nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!

Domain background
Autonomous driving systems need to make correct decisions in complex driving scenarios to ensure driving safety and comfort. Typically, autonomous driving systems integrate multiple tasks such as detection, tracking, online mapping, motion prediction, and planning. As shown in Figure 1a, the traditional modular paradigm splits complex systems into multiple individual tasks, each of which is optimized independently. In this paradigm, manual post-processing is required between independent single-task modules, which makes the entire process more cumbersome. On the other hand, due to the loss of scene information compression between stacked tasks, errors in the entire system will gradually accumulate, which may lead to potential safety issues.
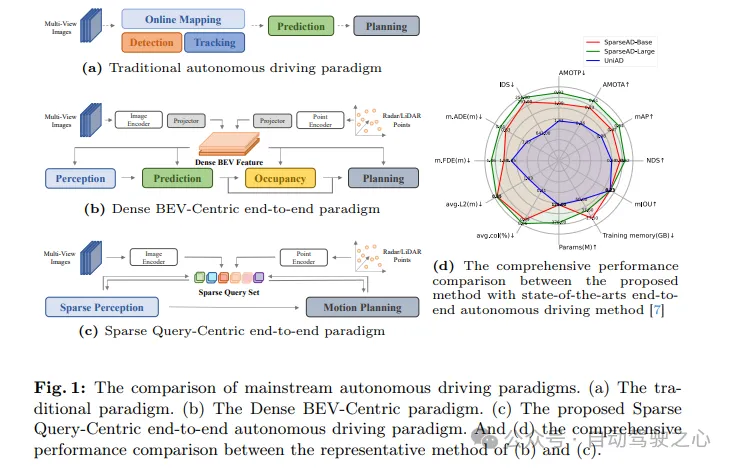
Regarding the above issues, end-to-end autonomous driving systems take raw sensor data as input and return planning results in a more concise way. Early work proposed skipping intermediate tasks and predicting planning results directly from raw sensor data. Although this approach is more straightforward, it is not satisfactory in terms of model optimization, interpretability, and planning performance. Another multi-faceted paradigm with better interpretability is to integrate multiple parts of autonomous driving into a modular end-to-end model, which introduces multi-dimensional supervision to improve the understanding of complex driving scenarios, And brings the ability to multi-task.
Specifically, the modular end-to-end architecture is redesigned and reduced to a concise structure consisting of sparse sensing and motion planners. In the sparse perception module, a universal temporal decoder is utilized to unify perception tasks including detection, tracking and online mapping. In this process, multi-sensor features and historical memories are treated as tokens, while object queries and map queries represent obstacles and road elements in the driving scene respectively. In the motion planner, sparse perception queries are used as environment representations, and multi-modal motion predictions are performed on the self-vehicle and surrounding agents simultaneously to obtain multiple initial planning solutions for the self-vehicle. Subsequently, multi-dimensional driving constraints are fully considered to generate the final planning results.
Main contributions:
- propose a novel sparse query-centric end-to-end autonomous driving paradigm (SparseAD), which abandons the traditional dense bird's-eye view (BEV) representation method and thus has great potential to efficiently scale to more Modalities and tasks.
- Simplify the modular end-to-end architecture into sparse sensing and motion planning. In the sparse perception part, perception tasks such as detection, tracking, and online mapping are unified in a completely sparse manner; while in the motion planning part, motion prediction and planning are carried out under a more reasonable framework.
- 在具有挑战性的nuScenes数据集上,SparseAD在端到端方法中取得了最先进的性能,并显著缩小了端到端范式与单任务方法之间的性能差距。这充分证明了所提出的稀疏端到端范式具有巨大的潜力。SparseAD不仅提高了自动驾驶系统的性能和效率,还为未来的研究和应用提供了新的方向和可能性。
SparseAD network structure
As shown in Figure 1c, in the proposed sparse query-centered paradigm, different sparse queries fully represent the entire driving scene, not only responsible for information transfer and interaction between modules, but also in multi-tasking in an end-to-end manner. Propagate inverse gradients for optimization. Different from previous dense bird's-eye view (BEV)-centric methods, no view projection and dense BEV features are used in SparseAD, thus avoiding heavy computational and memory burdens. The detailed architecture of SparseAD is shown in Figure 2.
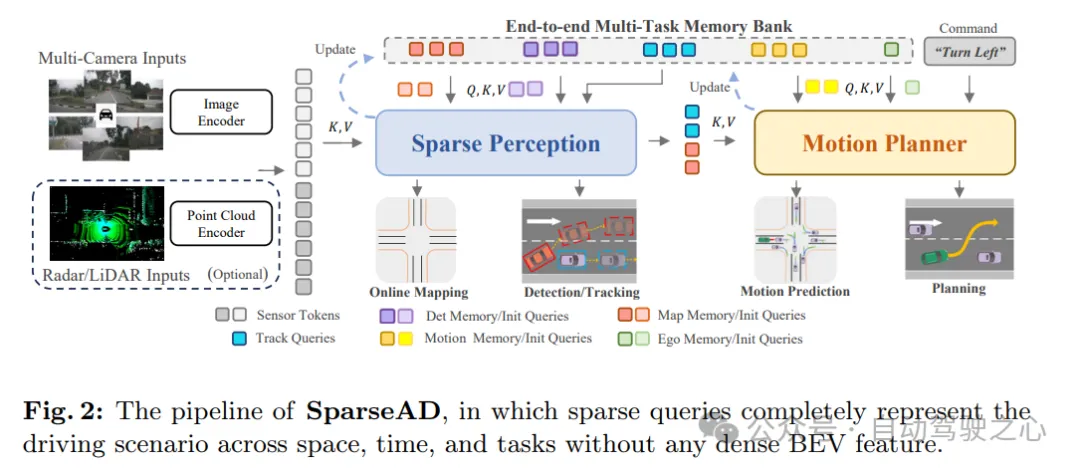
From the architectural diagram, SparseAD mainly consists of three parts, including sensor encoder, sparse perception and motion planner. Specifically, the sensor encoder takes as input multi-view camera images, radar or lidar points and encodes them into high-dimensional features. These features are then input into the sparse sensing module as sensor tokens along with position embeddings (PE). In the sparse sensing module, raw data from sensors will be aggregated into a variety of sparse sensing queries, such as detection queries, tracking queries, and map queries, which respectively represent different elements in the driving scene and will be further propagated to downstream tasks. In the motion planner, the perception query is treated as a sparse representation of the driving scene and is fully exploited for all surrounding agents and the self-vehicle. At the same time, multiple driving constraints are considered to generate a final plan that is both safe and dynamically compliant.
In addition, an end-to-end multi-task memory library is introduced in the architecture to uniformly store the timing information of the entire driving scene, which allows the system to benefit from the aggregation of long-term historical information to complete full-stack driving tasks.
As shown in Figure 3, SparseAD’s sparse perception module unifies multiple perception tasks, including detection, tracking, and online mapping, in a sparse manner. Specifically, there are two structurally identical temporal decoders that exploit long-term historical information from the memory bank. One of the decoders is used for obstacle sensing and the other is used for online mapping.
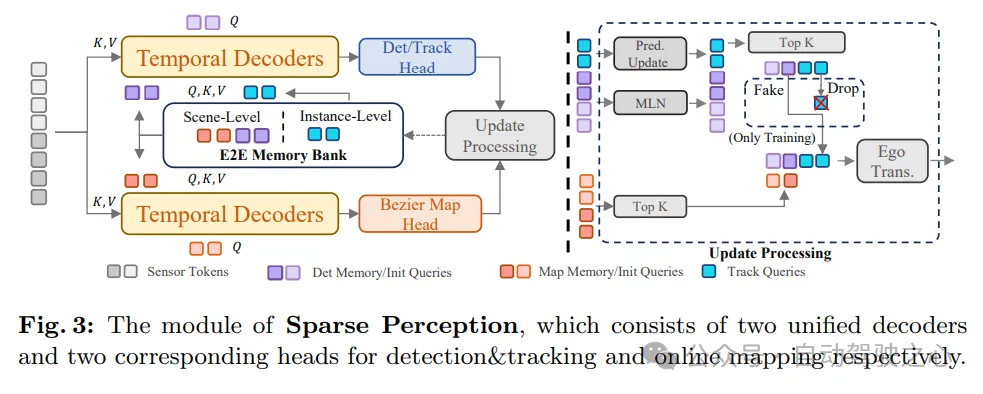
After aggregating information through perception queries corresponding to different tasks, the detection and tracking heads and the map part are used to decode and output obstacles and map elements respectively. After that, an update process is performed, which filters and saves the high-confidence sensing query of the current frame and updates the memory bank accordingly, which will benefit the sensing process of the next frame.
In this way, SparseAD's sparse perception module achieves efficient and accurate perception of the driving scene, providing an important information basis for subsequent motion planning. At the same time, by utilizing historical information in the memory bank, the module can further improve the accuracy and stability of perception and ensure the reliable operation of the autonomous driving system.
sparse perception
Online map construction is a complex and important task. According to current knowledge, existing online map construction methods mostly rely on dense bird's-eye view (BEV) features to represent the driving environment. This approach has difficulties in extending the sensing range or leveraging historical information because it requires large amounts of memory and computing resources. We firmly believe that all map elements can be represented in a sparse manner, therefore, we try to complete online map construction under the sparse paradigm. Specifically, the same temporal decoder structure as in the obstacle perception task is adopted. Initially, map queries with prior categories are initialized to be uniformly distributed on the driving plane. In the temporal decoder, map queries interact with sensor markers and historical memory markers. These historical memory markers are actually composed of highly confident map queries from previous frames. The updated map query then carries valid information about the map elements of the current frame and can be pushed to the memory bank for use in future frames or downstream tasks.
Obviously, the process of online map construction is roughly the same as obstacle perception. That is, sensing tasks including detection, tracking, and online map construction are unified into a common sparse approach that is more efficient when scaling to larger ranges (e.g., 100m × 100m) or long-term fusion , and does not require any complex operations (such as deformable attention or multi-point attention). To the best of our knowledge, this is the first to implement online map construction in a unified perception architecture in a sparse manner. Subsequently, the piecewise Bezier map Head is used to return the piecewise Bezier control points of each sparse map element, and these control points can be easily transformed to meet the requirements of downstream tasks.
Motion Planner
We revisit the problem of motion prediction and planning in autonomous driving systems and find that many previous methods ignore the dynamics of the ego-vehicle when predicting the motion of surrounding vehicles. While this may not be apparent in most situations, it can be a potential risk in scenarios such as intersections where there is close interaction between nearby vehicles and the host vehicle. Inspired by this, a more reasonable motion planning framework was designed. In this framework, the motion predictor predicts the motion of surrounding vehicles and the own vehicle simultaneously. Subsequently, the prediction results of the own vehicle are used as motion priors in subsequent planning optimizers. During the planning process, we consider different aspects of constraints to produce a final planning result that meets both safety and dynamics requirements.
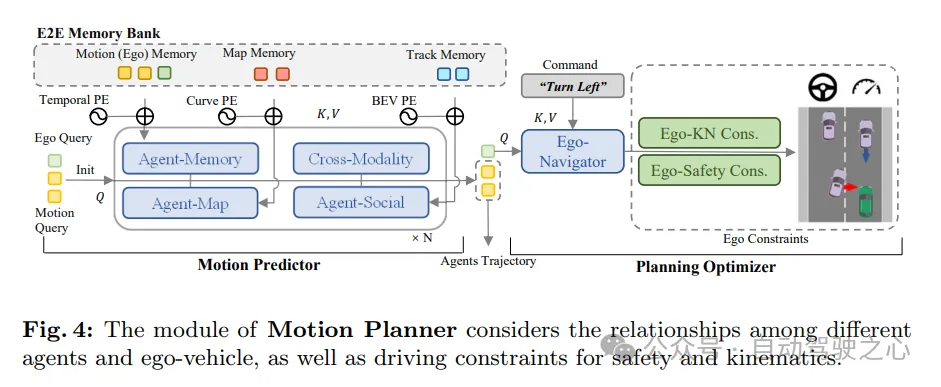
As shown in Figure 4, the motion planner in SparseAD treats perception queries (including trajectory queries and map queries) as a sparse representation of the current driving scene. Multimodal motion queries are used as a medium to enable understanding of driving scenarios, perception of interactions between all vehicles (including the own vehicle), and gaming of different future possibilities. The vehicle's multimodal motion query is then fed into a planning optimizer, which takes into account driving constraints including high-level instructions, safety and dynamics.
Motion predictor . Following previous methods, the perception and integration between motion queries and current driving scene representations (including trajectory queries and map queries) are achieved through standard transformer layers. In addition, self-vehicle agent and cross-modal interaction are applied to jointly model the interaction between surrounding agents and the self-vehicle in future spatio-temporal scenes. Through module synergy within and between multi-layer stacking structures, motion queries are able to aggregate rich semantic information from both static and dynamic environments.
In addition to the above, two strategies are introduced to further improve the performance of the motion predictor. First, a simple and straightforward prediction is made using the instance-level temporal memory of the trajectory query as part of the initialization of the surrounding agent motion query. In this way, motion predictors are able to benefit from prior knowledge gained from upstream tasks. Second, thanks to the end-to-end memory library, useful information can be assimilated from the saved historical motion queries in a streaming manner through the agent memory aggregator at almost negligible cost.
It should be noted that the multi-modal motion query of the vehicle is updated at the same time. In this way, the motion prior of the own vehicle can be obtained, which can further facilitate the planning learning process.
Planning optimizer . With the motion prior provided by the motion predictor, better initialization is obtained, resulting in fewer detours during training. As a key component of the motion planner, the design of the cost function is crucial as it will greatly affect or even determine the quality of the final performance. In the proposed SparseAD motion planner, two major constraints, safety and dynamics, are mainly considered, aiming to generate satisfactory planning results. Specifically, in addition to the constraints determined in VAD, it also focuses on the dynamic safety relationship between the vehicle and nearby agents, and considers their relative positions in future moments. For example, if agent i continues to remain in the front left area relative to the vehicle, thereby preventing the vehicle from changing lanes to the left, then agent i will obtain a left label, indicating that agent i imposes a leftward constraint on the vehicle. Constraints are therefore classified as front, back, or none in the longitudinal direction, and as left, right, or none in the transverse direction. In the planner, we decode the relationship between other agents and the vehicle in the horizontal and vertical directions from the corresponding query. This process involves determining the probabilities of all constraints between other agents and the own vehicle in these directions. Then, we utilize focal loss as the cost function of the Ego-Agent relationship (EAR) to effectively capture the potential risks brought by nearby agents:
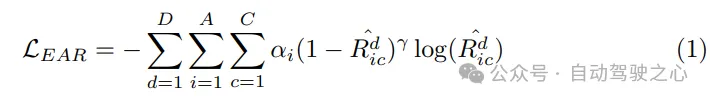
Since the planned trajectory must follow the dynamic laws executed by the control system, auxiliary tasks are embedded in the motion planner to promote the learning of the vehicle's dynamic state. Decode states such as speed, acceleration, and yaw angle from the own vehicle query Qego, and use dynamics losses to supervise these states:
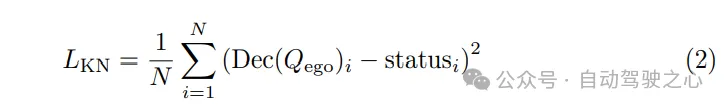
Experimental results
Extensive experiments are conducted on the nuScenes dataset to demonstrate the effectiveness and superiority of the method. To be fair, the performance of each complete task will be evaluated and compared with previous methods. The experiments in this section use three different configurations of SparseAD, namely SparseAD-B and SparseAD-L that only use image input, and SparseAD-BR that uses radar point cloud and image multi-modal input. Both SparseAD-B and SparseAD-BR use V2-99 as the image backbone network, and the input image resolution is 1600 × 640. SparseAD-L further uses ViTLarge as the image backbone network, and the input image resolution is 1600×800.
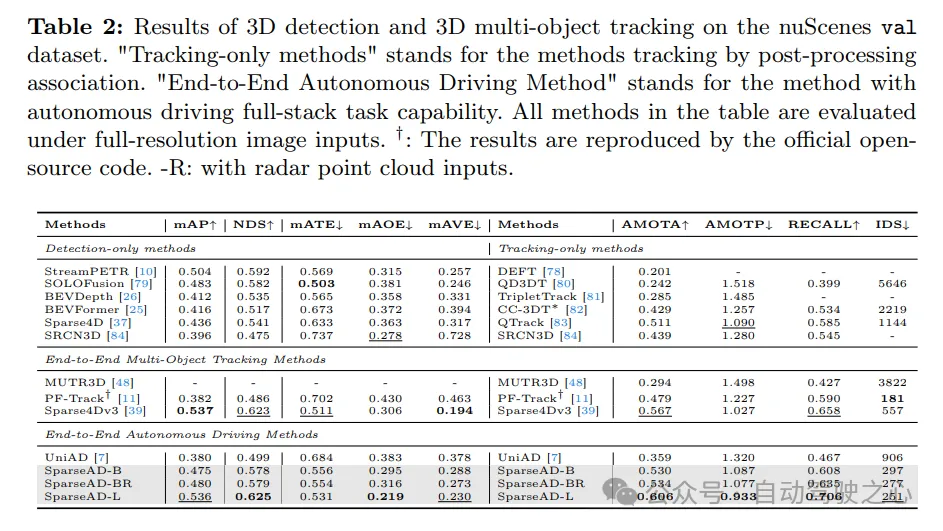
The 3D detection and 3D multi-target tracking results on the nuScenes validation dataset are as follows. "Tracking only methods" refers to methods that are tracked through post-processing correlation. “End-to-end autonomous driving method” refers to a method that is capable of full-stack autonomous driving tasks. All methods in the table are evaluated with full resolution image input. †: The results are reproduced through official open source code. -R: Indicates that radar point cloud input is used.
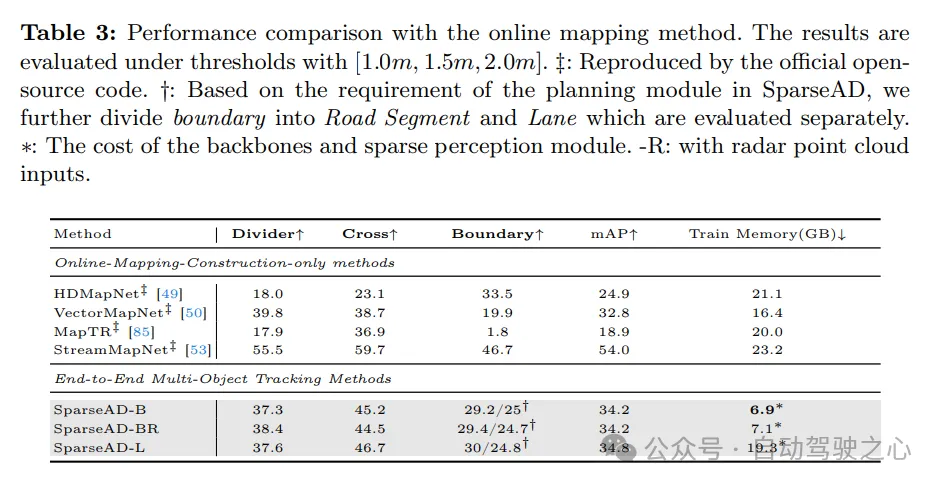
The performance comparison with the online mapping method is as follows, the results are evaluated at the threshold of [1.0m, 1.5m, 2.0m]. ‡: Result reproduced through official open source code. †: Based on the needs of the planning module in SparseAD, we further subdivided the boundary into road segments and lanes and evaluated them separately. ∗: Cost of backbone network and sparse sensing module. -R: Indicates that radar point cloud input is used.
Multi-Task results
Obstacle perception . The detection and tracking performance of SparseAD is compared with other methods on the nuScenes validation set in Tab. 2. Obviously, SparseAD-B performs well in most popular detection-only, tracking-only and end-to-end multi-object tracking methods, while performing equivalently to SOTA methods such as StreamPETR and QTrack on the corresponding tasks. By scaling up with a more advanced backbone network, SparseAD-Large achieves overall better performance, with mAP of 53.6%, NDS of 62.5%, and AMOTA of 60.6%, which is overall better than the previous best method Sparse4Dv3.
planning . The results of the planning are presented in Tab. 4b. Thanks to the superior design of the upstream perception module and motion planner, all versions of SparseAD achieve state-of-the-art performance on the nuScenes validation dataset. Specifically, SparseAD-B achieves the lowest average L2 error and collision rate compared to all other methods including UniAD and VAD, which demonstrates the superiority of our approach and architecture. Similar to upstream tasks including obstacle perception and motion prediction, SparseAD further improves performance with radar or a more powerful backbone network.