突破性的百萬視頻和語言世界模型:Large World Model~

本文經自動駕駛之心公眾號授權轉載,轉載請洽出處。
在探索如何讓AI更好地理解世界方面,最近的一項突破性研究引起了廣泛關注。來自加州大學柏克萊分校的研究團隊發布了“Large World Model, LWM”,能夠同時處理百萬長度的影片和語言序列,實現了對複雜場景的深入理解。這項研究無疑為未來AI的發展開啟了新的篇章。
論文地址:World Model on Million-Length Video And Language With RingAttention

部落格網址:Large World Models
Huggingface:LargeWorldModel(大世界模型)
在傳統方法中,AI模型往往只能處理較短的文字或影片片段,缺乏對長時間複雜場景的理解能力。然而,現實世界中的許多場景,如長篇書籍、電影或電視劇,都包含了豐富的訊息,需要更長的脈絡來深入理解。為了應對這項挑戰,LWM團隊採用了環形注意力(RingAttention)技術,成功擴展了模型的上下文窗口,使其能夠處理長達100萬個令牌(1M tokens)的序列。例如實現超過1 小時的問答影片:

圖1.長視頻理解。LWM 可以回答有關超過1 小時的YouTube 影片的問題。
超過1M 上下文的事實檢索:
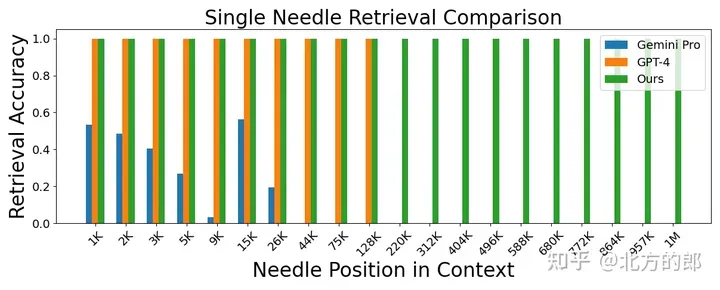
圖2. 針檢索任務。LWM 在1M 上下文視窗內實現了高精度,且效能優於GPT-4V 和Gemini Pro。
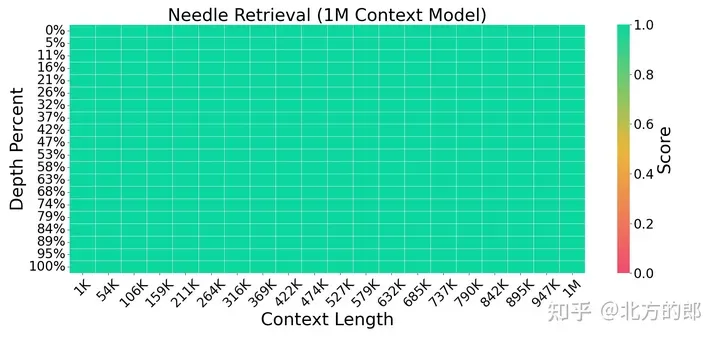
圖3. 針檢索任務。LWM 對於上下文視窗中不同的上下文大小和位置實現了高精度。
技術實現
為了訓練和評估LWM,研究人員首先收集了一個包含各種影片和書籍的大型資料集。然後,他們逐步增加了訓練的上下文長度,從4K tokens開始,逐步擴展到1M tokens。這個過程不僅有效降低了訓練成本,還使模型能夠逐步適應更長序列的學習。在訓練過程中,研究人員還發現,混合不同長度的圖像、影片和文字資料對於模型的多模態理解至關重要。具體包括:
模型訓練分兩個階段:先透過訓練大型語言模型擴展上下文大小。然後進行視訊和語言的聯合訓練。
第一階段:學習長上下文語言模型
擴展上下文:利用RingAttention技術,可以無近似地擴展上下文長度到數百萬個token。同時,透過逐步增加訓練序列長度,從32K tokens開始,逐步增加到1M tokens,以減少計算成本。此外,為了擴展位置編碼以適應更長的序列,採用了簡單的方法,即隨上下文視窗大小增加而增加RoPE中的θ。
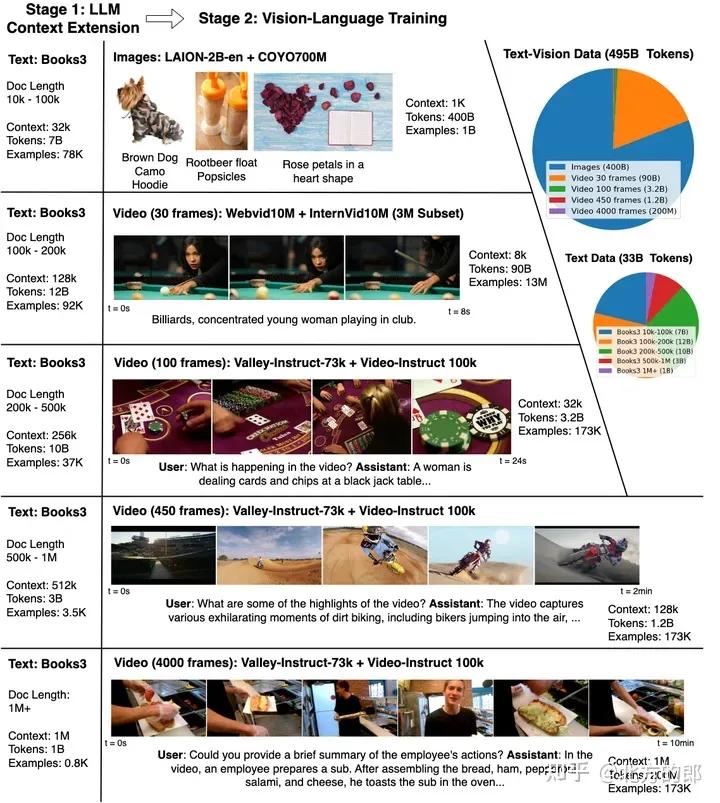
情境擴展和視覺語言訓練。使用RingAttention 將書籍上的上下文大小從4K 擴展到1M,然後對長度為32K 到1M 的多種形式的視覺內容進行視覺語言訓練。下面板顯示了理解和回應有關複雜多模式世界的查詢的互動功能。
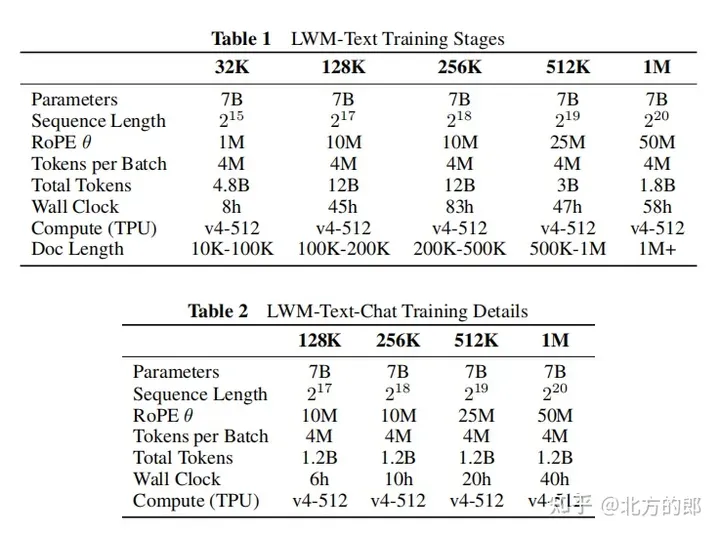
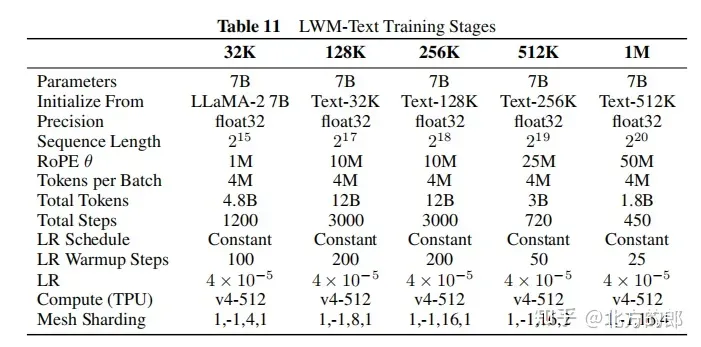
訓練步驟:先從LLaMA-2 7B模型初始化,然後在5個階段逐步增加上下文長度,分別是32K、128K、256K、512K和1M tokens。每個階段都使用不同過濾版本的Books3資料集進行訓練。隨著上下文長度的增加,模型能夠處理更多tokens。
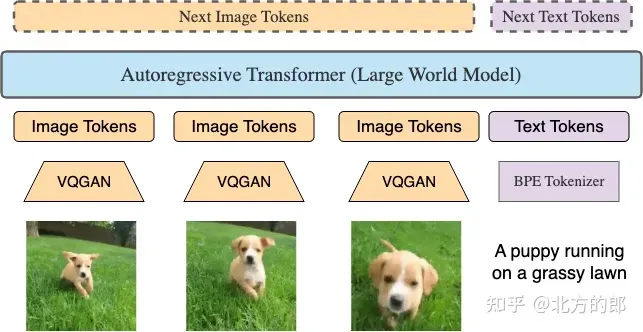
任意對任意長序列預測。RingAttention 能夠使用非常大的上下文視窗進行跨視訊-文字、文字-視訊、圖像-文字、文字-圖像、純視訊、純圖像和純文字等多種格式的訓練。請參閱LWM 論文以了解關鍵功能,包括屏蔽序列打包和損失加權,它們可以實現有效的視訊語言訓練。
對話微調:為了學習長上下文的對話能力,建構了一個簡單的問答資料集,將Books3資料集的文件分割成1000 token的區塊,然後利用短上下文語言模型為每個區塊產生一個問答對,最後將相鄰的區塊連接起來建構一個長上下文的問答範例。在微調階段,模型在UltraChat和自訂問答資料集上進行訓練,比例為7:3。
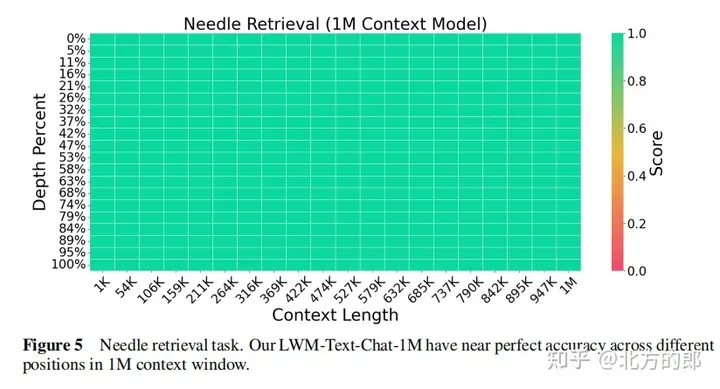
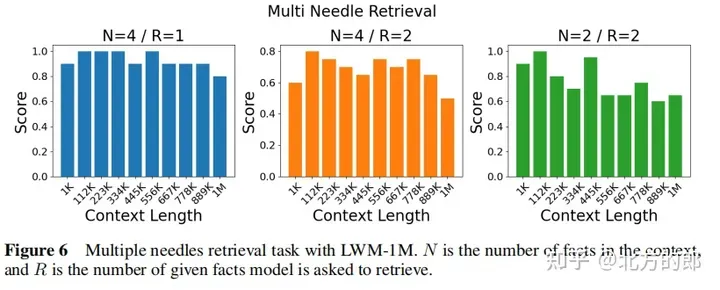
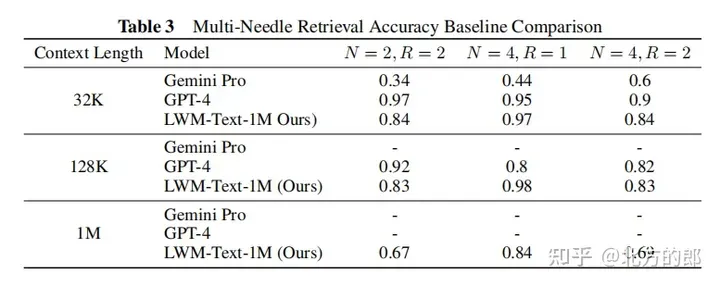
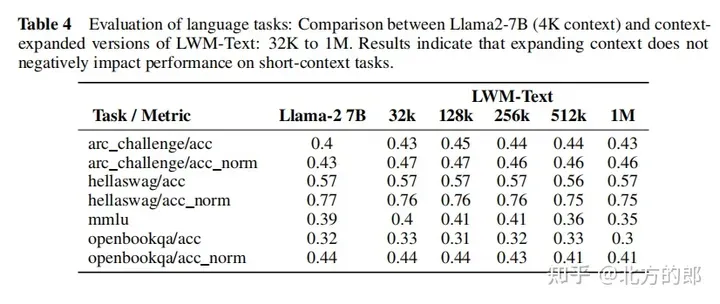
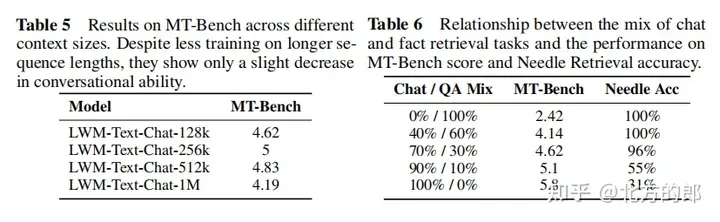
語言評估結果:在單針檢索任務中,1M情境的模型可以在整個情境中近乎完美地檢索出隨機分配給隨機城市的數字。在多針檢索任務中,模型在檢索一個針時表現良好,在檢索多個針時表現略有下降。在短上下文語言任務評估中,擴大上下文長度並沒有降低效能。在對話評估中,增加對話互動能力可能會降低系統檢索特定資訊或「針」的精確度。
第二階段:學習長上下文視覺語言模型
架構修改:在第一階段的基礎上,對LWM和LWM-Chat進行修改,使其能夠接受視覺輸入。具體來說,使用預訓練的VQGAN將256x256的輸入影像轉換為16x16的離散token,對視訊進行逐幀的VQGAN編碼並將編碼連接起來。此外,引入了特殊的標記符號和來區分文字和視覺token,以及和來標記圖像和視訊畫面的結束。
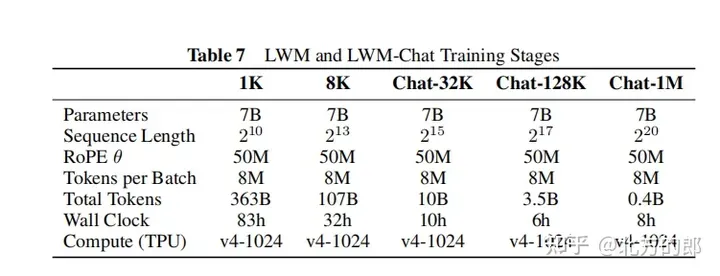

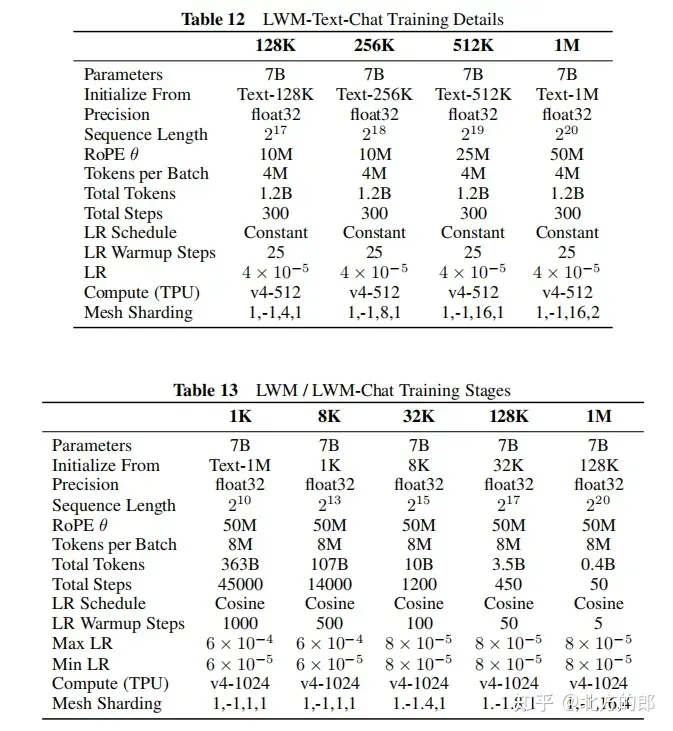
訓練步驟:從LWM-Text-1M模型初始化,採用與第一階段類似的逐步增加序列長度的訓練方法,首先在1K tokens上訓練,然後是8K tokens,最後是32K、128K和1M tokens。訓練數據包括文字-圖像對、文字-視訊對以及下游任務的聊天數據,如文字-圖像生成、圖像理解、文字-視訊生成和視訊理解。在訓練過程中,逐步增加下游任務的混合比例。
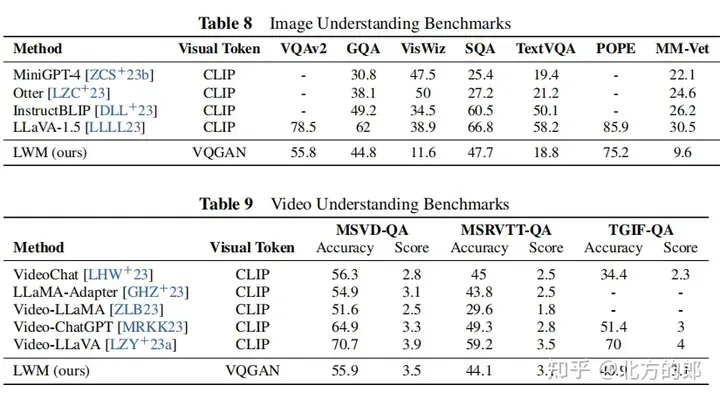
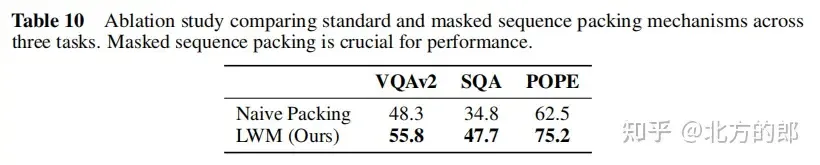
視覺-語言評估結果:在長影片理解方面,模型能夠處理長達1小時的YouTube影片並準確回答問題,相較於現有模型具有明顯優勢。在圖像理解和短視頻理解方面,模型表現一般,但透過更嚴格的訓練和更好的分詞器,有潛力改進。在圖像和視訊生成方面,模型可以從文字生成圖像和視訊。Ablation研究表明,屏蔽序列填充對於影像理解等下游任務至關重要。


文字到圖像。LWM 根據文字提示以自迴歸方式產生影像。
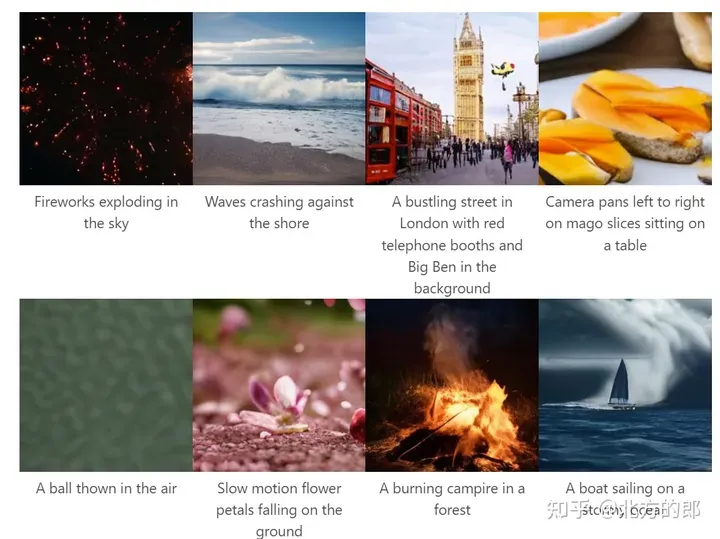
文字到影片。LWM 根據文字提示以自回歸方式產生影片。
第二階段透過逐步增加序列長度並在大量文字-圖像和文字-視訊資料上訓練,成功擴展了第一階段的語言模型,使其具備視覺理解能力。這階段的模型可以處理長達1M tokens的多模態序列,並在長視訊理解、影像理解和生成等方面展現出強大的能力。
技術細節(Further Details)
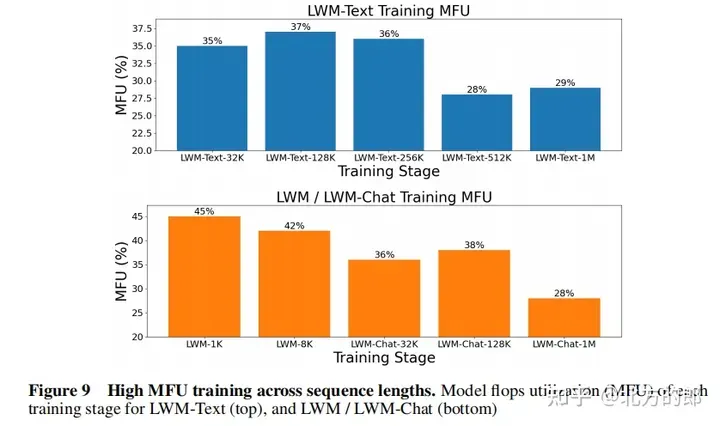
訓練運算資源:模型使用TPUv4-1024進行訓練,相當於450個A100 GPU,使用FSDP進行資料並行,並透過RingAttention支援大上下文。
訓練損失曲線:圖10和圖11展示了第一階段語言模型和第二階段視覺-語言模型的訓練損失曲線。可以看出,隨著訓練進行,損失持續下降。
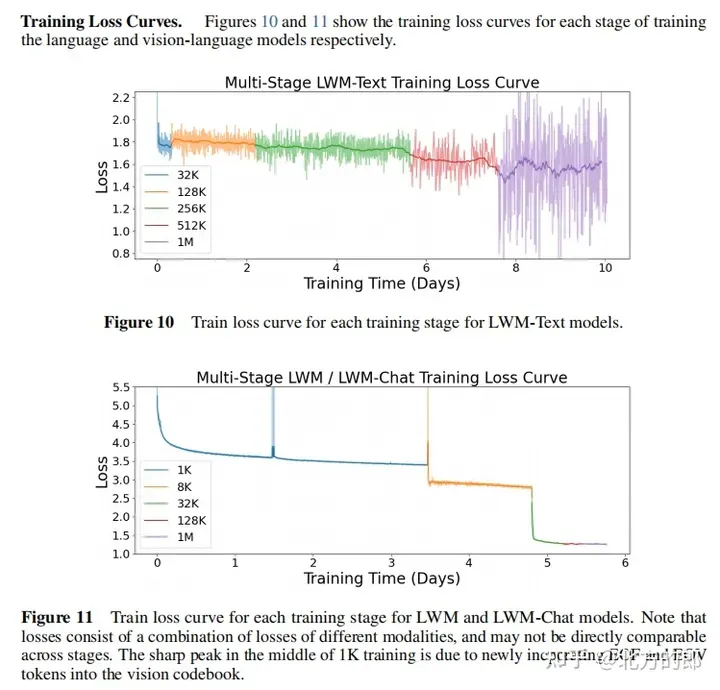
訓練超參數:附錄F提供了詳細的訓練超參數,包括參數量、初始化模型、序列長度、RoPE參數、每批tokens數、總tokens數、訓練步驟數、學習率計畫、學習率預熱步數、最大學習率和最小學習率、運算資源等。
推斷擴展:實現了RingAttention用於解碼,支援對長達數百萬tokens的序列進行推斷,需使用至少v4-128 TPU,並進行32路tensor並行和4路序列並行。

量化:文件指出,模型使用單一精度進行推斷,透過量化等技術可以進一步提高擴展性。
一些例子
基於圖像的對話。

圖6. 影像理解。LWM 可以回答有關影像的問題。
超過1 小時的YouTube 視訊視訊聊天。

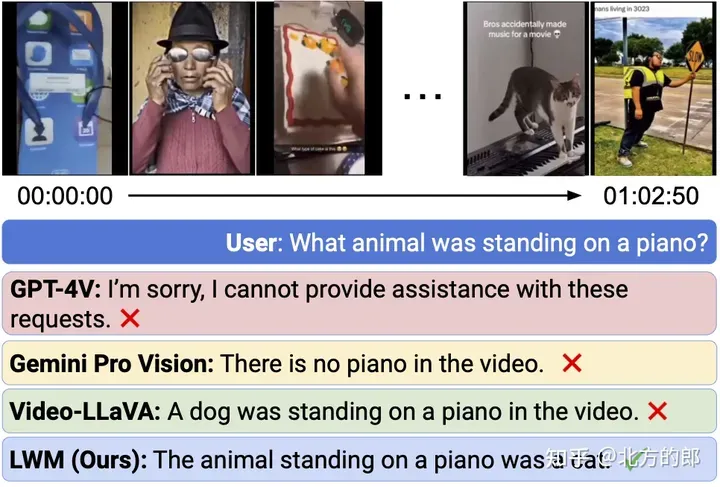
圖7. 長視訊聊天。
即使最先進的商業模式GPT-4V 和Gemini Pro 都失敗了,LWM 仍能回答有關1 小時長的YouTube 影片的問題。每個範例的相關片段位於時間戳記9:56(上)和6:49(下)。