來進行可控模擬嗎?為了回答這些交織在一起的問題,本文的目標是設計出能夠結合多種條件(例如,佈局、相機視角、文字)來產生逼真光達場景的擴散模型。
為此,本文從最近自動駕駛領域的擴散模型(DMs)工作中獲得了一些見解。在[75]中,介紹了一種基於點的擴散模型(即LiDARGen),用於無條件的雷射雷達場景產生。然而,這個模型往往會產生吵雜的背景(如道路、牆壁)和模糊的物體(如汽車),導致生成的雷射雷達場景與現實情況相去甚遠(參見圖1)。此外,在沒有任何壓縮的情況下對點進行擴散,會使得推理過程計算速度變慢。而且,直接應用patch-based 擴散模型(即Latent Diffusion [51])到雷射雷達場景生成,無論是在質量上或數量上,都未能達到令人滿意的性能(參見圖1)。
为了实现条件化的逼真激光雷达场景生成,本文提出了一种基于曲线的生成器,称为激光雷达扩散模型(LiDMs),以回答上述问题并解决近期工作中的不足。LiDMs 能够处理任意条件,例如边界框、相机图像和语义地图。LiDMs 利用距离图像作为激光雷达场景的表征,这在各种下游任务中非常普遍,如检测[34, 43]、语义分割[44, 66]以及生成[75]。这一选择是基于距离图像与点云之间可逆且无损的转换,以及从高度优化的二维卷积操作中获得的显著优势。为了在扩散过程中把握激光雷达场景的语义和概念本质,本文的方法在扩散过程之前,将激光雷达场景的编码点转换到一个感知等效的隐空间(perceptually equivalent latent space)中。
為了進一步提高真實世界雷射測距儀資料的逼真模擬效果,本文專注於三個關鍵組成部分:模式真實性、幾何真實性和物體真實性。首先,本文利用曲線壓縮在自動編碼過程中保持點的曲線圖案,此做法受到[59]的啟發。其次,為了實現幾何真實性,本文引入了點級座標監督,以教導本文的自編碼器理解場景層級的幾何結構。最後,本文透過增加額外的塊級下取樣策略來擴大感受野,以捕捉視覺上較大物體的完整上下文。透過這些提出的模組增強,所產生的感知空間使得擴散模型能夠高效地合成高品質的雷射雷達場景(參見圖1),同時在性能上也表現出色,與基於點的擴散模型相比速度提升了107倍(在一台NVIDIA RTX 3090上評估),並支援任意類型的基於影像和基於token 的條件。

圖1. 本文的方法(LiDM)在無條件的雷射雷達逼真場景生成方面確立了新的SOTA,並標誌著從不同輸入模態生成條件化雷射雷達場景方向上的一個里程碑。
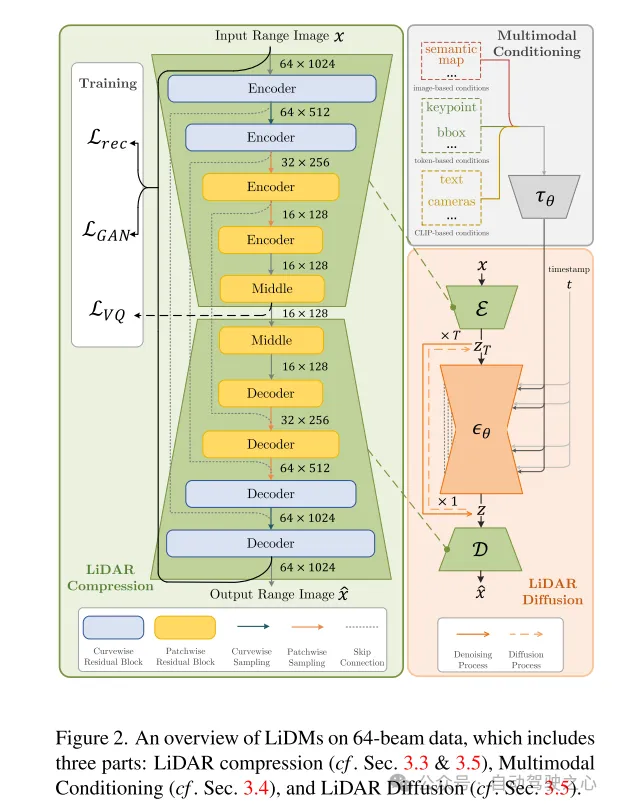
圖2. 64線資料上LiDMs 的概覽,包括三個部分:雷射雷達壓縮(參見第3.3節和3.5節)、多模態條件化(參見第3.4節)以及雷射雷達擴散(參見第3.5節) 。
實驗結果:

圖3. 在64線場景下,來自LiDARGen [75]、Latent Diffusion [51] 以及本文的LiDMs 的例子。

圖4. 在32線場景下,來自本文LiDMs 的例子。
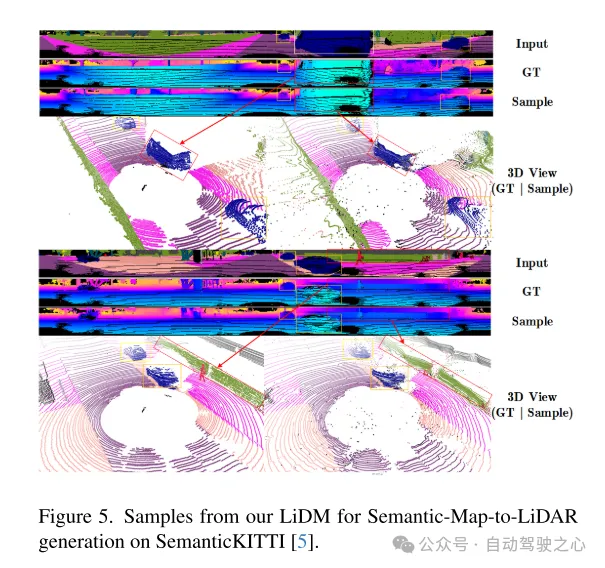
圖5. 在SemanticKITTI [5]資料集上,用於語意地圖到雷射雷達產生的本文的LiDM 的例子。
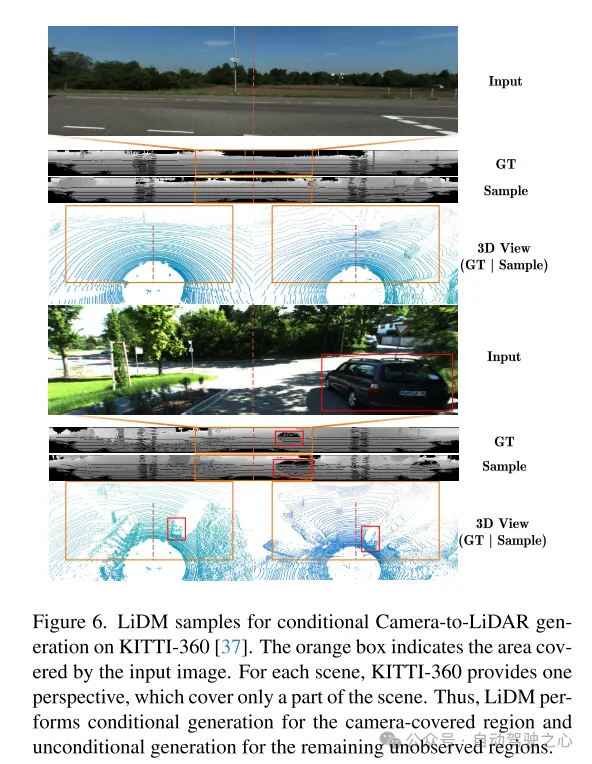
圖6. 在KITTI-360 [37]資料集上,用於條件相機到雷射雷達產生的LiDM 的例子。橘色框表示輸入影像所覆蓋的區域。對於每個場景,KITTI-360提供一個視角,它只涵蓋了場景的一部分。因此,LiDM 對相機覆蓋的區域執行條件生成,對其餘未觀測到的區域執行無條件生成。
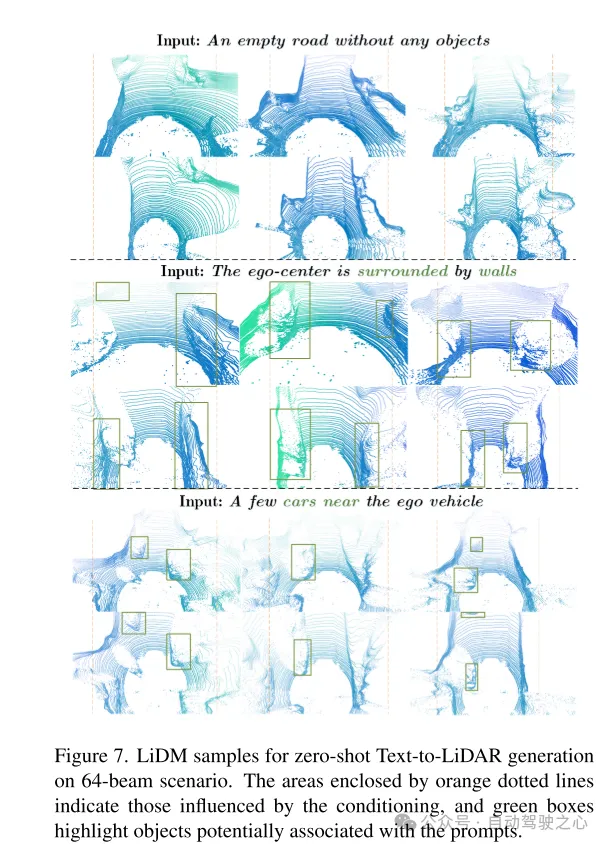
圖7. 在64線場景下,用於zero-shot 文字到雷射雷達產生的LiDM 的例子。橙色虛線框起的區域表示受條件影響的區域,綠色框突出顯示了可能與提示詞相關聯的物體。
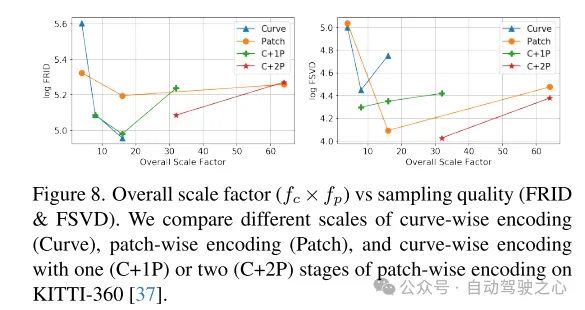
圖8. 總體縮放因子()與採樣品質(FRID和FSVD)的比較。本文在KITTI-360 [37]資料集上比較了不同規模的曲線級編碼(Curve)、區塊級編碼(Patch)以及帶有一(C+1P)或兩(C+2P)階段區塊級編碼的曲線級編碼。
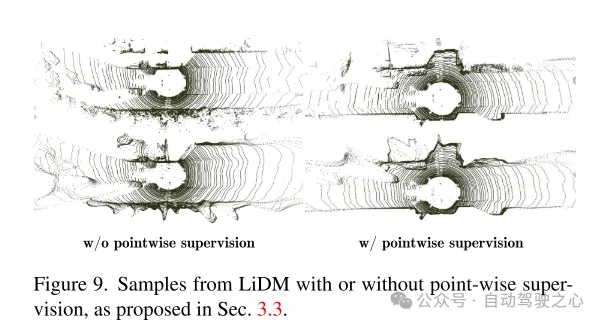
圖9. LiDM 的例子,包括有或沒有點級監督,如第3.3節所提出的。


總結:
本文提出了雷射雷達擴散模型(LiDMs),這是一個用於雷射雷達場景產生的通用條件化框架。本文的設計著重於保留曲線狀的圖案以及場景層級和物體層級的幾何結構,為擴散模型設計了一個高效的隱空間,以實現雷射雷達逼真生成。這種設計使得本文的LiDMs 在64線場景下能夠在無條件生成方面取得有競爭力的性能,並在條件生成方面達到了最先進的水平,可以使用多種條件對LiDMs 進行控制,包括語義地圖、相機視圖和文字提示。據本文所知,本文的方法是首次成功將條件引入雷射雷達生成的方法。
引用:
@inproceedings{ran2024towards,
title={利用 LiDAR 擴散模型實現真實場景生成},
author={Ran,Haoxi 和 Guizilini, Vitor 和 Wang, Yue},
booktitle={IEEE/CVF 計算機視覺和模式識別會議論文集},
年份={2024}
}