Six big pitfalls when calling third-party interfaces

Six big pitfalls when calling third-party interfaces
I believe everyone has felt today's market situation, and the interviews are getting more and more complicated, from technical eight-part papers to business scenarios. Today, we bring you 6 pitfalls related to third-party interface calls. The questions are not difficult, but if they are suddenly asked during the interview, you may be a little confused when answering them. Although you know them all, you may not be able to answer them well.
Next, I will lead you through it as a whole, and you will leave an impression after reading it. I am also ready for the following notes. Deduct 1 in the comment area and send me a private message to collect it. You can also come and complain about some of the pitfalls you have encountered, so that more friends can see and communicate together.
Without further ado, let’s get to the point.
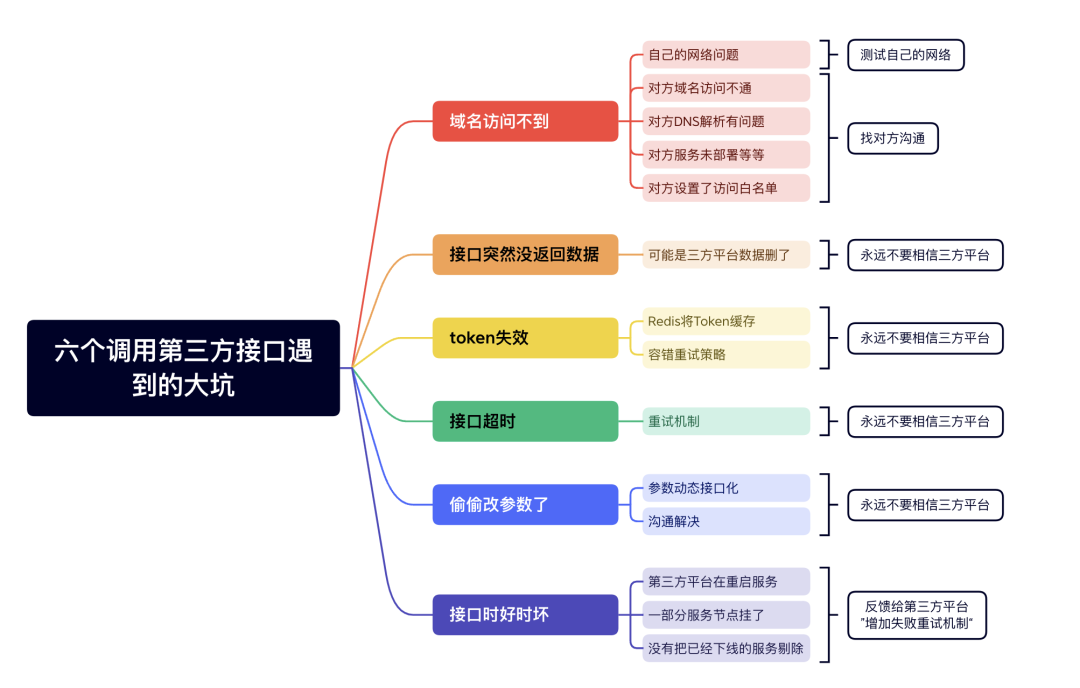
Domain name cannot be accessed
First of all, the first problem is that the domain name cannot be accessed. Generally, when we connect to the API interface of a third-party platform for the first time, we may first call it through the browser or postman.
There are two aspects to this point: either I have a problem or the other party has a problem.
- own network problems
- The other party's domain name cannot be accessed.
- There is a problem with the other party’s DNS resolution
- The other party's service is not deployed, etc.
- The other party has set up an access whitelist
It's possible that when you call the API interface of a third-party platform, their interface is really down, and they don't know it yet. Another most important situation is whether your work network can access the external network interface.
For security reasons, some companies have set up firewalls for the development environment of the intranet, or have some other restrictions. Some IP whitelists can only access some designated external network interfaces.
If you find that the domain name you are accessing cannot be accessed in the development environment, you need to go to the operation and maintenance classmate to add an IP whitelist for you.
The interface suddenly did not return data
If you call an API interface of a third-party platform to query data, data will always be returned at the beginning. But suddenly one day no data was returned. But the API interface can respond normally. Don’t be surprised, it’s possible that a third-party platform deleted the data.
After I connected the API interface of the third-party platform, I deployed it to the test environment and found that their interface did not return data. The reason was that one day they deleted all the data in the test environment. Therefore, before deploying the test environment, you must first communicate with the other party about what data you want to use for testing and cannot delete it.
Another point is that in our own programs, we should never trust the data of third-party platforms. If something goes wrong, we must write a fault-tolerant strategy. We cannot drag down our own system to death because of the mistakes of three parties.
token invalid
Some platform API interfaces need to call another API interface to obtain the token before making a request, and then carry the token information in the header to access other business API interfaces. In fact, most of our own systems are designed this way.
In the API interface for obtaining tokens, we need to pass in information such as account number, password, and key. This information is different for each interface docking party.
Before we request other API interfaces, do we call the token acquisition interface in real time every time to obtain the token? Or should we request the token once, cache it in redis, and then obtain the data directly from redis?
Obviously we prefer the latter, because if we call the token-obtaining interface in real time to obtain the token every time before requesting other API interfaces, the interface will be requested twice each time, which will have some impact on performance.
If the requested token is saved to redis, another problem will arise: the token is invalid.
The token we obtain by calling the third-party platform's interface to obtain the token generally has a validity period, such as: 1 day, 1 month, etc.
During the validity period, the API interface can be accessed normally. If the validity period of the token exceeds, access to the API interface is not allowed.
It’s easy to handle. Wouldn’t it be OK if we set the expiration time of redis to be the same as the validity period of the token?
The idea is good, but there are problems.
How can you guarantee that the server time of your system is exactly the same as the server time of the third-party platform?
I have encountered a major manufacturer before that provides a token acquisition interface, initiates a request within 30 days, and returns the same token value every time. If more than 30 days have passed, a new one is returned.
It may happen that the server time of your system is faster and the time of the third-party platform is slower. As a result, after 30 days, your system called the token acquisition interface of the third-party platform to obtain the token or the old token, which was updated to redis.
After a while, the token expires. Your system still uses the old token to access other API interfaces of the third-party platform, but always returns failure. But you have to wait 30 days to get a new token, which is too long.
For specific error codes, a retry mechanism should be designed:
In order to solve this problem, it is necessary to catch the token invalid exception. If you find that the token is invalid when calling other API interfaces, immediately request the token interface and update the new token to redis immediately.
This can basically solve the problem of token invalidation and ensure the stability and performance of access to other interfaces as much as possible.
Interface timeout
After the system goes online, the most likely problem to occur when calling a third-party API interface is the interface timeout. There is a very complex link between the system and the external system. There are many problems in the middle, which may affect the response time of the API interface.
This is very embarrassing. We cannot control other people's systems. If you ask others to optimize the system, it will take half a month for them to set up the adjustment and go online. This is still a good situation, and sometimes it takes half a year. What others are experiencing is your system. A slower speed is still acceptable, but if it always times out and fails, it will be fed back to the user level. The first thing users look for is you. . . .
As the caller of the API interface, when facing the timeout problem of the third-party API interface, in addition to giving them feedback on the problem and optimizing the interface performance.
Our more effective way may be to add a failure retry mechanism for interface calls.
For example:
- If the interface call fails, the program will automatically retry three times immediately.
- If the retry succeeds, the API interface call is successful.
- If it still fails after three retries, the API interface call fails.
Secretly changed the parameters
I have previously called the API interface of a certain platform to obtain the status of indicators. The statuses agreed upon by both parties were: normal and disabled.
The status is then updated into our metrics table. Later, the systems of both parties were online and running for several months. Suddenly one day, users reported that a certain piece of data had been deleted, but why could it still be found on the page? At this time, I checked our indicator table and found that the status was normal.
Then check the API interface log for calling the platform and find that the status of the returned indicator is: removed.
What the hell, I have said my greetings eight hundred times in my heart. . .
After communicating with the developers of the platform, I found that they had changed the status enumeration and added multiple values such as: on the shelf, off the shelf, etc., without notifying us. This is a trap. According to our code here, if the state is not disabled, it is considered a normal state.
The off-shelf status is automatically judged as a normal status. After communicating with the other party, they confirmed that the delisting status was abnormal and the indicator should not be displayed. They changed the data and temporarily solved the problem with this indicator. Later, they changed back to the previous status enumeration value according to the interface document.
There is another solution here, which is to return the enumeration information through an interface and then display it, so as to avoid the problems mentioned above.
Interface is hit or miss
I don’t know if you have ever encountered a situation where the interface is good or bad when calling a third-party interface. 5 minutes ago, the interface could still return data normally.
After 5 minutes, the interface returns 503 Unavailable. After a few more minutes, the interface was able to return data normally again.
Possible situations:
- In this case, there is a high probability that the third-party platform is restarting the service. During the restart process, the service may be temporarily unavailable.
- The third-party interface deployed multiple service nodes, and some service nodes were down. It will also cause the return value to be good or bad when requesting a third-party interface.
- The configuration of the gateway was not updated in time, and services that had been offline were not removed. In this way, when the user's request passes through the gateway, the gateway forwards it to the service that has been offline, causing the service to become unavailable. The gateway forwards the request to the normal service, and the service can return normally.
If you encounter this problem, report the problem to the third-party platform as soon as possible, and then add an interface failure retry mechanism.