Sora was actually trained using this data? OpenAI CTO’s confession sparks outrage

OpenAI's Sora was born in February this year, taking Vincent Video to a new stage. It can generate surreal scenes based on text prompts. The applicable population of Sora is limited, but Sora is everywhere on various media platforms, and everyone is looking forward to using it.
In interviews over the past few days, the three authors revealed more details about Sora, including that it still has difficulties handling hands, but is being optimized. They also elaborated on more optimization directions of Sora, so that users can have more precise control over the video screen. However, Sora won’t be available to the public anytime soon. After all, Sora is able to generate videos that are very close to reality, which raises a lot of questions. And because of this, it needs more improvements and more time for people to adapt.
But don’t be discouraged, this short term may not last long. OpenAI Chief Technology Officer Mira Murati was interviewed by Wall Street Journal technology columnist Joanna Stern. When talking about when Sora will be launched, she revealed that Sora will be launched this year, and everyone may have to wait a few months, everything depends on the progress of the red team.
OpenAI also plans to add the audio generation function to Sora to make the video generation effect more realistic. Next, they will continue to optimize Sora, including the consistency between frames, the ease of use of the product, and the cost. OpenAI also hopes to add the ability for users to edit Sora-generated videos. After all, the results of AI tools are not 100% accurate. If users can recreate on the basis of Sora, they will surely have better video effects and more accurate content expression.
Of course, the in-depth and simple explanation of technology is only part of the interview. The other part always revolves around popular topics such as safety and worries. For example, a 20-second 720p video does not take hours to generate but only takes a few minutes. What measures will Sora take in terms of security?
During the interview, the host also deliberately brought the topic to Sora training data. Mira Murati said that Sora has been trained on publicly available and licensed data . When reporters asked whether videos on YouTube were used, Mira Murati said she was not sure. The reporter asked again whether videos on Facebook or Instagram were used? Mira Murati replied that if they were publicly available, they might become part of the database, but I'm not sure, I can't say for sure.
In addition, she also admitted that Shutterstock (an American provider of photo libraries, image materials, image music and editing tools) is one of the sources of training data, and also emphasized their cooperative relationship.
However, it seemed like an ordinary interview, but it also caused a lot of controversy. Many people accused Mira Murati of not being candid enough:

Others speculated that Murati was lying from his micro-expressions, saying, "Remember not to make yourself look like you are lying."
"I'm just curious. As the CTO of OpenAI, I don't know what kind of training data is used. Isn't this blatant lying?"
"As the CTO of such a company, how could she not be prepared to answer such a basic question? It's confusing..."
Others believe that Murati was not lying, and perhaps Facebook (FB) really allowed OpenAI to use some data.
But this statement was immediately refuted, "Is Facebook crazy? This data is absolutely priceless to Facebook. Why would they sell or license the data to their biggest competitor? This is actually what they are doing in GenAI. The only competitive advantage in the competition.”
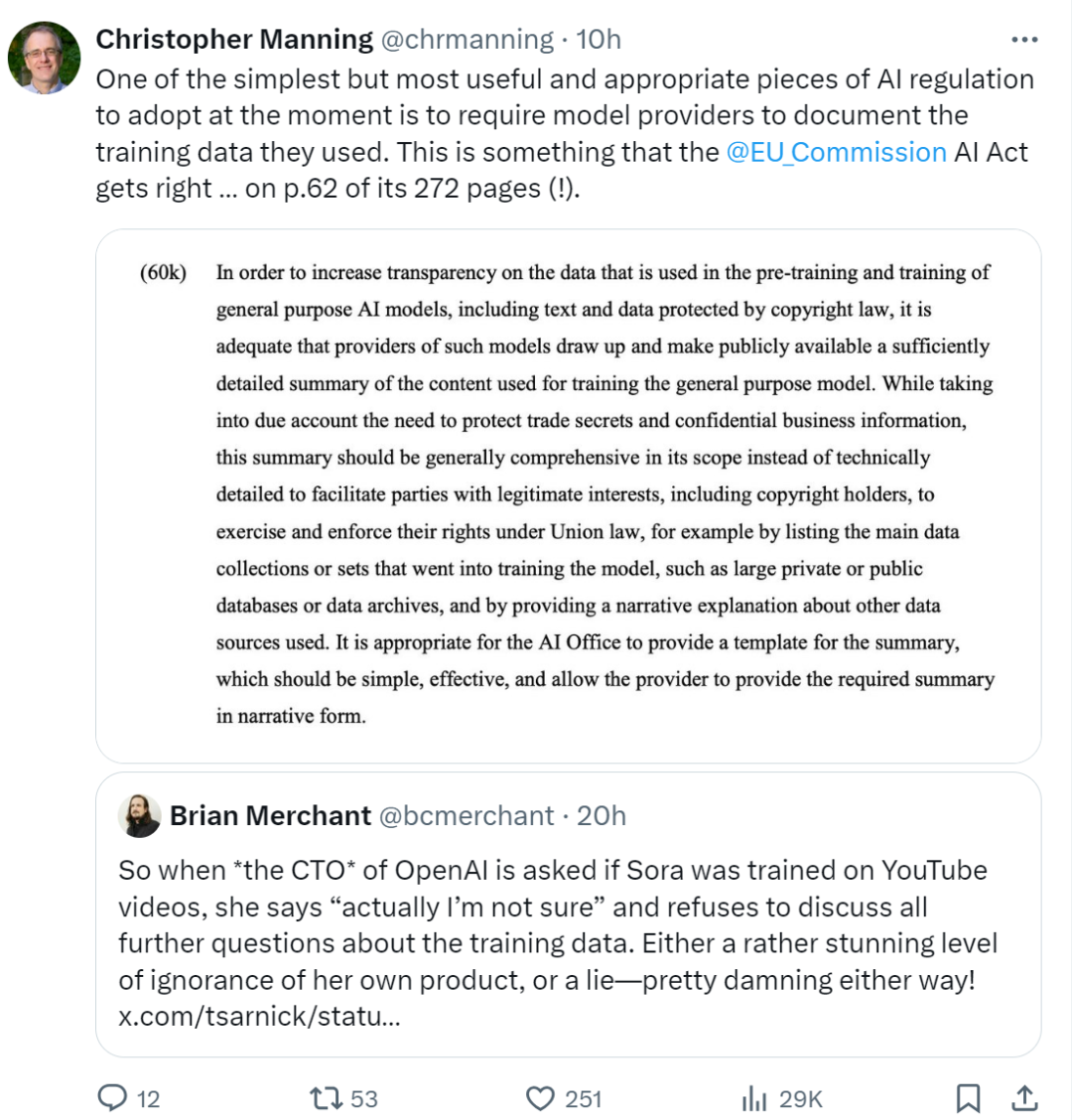
Obviously, many people think Murati is not telling the truth: "As OpenAI's chief technology officer, when asked whether Sora had been trained on YouTube videos, she said she was not sure and refused to discuss further questions about the training data. Either she's completely ignorant about her product, or she's lying - either way it's disgusting."
This has to bring the topic to another level: copyright issues. OpenAI has always been troubled by data copyright. Some time ago, the New York Times filed a complaint against OpenAI in court. In the indictment, the New York Times listed the GPT-4 output as "plagiarism" of the New York Times. "Evidence", many of GPT-4's answers are almost identical to the passages reported by the "New York Times".
How to solve data governance issues? Stanford professor Manning said, "One of the simplest but most useful and appropriate AI regulations currently is to require model providers to record the training data they use. The Artificial Intelligence Act that has just been passed and approved by the European Parliament also emphasizes this point. "
Source: https://twitter.com/chrmanning/status/1768311283445796946
What data did OpenAI use to train Sora? Now it seems that the tip of this huge iceberg has emerged. In addition to the data issues that everyone is concerned about, this interview also has more information that is worth reading.
The following is the main content of this interview, which has been edited to maintain the original meaning:

Reporter: I’m blown away by AI-generated videos, but I’m also worried about their impact. So I asked OpenAI to do a new video and sat down with Murati to answer some questions. How does Sora work?
Mira Murati : It's fundamentally a diffusion model, it's a generative model. It creates an image starting from random noise. If it's a film production, one has to make sure that one frame carries over to the next, and that there's consistency between objects. This gives you a sense of reality and presence. If you break it between frames, you're disconnected and reality doesn't exist. This is what Sora does so well.
Reporter: Suppose I give a prompt now: "A female video producer was holding a movie camera on the sidewalk in New York City. Suddenly, a robot stole the camera from her hand."

Mira Murati : You can see that it doesn't follow the prompts very faithfully. Instead of the robot pulling the camera out of her hands, the person turned into a robot. This leaves a lot to be desired.
Reporter: One thing I also noticed is that when cars pass by, they change color.
Mira Murati : Yeah, so while this model is great at continuity, it's not perfect. So you'll see the yellow taxi disappear from the frame for a moment, and then it comes back in a different form.
Reporter: Can we issue an instruction like "make the taxi consistent and let it come back" after it is generated?
Mira Murati : There is no way now, but we are working hard on it: how to turn it into a tool that people can edit and use to create.
Reporter: What do you think is the prompt of the video below?

Mira Murati : Is a bull in a china shop? You can see it being stepped on, but nothing is broken. In fact, this should be predictable. We will improve stability and controllability in the future to make it more accurately reflect your intentions.
Reporter: And then there is a video where the woman on the left looks like she has about 15 fingers in one shot.

Mira Murati : Hands actually have their own way of moving. And it’s difficult to simulate hand movements.
Reporter: The characters in the video have mouth movements, but there is no sound. Has Sora done his homework on this?
Mira Murati : There is indeed no sound at the moment, but there will definitely be one in the future.
Reporter: What data did you use to train Sora?
Mira Murati: We used publicly available data and licensed data.
Reporter: Like videos on YouTube?
Mira Murati : I’m not sure about that.
Reporter: What about videos on Facebook or Instagram?
Mira Murati: If they were publicly available, they might become part of the data, but I'm not sure, I can't say for sure.
Reporter: What about Shutterstock? I know you have an agreement with them.
Mira Murati: I just don't want to go into detail about the data that was used, but it was publicly available or licensed data.
Reporter: How long does it take to generate a 20-second 720p video?
Mira Murati : Depending on the complexity of the prompt, it may take a few minutes. Our goal is to really focus on developing the best capabilities. Now we're going to start looking at optimizing the technology so that people can use it at low cost, making it easy to use.
Reporter: Creating these works definitely requires a lot of computing power. How much computing power does it take to generate something like this compared to a ChatGPT response or a dynamic image?
Mira Murati : ChatGPT and DALL・E are optimized for public use of them, while Sora is actually a research output and much more expensive. We didn't know at the time exactly what it would look like when it was eventually made available to the public, but we were trying to eventually make it available at a similar cost to DALL・E.
Reporter: When will it finally be? I'm really looking forward to it.
Mira Murati : Definitely this year, but probably in a few months.
Reporter: Do you think it will be before or after the November election?
Mira Murati : This is an issue that requires careful consideration in dealing with misinformation and harmful bias. We also won't publish anything that might affect elections or other issues that we don't have confidence in.
Reporter: There is something that cannot be generated.
Mira Murati : We haven't made those decisions yet, but I think our platform will remain consistent. So it should be similar to DALL・E, you can generate images of public figures. They will have similar Sora policies. Now that we're in exploration mode, we haven't figured out where all the limits are and how we're going to work around them.
Reporter: What about nudity?
Mira Murati : You know, there are some creative settings where the artist might want to have more control. Now we're working with artists and creators from different fields to figure out what kind of flexibility the tool should offer.
Reporter: How do you ensure that people testing these products are not being devoured by illegal or harmful content?
Mira Murati : It’s certainly difficult. In the early stages this is part of Red Teaming and you have to account for it and make sure people are willing and able to do it. We will learn more about this process as we work with contractors, but it is undoubtedly difficult.
Reporter: We are laughing at these videos now, but when this type of technology affects work, people in the video industry may not be laughing in a few years.
Mira Murati : I think it's a tool to expand creativity, and we want people in the film industry, creators wherever they are, to get involved and inform how we can further develop and deploy it. Also, what are the economics of using these models when people contribute data etc.
Reporter: What is clear from all of this is that technology will soon become faster, better, and more widely available. At that time, how to distinguish real videos from AI videos?
Mira Murati : We are also working on these issues, including adding watermarks to videos. But we need to first understand the source of the content and how people distinguish between real content, what happened in reality and false content. This is why we have not deployed these systems yet. These problems must be solved before large-scale deployment.
Reporter: With your words, I can feel more at ease. Still, people are very concerned that Silicon Valley’s efforts to raise money to create AI tools and their ambitions for money and power could endanger humanity.
Mira Murati : Balancing profit and safety is not really a difficult part. The real hard part is figuring out safety and social issues. This is the real reason why I persist.
Reporter: This product is indeed amazing, but it also causes a lot of concerns. We have also discussed it. Is it really worth it?
Mira Murati : Definitely worth it. AI tools will expand our knowledge and creativity, our collective imagination, our ability to do just about anything. In this process, it is also extremely difficult to find the right path to integrate AI into daily life, but I think it is definitely worth a try.
In the AI era, the first is talent, the second is data, and the third is computing power. While OpenAI has many talents in reserve, it will take time to provide an answer on how to solve data problems.