Why is it difficult to leverage the elastic capabilities of public clouds?

Cloud computing achieves better unit resource costs through resource pooling, allowing enterprises to outsource IDC construction, basic software development and operation and maintenance to cloud vendors, thereby focusing more on business innovation. The resource pool includes not only servers, but also talent. Cloud vendors have gathered outstanding engineers to provide professional services to many enterprises through cloud services, leaving professional matters to the most professional people.
Cloud computing has been developing for so many years. Elasticity is one of the technical capabilities that cloud computing practitioners are most concerned about. However, when it comes to specific cases, few customers can make good use of elasticity. Instead, elasticity has become a slogan and an ideal. This article attempts to discuss why the gap between reality and ideals is so large, and what flexible solutions are available with low investment and high returns.
Cloud vendors use annual and monthly subscription discounts to retain customers, which is contrary to elastic scenarios.
The following table is a comparison of typical yearly and monthly EC2 prices and pay-as-you-go prices, and summarizes the rules of the game:
- Compared with pay-as-you-go, annual and monthly subscriptions save approximately 50% of costs. This is why most enterprises choose annual and monthly subscriptions to use EC2 resources. This design is very reasonable from the perspective of cloud vendors, because cloud vendors determine how much idle water level to reserve for a Region by predicting the usage of customers across the entire network. Assuming that the prices of On Demand and Reserved instances are the same, it will make it difficult for cloud vendors to predict a Region. There will even be huge differences in water levels between day and night, which will directly affect the procurement decisions of the supply chain. Cloud vendors have a typical retail-like business model. The number of idle machines in each Region is analogous to inventory. The higher the inventory ratio, the lower the profit margin.
- Spot instances happen to be both cheap and paid by the hour. This also requires the application to be able to handle the impact of forced recycling of Spot instances. For stateless applications, it is relatively simple. Spot instances will notify the application before recycling. Most cloud vendors will Given a minute-level recycling window, as long as the application goes offline gracefully, it will have no impact on the business. Overseas startups [1] specialize in managing computing resources based on Spot instances. They have a large number of productized functions to help users make good use of Spot instances. AutoMQ company has also accumulated rich experience in using Spot instances [2]. However, for stateful applications, the threshold for using Spot instances becomes very high, and the state needs to be transferred before the instance is forcibly recycled. Applications such as Kafka, Redis, and MySQL. It is generally not recommended that users deploy basic software for this type of data directly to Spot instances.
This game rule has both reasonable aspects and areas worthy of optimization. The author believes that at least it can be done better in the following aspects:
- If the SLA provided by the Spot recycling mechanism can encourage more users to use Spot instances, then the message notifications in the Spot recycling mechanism must provide a certain SLA, so that some key businesses can dare to use Spot instances on a large scale.
- Create new instance API to provide SLA After Spot is recycled, the application's backup plan is to continue to open new resources (such as new Spot instances or new On-demand instances). At this time, the API for opening new instances must also be certain. SLA, this SLA will directly affect the availability of the application.
- Detach cloud disks provide SLA. Detach EBS must also have a certain SLA, because once a Spot instance is forced to be recycled, users must be able to automatically handle the uninstallation of application status.
EC2 instance types | Price/month | Relative On Demand price ratio |
On Demand | $56.210 | 100% |
Spot | $24.747 | 44% |
Reserved 1YR | $35.259 | 63% |
Reserved 3YR | $24.455 | 44% |
AWS US EAST m6g.large
It is difficult for programmers to do a good job in resource recycling
C/C++ programmers spend a lot of energy fighting against memory, but they still cannot guarantee that memory resources will not be leaked. The reason is that accurate resource recycling is a very challenging thing. For example, if a function returns a pointer, then there is no agreement on who is responsible for recycling this object. C/C++ has no agreement. If multi-threading is involved, it will be even more nightmare. For this reason, C++ invented smart pointers, which manage objects through a thread-safe reference count. Java uses the built-in GC mechanism to detect object recycling at runtime, which completely solves the problem of object recycling, but it also brings a certain runtime overhead. The recently popular Rust language is essentially a smart pointer recycling method similar to C++. It innovatively integrates the memory recycling check mechanism into the compilation stage, thereby greatly improving the efficiency of memory recycling and avoiding common mistakes made by C/C++ programmers. Regarding memory issues, the author believes that Rust will be a perfect replacement for C/C++.
Returning to the field of cloud operating systems, programmers can create an ECS, a Kafka instance, and an S3 Object through an API. What this API brings about is a change in billing. Easy to create, very difficult to recycle. The maximum specifications are usually specified when creating. For example, when creating a Kafka instance, 20 machines are needed first. Because it will be difficult to expand or shrink in the future, it is better to do it all at once.
Although cloud computing provides elasticity, it is difficult for programmers to effectively manage resources on demand, making resource recycling difficult. This prompts enterprises to set up a cumbersome approval process when creating resources on the cloud, similar to the resource management method of traditional IDC. The final result is that the way programmers use resources on the cloud converges with IDC, which requires resource management through CMDB and relies on manual approval processes to avoid resource waste.
We’ve also seen some excellent examples of resilience practices. For example, when a large enterprise uses EC2, the lifetime of each EC2's Instance ID does not exceed one month. Once it exceeds, it will be classified as "grandfather's EC2" and will be on the team's black list. This is a great immutable infrastructure practice that can effectively prevent engineers from retaining state on the server, such as configuration, data, etc., thus making it feasible for applications to move toward elastic architecture.
The current stage of cloud computing is still in the C/C++ stage, and excellent resource recycling solutions have not yet emerged. Therefore, enterprises are still using a large number of process approval mechanisms, which essentially prevents enterprises from taking advantage of the greatest advantage of the cloud: elasticity. This is one of the main reasons for higher enterprise cloud spending.
I believe that as long as there is a problem, there will be a better solution, and a Java/Rust-like solution to cloud resource recycling will definitely come out in the near future.
From basic software to application layer, not yet ready for elasticity
The author began to design elastic solutions for thousands of applications on Taobao and Tmall in 2018 [3]. At that time, Taobao and Tmall's applications had mixed offline and online deployments to increase deployment density, but online applications were still in reserved mode. Unable to achieve on-demand elasticity. The fundamental problem is that the application may produce unexpected behavior when scaling. Even if it runs on Kubernetes, it still cannot be completely solved. For example, the application will call various middleware SDKs (database, cache, MQ, business cache, etc.) , the application itself also takes a long time to start. The seemingly stateless application actually contains various states, such as unit labels, grayscale labels, etc., so that the entire application requires a lot of manual operations, and manual observation can effectively scale it. Allow.
In order to improve Java applications from minute-level cold starts to milliseconds, the Snapshot capability [3] was developed for Docker at that time. The production application of this capability is 4 years ahead of AWS (AWS announced at the 2022 Re:invent conference Lambda SnapStart[4][5] feature released). Starting an application through Snapshot can add a computing node that can work immediately in hundreds of milliseconds. This capability allows the application to increase or decrease computing resources based on traffic like Lambda without transforming it into a Lambda function. This is the Pay as you go capability we saw provided by Lambda.
Implementing elasticity at the application layer is already so complex, and the challenge is even greater when it comes to providing elasticity for basic software, such as databases, caches, MQ, big data and other products. The requirements of distributed high availability and high reliability determine that these products need to store multiple copies of data. Once the amount of data is large, elasticity will become very difficult, and migrating data will affect the availability of the business. To this end, to solve this problem in the cloud environment, we must use cloud native methods. When we designed AutoMQ (the cloud native solution that empowers Kafka), we put elasticity as the highest priority. The core challenge is to offload storage to the cloud. Services, such as pay-as-you-go S3, rather than building your own storage system. The figure below is a diagram of the traffic and node changes on the AutoMQ line. You will see that AutoMQ automatically adds and removes machines based on traffic. If these machines use Spot instances, it will save a lot of costs for the enterprise and truly pay as you go.
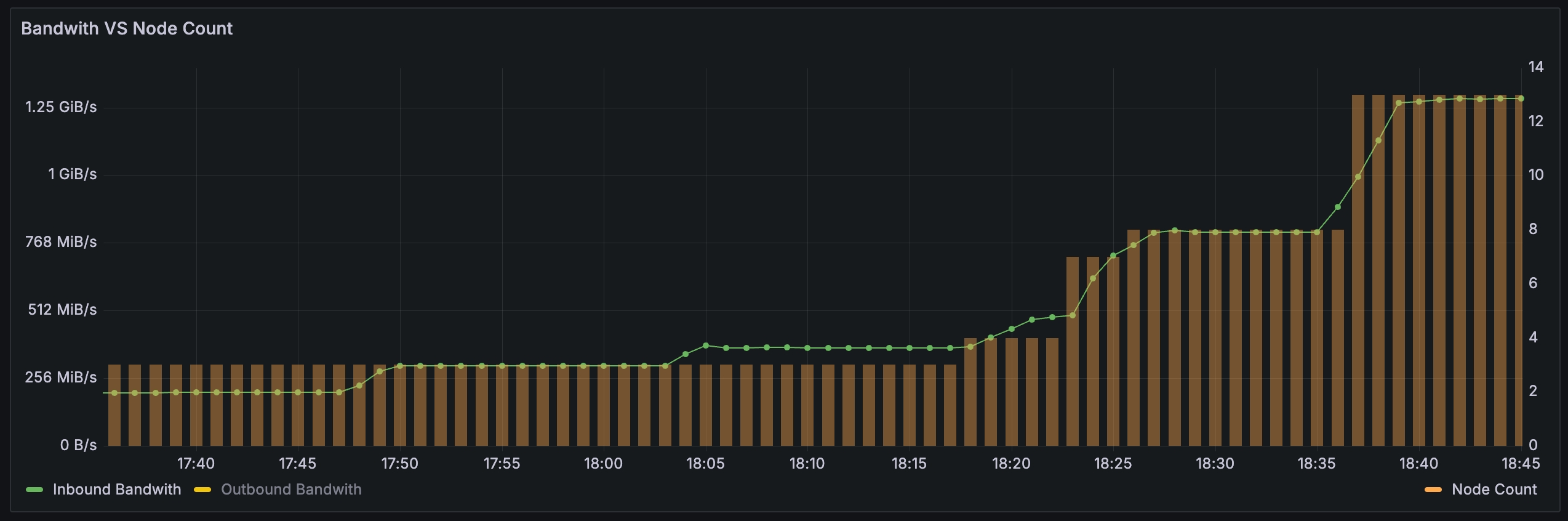
AutoMQ automatically increases and decreases nodes based on traffic
How companies can use flexible capabilities to reduce costs and increase efficiency
Google launched the Cloud Run [6] fully managed computing platform in 2018. Applications based on HTTP communication only need to provide listening ports and container images to Cloud Run, and all infrastructure management will be fully automatically performed by Cloud Run. The biggest advantage of this method compared to the AWS Lambda method is that it does not need to be bound to a single cloud vendor, and can be better migrated to other computing platforms in the future. Soon AWS and Azure followed up and launched similar products, Azure Container Apps[7] and AWS App Runner[8].
Leave professional matters to professionals. Elasticity is a very challenging task. It is recommended that applications on the cloud rely as much as possible on these codeless binding hosting frameworks, such as Cloud run, so that the computing resources consumed by the application can be processed according to the request. Come and pay.
Basic software such as databases, caches, big data, MQ, etc. are difficult to solve with a unified hosting framework. The evolution trend of this type of applications is that each category is evolving towards elastic architecture, such as Amazon Aurora Serverless, Mongodb Serverless[9 ], there is a consensus from cloud vendors to third-party open source software vendors that they need to achieve a completely elastic architecture.
When enterprises choose similar open source basic software, they should try their best to choose products with elastic capabilities. The criteria for judgment are whether they can run on Spot instances and whether they are highly cost-effective. At the same time, attention should also be paid to whether such products can run better on multiple clouds, which determines whether enterprises are portable when moving to multi-cloud architecture or even hybrid cloud architecture in the future.