全球最強開源大模型一夜易主!GoogleGemma 7B碾壓Llama 2 13B,重燃開源之戰

一聲炸雷深夜炸響,Google居然也開源LLM了?!

這次,重磅開源的Gemma有2B和7B兩種規模,並且採用了與Gemini相同的研究和技術建構。

有了Gemini同源技術的加持,Gemma不僅在相同的規模下實現SOTA的性能。
而且更令人印象深刻的是,還能在關鍵基準上越級碾壓更大的車型,例如Llama 2 13B。
同時,Google也放出了16頁的技術報告。

技術報告網址:https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
Google表示,Gemma這個名字源自拉丁文「gemma」,也就是「寶石」的意思,似乎是在像徵它的珍貴性。
歷史上,Transformers、TensorFlow、BERT、T5、JAX、AlphaFold和AlphaCode,都是Google為開源社群做出貢獻的創新。

Google:今天我就來為你表演一個什麼是Open AI
而Google今天在全球同步推出的Gemma,必然會再一次掀起建構開源AI的熱潮。
同時也坐實了OpenAI「唯一ClosedAI」的名頭。
OpenAI最近才因為Sora火到爆,Llame據稱也要有大動作,谷歌這就又搶先一步。矽谷大廠,已經捲翻天了!

Google:開源閉源我都要
Hugging Face CEO也跟帖祝賀。

還貼了Gemma登上Hugging Face熱門榜的截圖。

Keras作者François Chollet直言:最強開源大模型,今日易主了。

有網友已經親自試用過,表示Gemma 7B真是速度很快。
Google簡直是用Gemini拳打GPT-4,用Gemma腳踢Llama 2!

網友們也是看熱鬧不嫌事大,召喚Mistral AI和OpenAI今晚趕快來點大動作,別讓谷歌真的搶了頭條。(手動狗頭)
同規模刷新SOTA,越級單挑Llama 2 13B
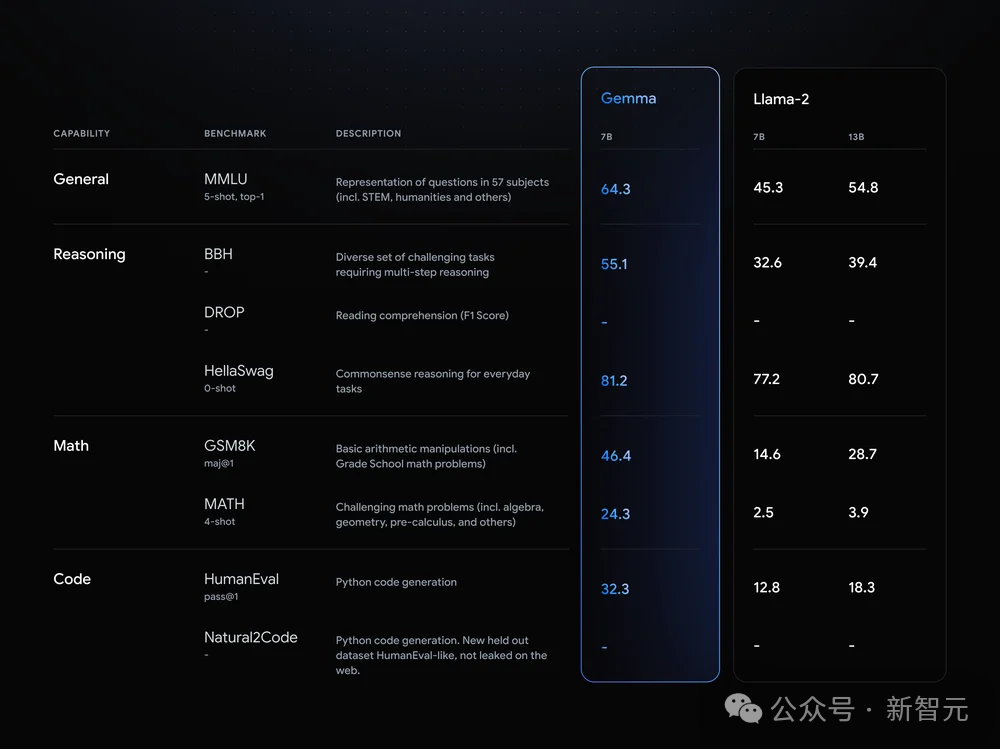
可以看到,Gemma-7B模型在涵蓋一般語言理解、推理、數學和編碼的8項基準測試中,表現已經超越了Llama 2 7B和13B!
並且,它也超越了Mistral 7B模型的效能,尤其是在數學、科學和編碼相關任務中。

在安全性方面,經過指令微調的Gemma-2B IT和Gemma-7B IT模型,在人類偏好評估中都超過了Mistal-7B v0.2模型。
特別是Gemma-7B IT模型,它在理解和執行具體指令方面,表現得更為出色。

一整套工具:跨框架、工具和硬體進行最佳化
這次,除了模型本身,Google還提供了一套工具來幫助開發者,確保Gemma模型負責任的使用,幫助開發者用Gemma建立更安全的AI應用程式。
- 谷歌為JAX、PyTorch和TensorFlow提供了完整的工具鏈,支援模型推理和監督式微調(SFT),並且完全相容於最新的Keras 3.0。
- 透過預置的Colab和Kaggle notebooks,以及與Hugging Face、MaxText、NVIDIA NeMo和TensorRT-LLM等流行工具的集成,使用者可以輕鬆開始探索Gemma。
- Gemma型號既可以在個人筆記型電腦和工作站上運行,也可以在Google Cloud上部署,支援在Vertex AI和Google Kubernetes Engine (GKE) 上的簡易部署。
- 谷歌也對Gemma進行了跨平台優化,確保了它在NVIDIA GPU和Google Cloud TPU等多種AI硬體上的卓越效能。
並且,使用條款為所有組織提供了負責任的商業使用和分發權限,不受組織規模的限制。

但,沒有全勝
不過,Gemma並沒有能夠在所有的榜單中,都拿下SOTA。
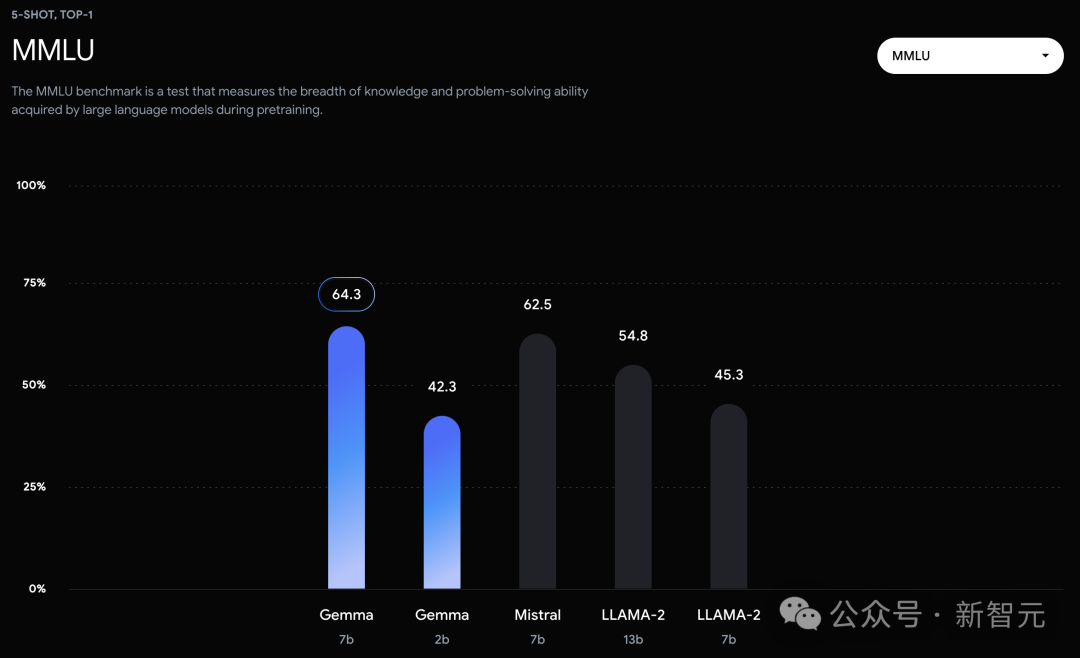
在官方放出的評測中,Gemma 7B在MMLU、HellaSwag、SIQA、CQA、ARC-e、HumanEval、MBPP、GSM8K、MATH和AGIEval中,成功擊敗了Llama 2 7B和13B模型。
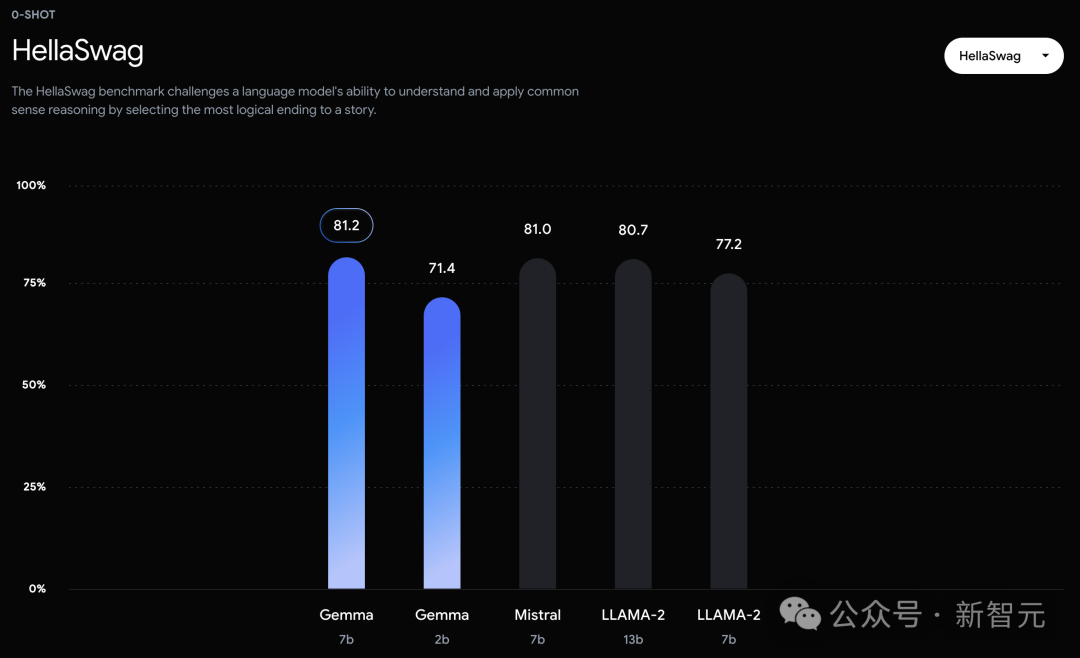
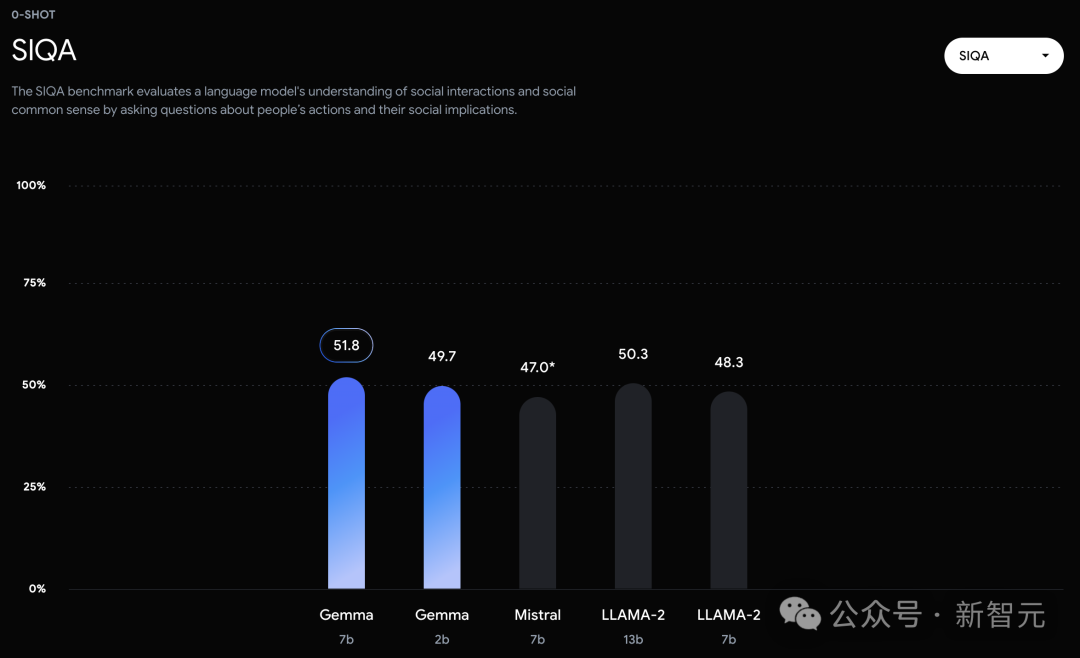
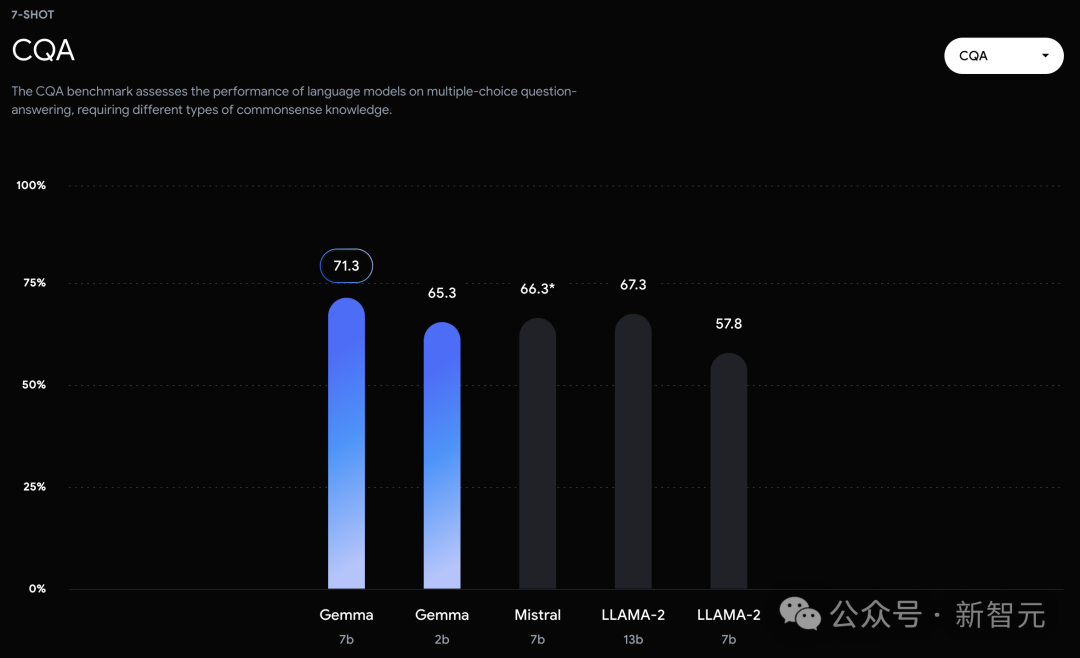
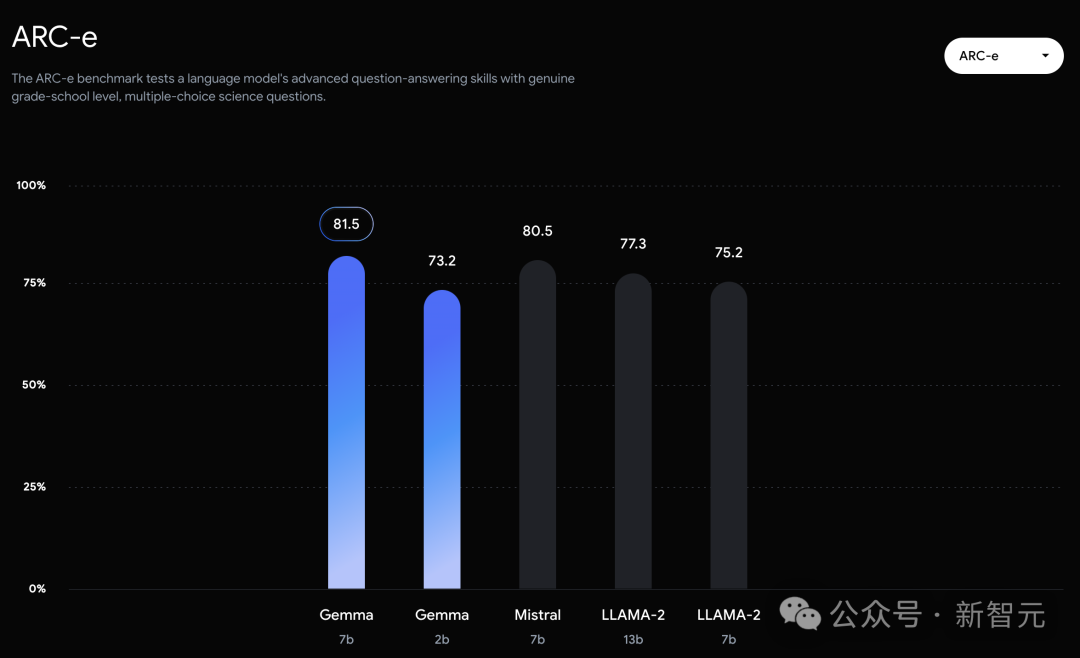
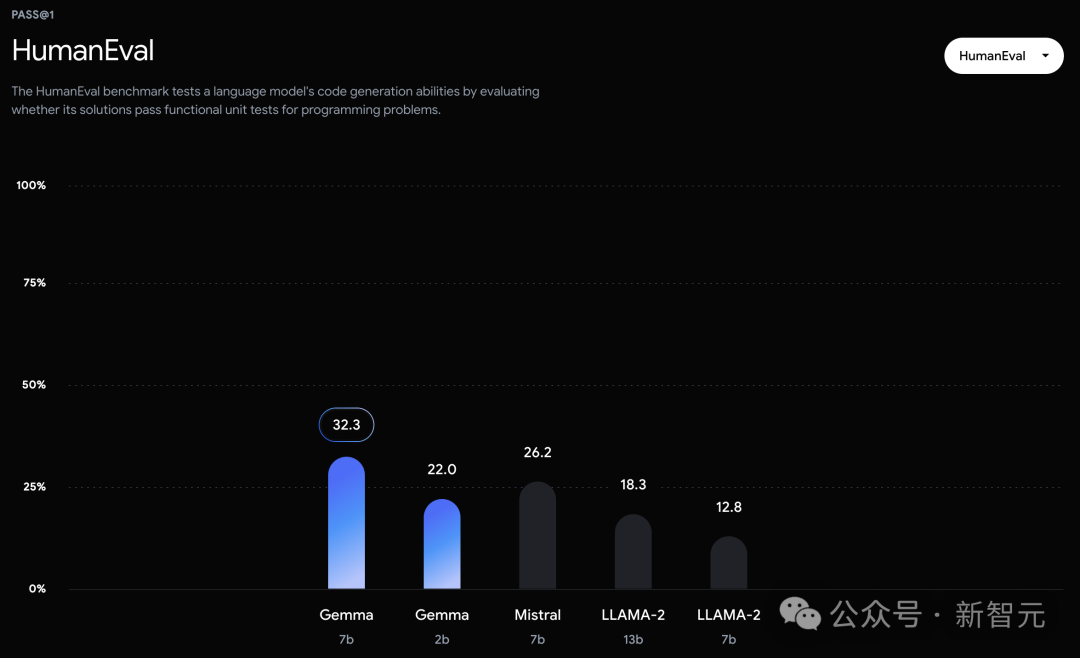
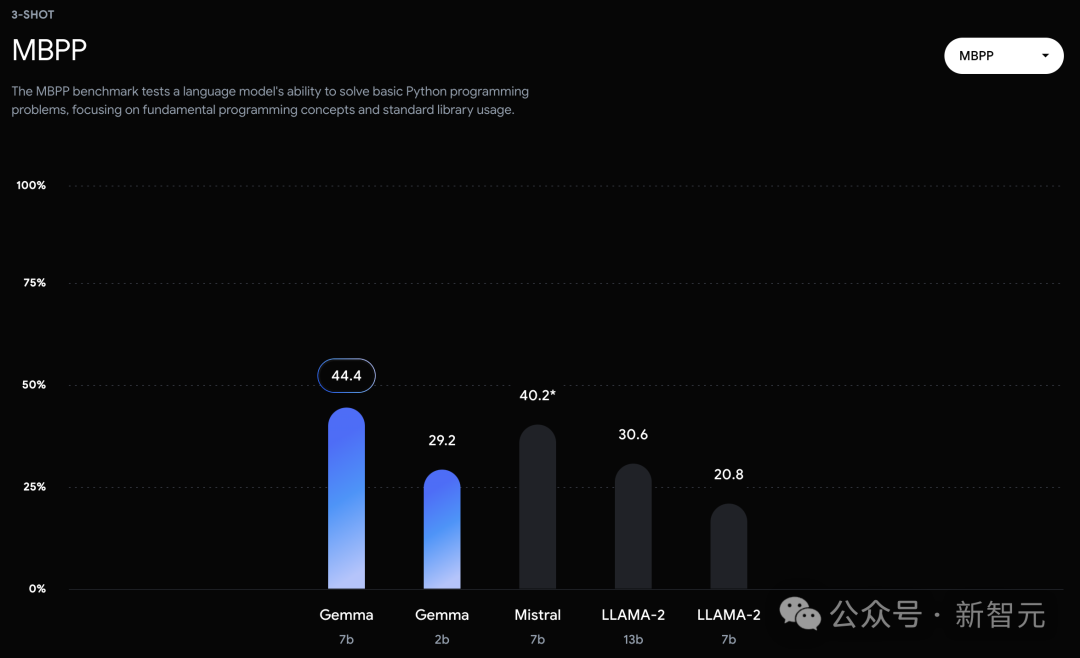
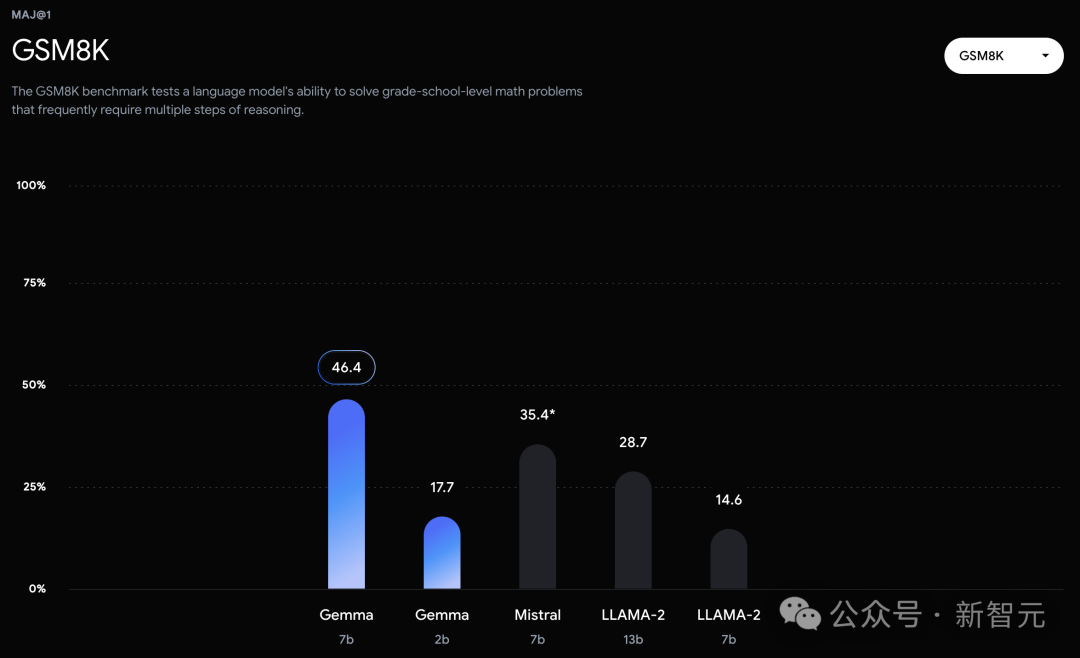
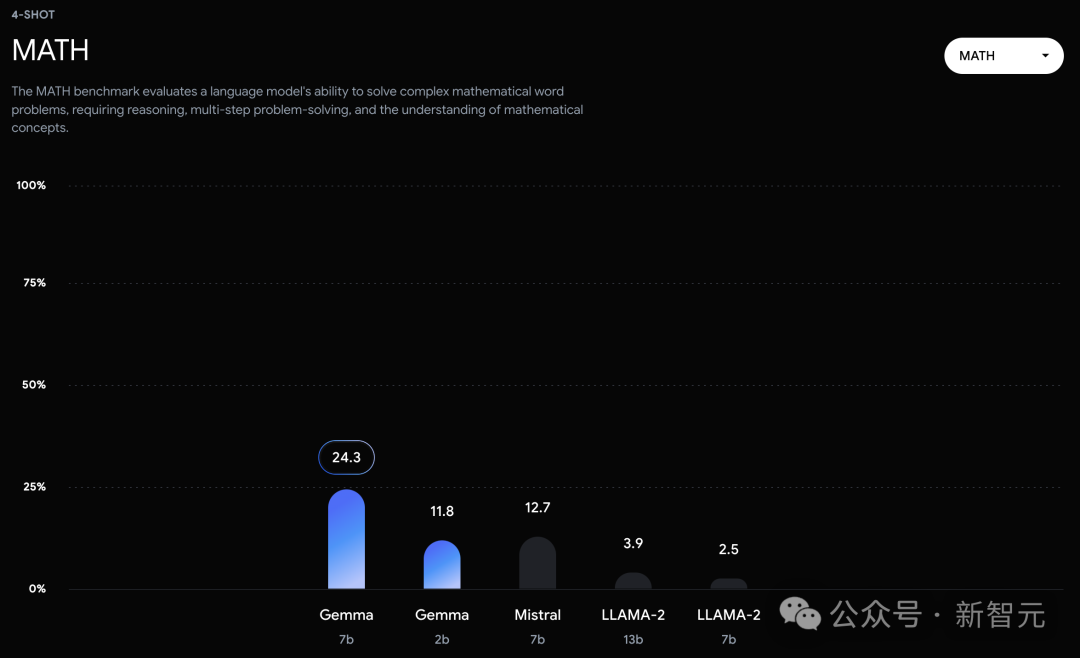
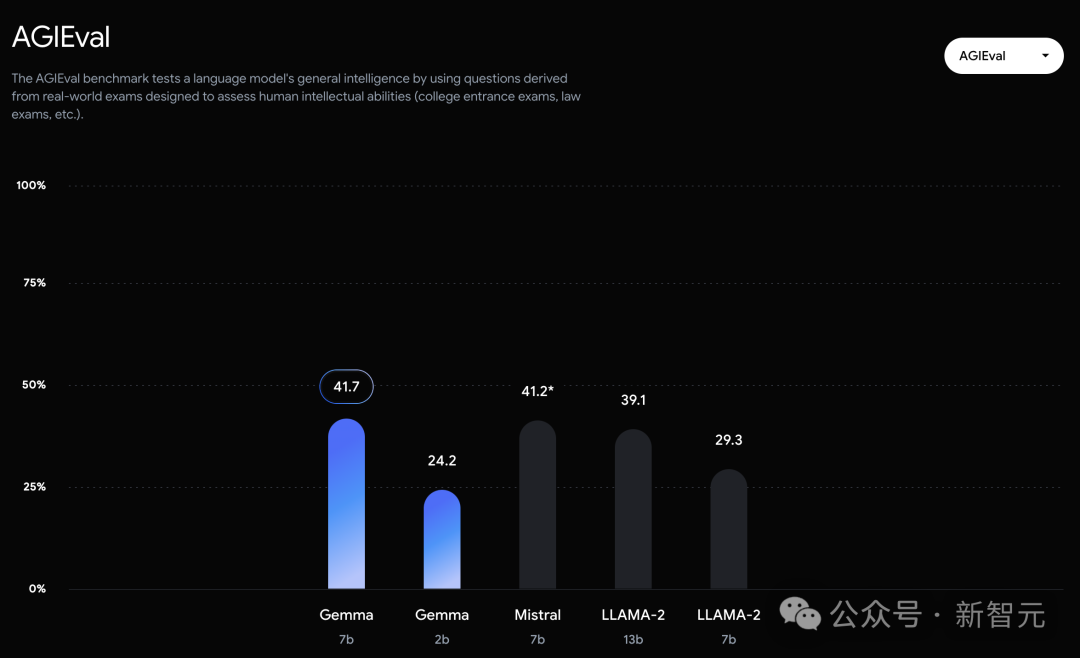
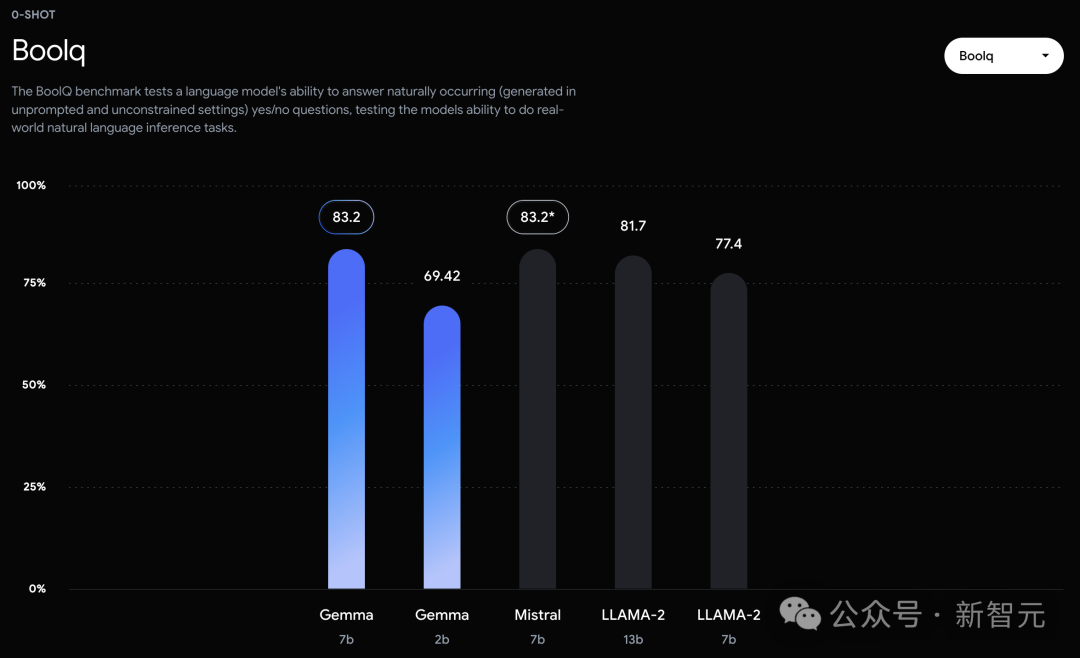
相比之下,Gemma 7B在Boolq測試中,只與Mistral 7B打了平手。
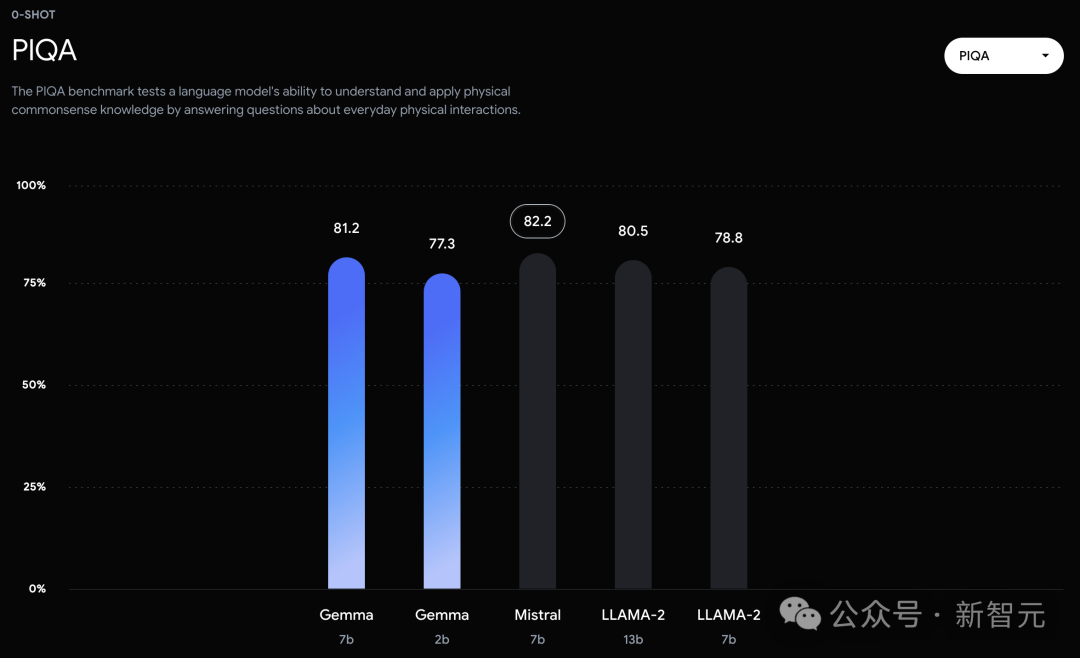
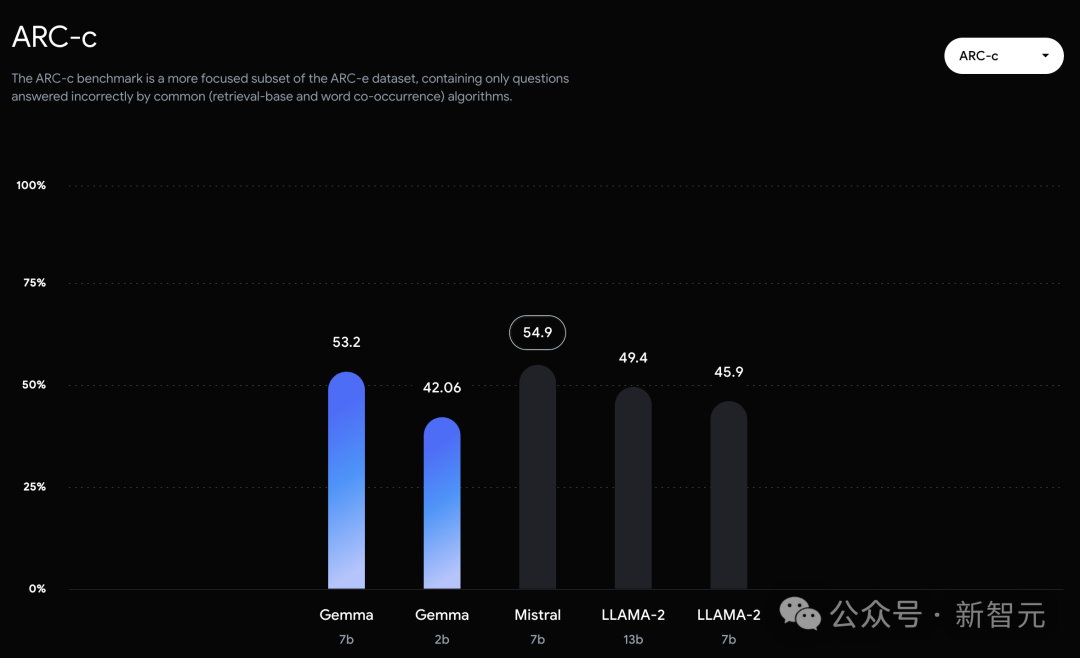
而在PIQA、ARC-c、Winogrande和BBH中,則不敵Mistral 7B。
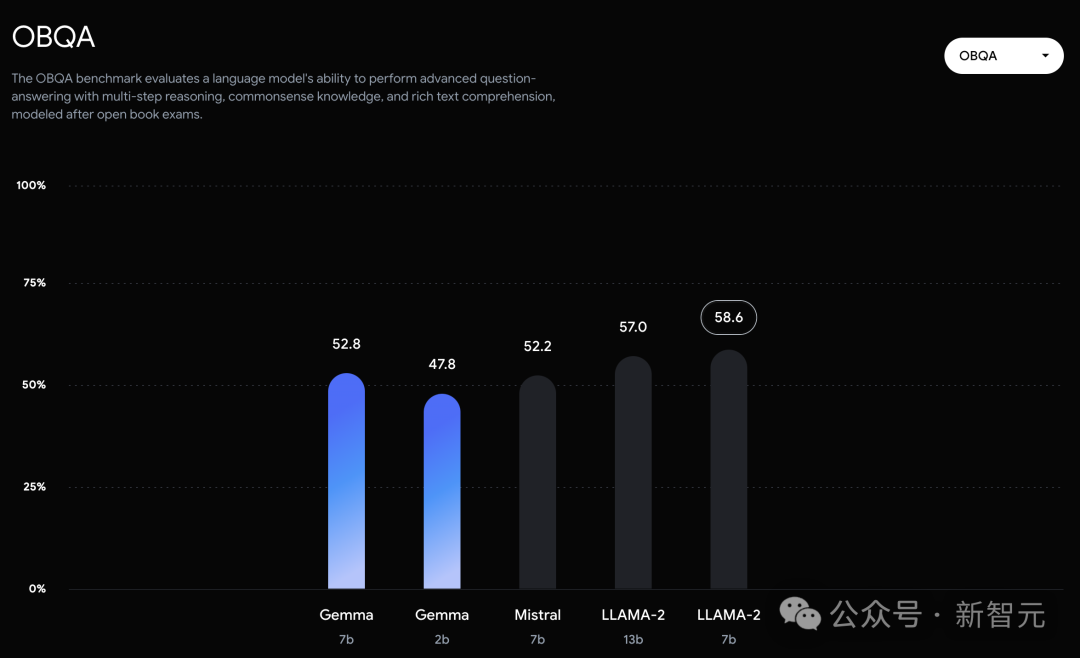
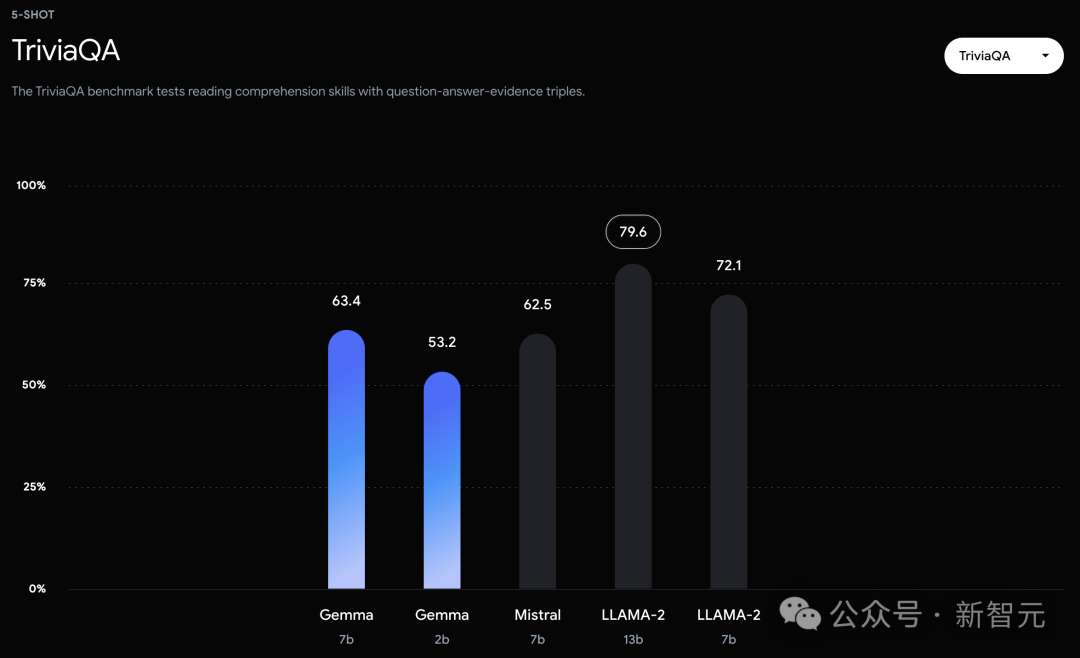
在OBQA和trivalent QA中,更是同時被7B和13B規模的Llama 2 7B斬於馬下。
技術報告
谷歌這次發布的兩個版本的Gemma模型,70 億參數的模型用於GPU和TPU上的高效部署和開發,20億參數的模型用於CPU和端側應用程式。
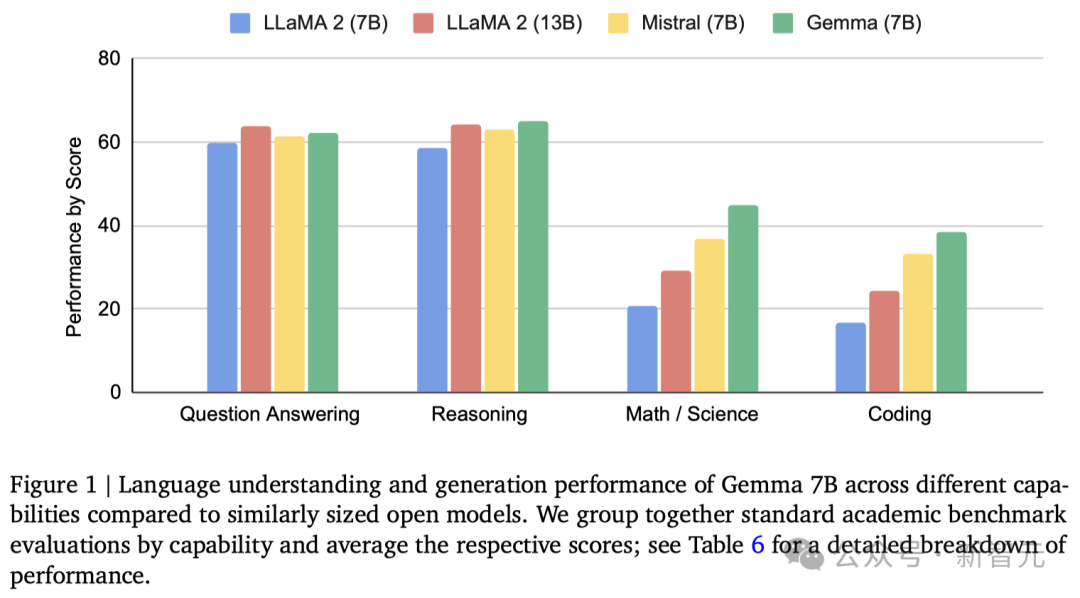
在18個基於文本的任務中的11個中,Gemma都優於相似參數規模的開源模型,例如問答、常識推理、數學和科學、編碼等任務。
模型架構方面,Gemma在Transformer的基礎上進行了幾項改進,從而在處理複雜任務時能夠展現出更出色的效能和效率。
- 多查詢注意力機制
其中,7B模型採用了多頭注意力機制,而2B模型則使用了多查詢注意力機制。結果顯示,這些特定的注意力機制能夠在不同的模型規模上提升表現。
- RoPE嵌入
與傳統的絕對位置嵌入不同,模型在每一層都使用了旋轉位置嵌入技術,並且在模型的輸入和輸出之間共享嵌入,這樣做可以有效減少模型的大小。
- GeGLU激活函數
將標準的ReLU激活函數替換成GeGLU激活函數,可以提升模型的表現。
- 歸一化化位置(Normalizer Location)
每個Transformer子層的輸入和輸出都進行了歸一化處理。這裡採用的是RMSNorm作為歸一化層,以確保模型的穩定性與效率。
架構的核心參數如下:

兩種規模的參數如下:

預訓練
訓練資料
Gemma 2B和7B分別針對來自網路文件、數學和程式碼的主要英語資料的2T和6Ttoken,進行了訓練。
與Gemini不同,這些模型不是多模態的,也沒有針對多語言任務的SOTA進行訓練。
谷歌使用了Gemini的SentencePiece分詞器的子集,來實現相容性。
指令微調
團隊對Gemma 2B和7B模型進行了微調,包括有監督的微調(SFT)和基於人類回饋的強化學習(RLHF)。
在有監督的微調階段,研究者使用了一個由純文字、英文、由人工和機器產生的問題-答案對組成的資料集。
在強化學習階段,則是使用了一個基於英文偏好資料訓練出的獎勵模型,以及一套精心挑選的高品質提示作為策略。
研究者發現,這兩個階段對於提升模型在自動評估和人類偏好評估中的表現,至關重要。
監督微調
研究者根據基於LM的平行評估,選擇了資料混合物進行監督微調。
給定一組保留prompt,研究者會從測試模型中產生響應,從基準模型中產生對相同提示的響應,隨機洗牌,然後要求一個更大、能力更強的模型在兩種響應之間表達偏好。
研究者建構了不同的提示集,以突出特定的能力,例如遵循指示、實事求是、創造性和安全性。
我們使用了不同的基於LM的自動評委,採用了一系列技術,如思維鏈提示、使用評分標準和章程等,以便與人類偏好保持一致。
RLHF
研究者進一步利用來自人類回饋的強化學習(RLHF),並對已經進行過有監督微調的模型進行了最佳化。
他們從人類評估者那裡收集他們的偏好選擇,並在Bradley-Terry 模型的基礎上,訓練了一個獎勵函數,這與Gemini專案的做法相似。
研究者採用了改良版的REINFORCE演算法,加入了Kullback–Leibler 正規化項,目的是讓策略優化這個獎勵函數,同時保持與最初調整模型的一致性。
與先前的監督微調階段相似,為了調整超參數並進一步防止獎勵機制被濫用,研究者使用了一個高性能模型作為自動評估工具,並將其與基準模型進行了直接比較。
性能評估
自動評估
谷歌在多個領域對Gemma進行了性能評估,包括物理和社會推理、問答、程式設計、數學、常識推理、語言建模、閱讀理解等。
Gemma2B和7B模型與一系列學術基準測試中的多個外部開源大語言模型進行了比較。
在MMLU基準測試中,Gemma 7B模型不僅超過了所有規模相同或更小的開源模型,還超過了一些更大的模型,包括Llama 2 13B。

然而,基準測試的製定者評估人類專家的表現為89.8%,而Gemini Ultra是第一個超越此標準的模型,這表明Gemma在達到Gemini和人類水平的性能上,還有很大的提升空間。
並且,Gemma模型在數學和程式設計的基準測試中表現尤為突出。
在通常用於評估模型分析能力的數學任務中,Gemma 模型在GSM8K和更具挑戰性的MATH基準測試上至少領先其他模型10分。
同樣,在HumanEval上,它們至少領先其他開源模型6分。
Gemma甚至在MBPP上超過了專門進行程式碼微調的CodeLLaMA 7B模型的表現(CodeLLaMA得分為41.4%,而Gemma 7B得分為44.4%)。
記憶評估
近期研究發現,即便是經過精心對齊的人工智慧模型,也可能遭受新型對抗打擊,這種打擊能夠規避現有的對齊措施。
這類打擊有可能使模型行為異常,有時甚至會導致模型重複輸出它在訓練過程中記住的資料。
因此,研究者專注於研究模型的「可檢測記憶」能力,這被認為是評估模型記憶能力的一個上限,並已在多項研究中作為通用定義。
研究者對Gemma預訓練模型進行了記憶測試。
具體來說,他們從每個資料集中隨機選擇了10,000篇文檔,並使用文檔開頭的50個詞元作為模型的prompt。
測驗重點在於精確記憶,即如果模型能夠基於輸入,精確地產生接下來的50token,與原文完全一致,便認為模型「記住了」這段文字。
此外,為了探測模型是否能夠以改寫的形式記憶訊息,研究者也測試了模型的「近似記憶」能力,即允許在生成的文本和原文之間存在最多10%的編輯差距。
在圖2中,是Gemma的測試結果與體量相近的PaLM和PaLM 2模型的比較。

可以發現,Gemma的記憶率明顯較低(見圖2左側)。
不過,透過對整個預訓練資料集的「總記憶量」進行估算,可得一個更為準確的評估結果(見圖2右側):Gemma在記憶訓練資料方面的表現與PaLM相當。
個人資訊的記憶化問題尤其關鍵。如圖3所示,研究者並未發現有記憶化的敏感資訊。

雖然確實發現了一些被歸類為「個人資訊」的數據被記憶,但這種情況發生的頻率相對較低。
而且這些工具往往會產生許多誤報(因為它們僅通過匹配模式而不考慮上下文),這意味著研究者發現的個人資訊量可能被高估了。
總結討論
總的來說,Gemma模型在對話、邏輯推理、數學和程式碼生成等多個領域,都有所提升。
在MMLU(64.3%)和MBPP(44.4%)的測試中,Gemma不僅展現了卓越的效能,也顯示了開源大語言模型效能進一步提升的空間。
除了在標準測試任務上取得的先進性能,谷歌也期待與社區共同推動這一領域的發展。
Gemma從Gemini模型計劃中學到了很多,包括編碼、資料處理、架構設計、指令優化、基於人類回饋的強化學習以及評估方法。
同時,谷歌再次強調使用大語言模型時存在的一系列限制。
儘管在標準測試任務上表現優異,但要創建出既穩定又安全、能夠可靠執行預期任務的模型,還需要進一步的研究,包括確保資訊的準確性、模型的目標對齊、處理複雜邏輯推理,以及增強模型對惡意輸入的抵抗力。
團隊表示,正如Gemini所指出的,需要更具挑戰性和穩健性的測試基準。
團隊成員
核心貢獻者:

其他貢獻者:

產品經理、專案經理、執行贊助、負責人和技術負責人:
