In-depth chat about protocols and hard disks in the Web3 world: IPFS

In-depth chat about protocols and hard disks in the Web3 world: IPFS
In the world of Web3.0, there are many technologies that can replace these three technologies and do things better. One of the most outstanding projects is a technology that integrates protocols, resource acceleration and storage: IPFS.In the Web2.0 world, the protocol is usually HTTP, resource acceleration is usually CDN, and object storage is usually OSS.
In the world of Web3.0, there are many technologies that can replace these three technologies and do things better. One of the most outstanding projects is a technology that integrates protocols, resource acceleration and storage: IPFS.
This article will introduce what IPFS is and how it works.
The white paper of IPFS was released in July 2014, which mentioned many imaginations of technical solutions. Its concept is completely different from HTTP, CDN and OSS in traditional Web2.0.
Before introducing IPFS, let's review the advantages and disadvantages of HTTP, CDN and OSS.
In the Web2.0 world, the protocol is usually HTTP, resource acceleration is usually CDN, and object storage is usually OSS.
In the world of Web3.0, there are many technologies that can replace these three technologies and do things better. One of the most outstanding projects is a technology that integrates protocols, resource acceleration and storage: IPFS.
This article will introduce what IPFS is and how it works.
The white paper of IPFS was released in July 2014, which mentioned many imaginations of technical solutions. Its concept is completely different from HTTP, CDN and OSS in traditional Web2.0.
Before introducing IPFS, let's review the advantages and disadvantages of HTTP, CDN and OSS.
Why are technologies such as HTTP, CDN, and OSS not working in the Web3 world?
Advantages and disadvantages of HTTP
The HTTP referred to here is HTTP1.1 and HTTP2.0.
Its strength is handling the transfer of small files.
But there are five challenges in data transmission on the modern Internet:
- The amount of data hosted and distributed has reached the petabyte level.
- Big data computing across organizations.
- Distribute massive amounts of HD video.
- Linking and version management of massive data.
- Prevent important files from being lost.
Summarize the above as: massive data, everywhere.
And these are difficult for HTTP to deal with. So with the continuous development of the Internet, HTTP will withdraw from the stage of history sooner or later.
The HTTP referred to here is HTTP1.1 and HTTP2.0.
Its strength is handling the transfer of small files.
But there are five challenges in data transmission on the modern Internet:
- The amount of data hosted and distributed has reached the petabyte level.
- Big data computing across organizations.
- Distribute massive amounts of HD video.
- Linking and version management of massive data.
- Prevent important files from being lost.
Summarize the above as: massive data, everywhere.
And these are difficult for HTTP to deal with. So with the continuous development of the Internet, HTTP will withdraw from the stage of history sooner or later.
Advantages and disadvantages of CDN
The main purpose of CDN is to speed up the access speed of static resources, which is also its main advantage. Secondly, it can resist DDOS attacks, and the maintenance is more convenient.
But the disadvantages are obvious. The process of setting up a CDN server is relatively complicated and the cost is high, so generally you will buy a server-side CDN, but the price is not low.
The main purpose of CDN is to speed up the access speed of static resources, which is also its main advantage. Secondly, it can resist DDOS attacks, and the maintenance is more convenient.
But the disadvantages are obvious. The process of setting up a CDN server is relatively complicated and the cost is high, so generally you will buy a server-side CDN, but the price is not low.
Advantages and disadvantages of OSS
The OSS referred to here refers to the OSS service of the cloud service provider.
The advantages of OSS are high reliability, easy expansion, fast speed, and edge computing. On top of this, there may be a series of advanced functions such as mirroring, backup, security, and desensitization. To sum it up in two words: peace of mind.
The disadvantages are also obvious, the price is very expensive. But all OSS service providers count low cost as one of their advantages. In fact, I can’t feel it when the amount of data is small, but once the amount of data surges, the high price is really unacceptable. I have a deep understanding of this.
Of course, the real reason for the expensive OSS is not the high cost of storage, but the high cost of bandwidth.
The OSS referred to here refers to the OSS service of the cloud service provider.
The advantages of OSS are high reliability, easy expansion, fast speed, and edge computing. On top of this, there may be a series of advanced functions such as mirroring, backup, security, and desensitization. To sum it up in two words: peace of mind.
The disadvantages are also obvious, the price is very expensive. But all OSS service providers count low cost as one of their advantages. In fact, I can’t feel it when the amount of data is small, but once the amount of data surges, the high price is really unacceptable. I have a deep understanding of this.
Of course, the real reason for the expensive OSS is not the high cost of storage, but the high cost of bandwidth.
Problems with the Modern Internet
The above-mentioned problems all belong to the category of technology. In addition, there is another fundamental problem. The problem with the modern Internet model.
The above-mentioned problems all belong to the category of technology. In addition, there is another fundamental problem. The problem with the modern Internet model.
Technical issues, cost issues, efficiency issues
Because the modern Internet is a centralized model. This model is extremely costly and requires the construction of a centralized large-scale server cluster, and it is prone to problems such as service congestion and delay during peak periods, and a large number of resource restrictions and waste during trough periods, so the efficiency is very low. This model relies heavily on the storage and bandwidth of centralized service providers. Although technologies such as elastic computing can alleviate this situation, they cannot solve the problem of the underlying mode.
IPFS can share storage and bandwidth, which can make more efficient use of resources and reduce costs.
IPFS can effectively deduplicate files and eliminate redundancy.
Because the modern Internet is a centralized model. This model is extremely costly and requires the construction of a centralized large-scale server cluster, and it is prone to problems such as service congestion and delay during peak periods, and a large number of resource restrictions and waste during trough periods, so the efficiency is very low. This model relies heavily on the storage and bandwidth of centralized service providers. Although technologies such as elastic computing can alleviate this situation, they cannot solve the problem of the underlying mode.
IPFS can share storage and bandwidth, which can make more efficient use of resources and reduce costs.
IPFS can effectively deduplicate files and eliminate redundancy.
Data Ownership Issues
The modern Internet is prone to data loss. Because the data is on a centralized server cluster, the service provider has the right to manage the data. Although large service providers have data backup and disaster recovery solutions. But occasionally accidents do happen. The most important thing is that service providers can delete our data for any reason, for example, your data is illegal, saying that you violate the platform regulations. As an ordinary person, it is difficult to fight against the service provider, some important data just disappeared without knowing it.
IPFS can store data forever.
The modern Internet is prone to data loss. Because the data is on a centralized server cluster, the service provider has the right to manage the data. Although large service providers have data backup and disaster recovery solutions. But occasionally accidents do happen. The most important thing is that service providers can delete our data for any reason, for example, your data is illegal, saying that you violate the platform regulations. As an ordinary person, it is difficult to fight against the service provider, some important data just disappeared without knowing it.
IPFS can store data forever.
Heavy reliance on the backbone network
The modern Internet relies heavily on the backbone network, and when the backbone network fails, large-scale service interruptions and delays will occur.
IPFS does not rely on the backbone network, even in areas with underdeveloped networks, IPFS has a good performance.
The modern Internet relies heavily on the backbone network, and when the backbone network fails, large-scale service interruptions and delays will occur.
IPFS does not rely on the backbone network, even in areas with underdeveloped networks, IPFS has a good performance.
Censorship issues
Since modern Internet applications are all centralized networks, the ruler can prevent the people of the entire country from accessing a certain website or app. This practice is also called a wall in China.
IPFS is that IP is distributed, and it is almost impossible to be walled.
Since modern Internet applications are all centralized networks, the ruler can prevent the people of the entire country from accessing a certain website or app. This practice is also called a wall in China.
IPFS is that IP is distributed, and it is almost impossible to be walled.
ecological problem
Although the service provider paid a large amount of money to help us build a server cluster to provide us with products. But the wool comes from the sheep. They will take our money through a series of means such as membership fees and advertising fees. Even in order to make a profit, lose the bottom line, abuse user privacy, constantly cross the border, make false advertisements, malicious pop-up advertisements, limit Internet speed to squeeze toothpaste, even sell our data, charge public relations fees, delete posts and ban accounts, etc.
In addition to the above problems, Internet security is also a headache. For example, various anti-human verification codes.
In the past, we had no choice. Although it was unbearable, we could only swallow our anger and use the Internet to scold the Internet on the Internet. But now it's different, we have better options. In the IPFS world, none of these problems exist anymore.
iQiyi has launched a skit before, which is used to satirize the modern Internet. Someone moved it to Zhihu, if you are interested, you can check it out: www.zhihu.com/zvideo/1433….
Here are some results we don't want to see:

Although the service provider paid a large amount of money to help us build a server cluster to provide us with products. But the wool comes from the sheep. They will take our money through a series of means such as membership fees and advertising fees. Even in order to make a profit, lose the bottom line, abuse user privacy, constantly cross the border, make false advertisements, malicious pop-up advertisements, limit Internet speed to squeeze toothpaste, even sell our data, charge public relations fees, delete posts and ban accounts, etc.
In addition to the above problems, Internet security is also a headache. For example, various anti-human verification codes.
In the past, we had no choice. Although it was unbearable, we could only swallow our anger and use the Internet to scold the Internet on the Internet. But now it's different, we have better options. In the IPFS world, none of these problems exist anymore.
iQiyi has launched a skit before, which is used to satirize the modern Internet. Someone moved it to Zhihu, if you are interested, you can check it out: www.zhihu.com/zvideo/1433….
Here are some results we don't want to see:
What is IPFS?
IPFS has many definitions.
Defined from its paper, IPFS is a content-indexed, versioned, peer-to-peer file system.
From a technical point of view, IPFS is a forest full of merkle-trees.
From a business point of view, IPFS is a point-to-point hypertext protocol.
It will make the internet faster, safer and more open.
IPFS has many definitions.
Defined from its paper, IPFS is a content-indexed, versioned, peer-to-peer file system.
From a technical point of view, IPFS is a forest full of merkle-trees.
From a business point of view, IPFS is a point-to-point hypertext protocol.
It will make the internet faster, safer and more open.
Introduction to IPFS
IPFS is an abbreviation, the full name is Inter Planetary File System, Interplanetary File System.
It is a peer-to-peer interplanetary file system. From this perspective, it targets the entire Internet, not a certain protocol or a certain file storage system. It is more like a single BitTorrent cluster (swarm).
IPFS is an abbreviation, the full name is Inter Planetary File System, Interplanetary File System.
It is a peer-to-peer interplanetary file system. From this perspective, it targets the entire Internet, not a certain protocol or a certain file storage system. It is more like a single BitTorrent cluster (swarm).
About the IPFS Author
The author is Juan Benet, which is transliterated as Juan according to Chinese custom. American, born in 1988, graduated from Stanford University, is an out-and-out technical genius.
Juan is also the founder of Protocol Labs, IPFS and Filecoin.
In 2014 he founded Protocol Labs, the same year he launched the IPFS project.
Protocol Labs is the official organization of IPFS and Filecoin, and its goal is how to build the next generation Internet.
Four years later, in 2018, he was included in Fortune Magazine's 40 under 40 list.
The author is Juan Benet, which is transliterated as Juan according to Chinese custom. American, born in 1988, graduated from Stanford University, is an out-and-out technical genius.
Juan is also the founder of Protocol Labs, IPFS and Filecoin.
In 2014 he founded Protocol Labs, the same year he launched the IPFS project.
Protocol Labs is the official organization of IPFS and Filecoin, and its goal is how to build the next generation Internet.
Four years later, in 2018, he was included in Fortune Magazine's 40 under 40 list.
What technologies is IPFS based on?
The core technology of IPFS
A core principle of IPFS is to model all data as part of the same Merkle DAG.
It employs but is not limited to the following technologies:
- Content addressing based on distributed hash table DHT.
- Object management based on the Git model.
- Based on Merkle object associations.
- Based on peer-to-peer technology.
- Based on the global namespace IPNS.
Through the above various technologies, a series of problems such as massive data, high concurrency, high throughput, and file loss have been solved.
And what it does, in summary, there are only three points: it specifies how to upload files, how to retrieve files, and how to download files.
You may ask, aren't most of these technologies in the P2P field in the past? That's right, IPFS is a P2P master. It didn't create many technologies or concepts out of thin air, but stood on the shoulders of giants.
A core principle of IPFS is to model all data as part of the same Merkle DAG.
It employs but is not limited to the following technologies:
- Content addressing based on distributed hash table DHT.
- Object management based on the Git model.
- Based on Merkle object associations.
- Based on peer-to-peer technology.
- Based on the global namespace IPNS.
Through the above various technologies, a series of problems such as massive data, high concurrency, high throughput, and file loss have been solved.
And what it does, in summary, there are only three points: it specifies how to upload files, how to retrieve files, and how to download files.
You may ask, aren't most of these technologies in the P2P field in the past? That's right, IPFS is a P2P master. It didn't create many technologies or concepts out of thin air, but stood on the shoulders of giants.
Why peer-to-peer?
Modern Internet resources all require an http address to obtain, so a large number of URLs are stored in our browser's favorites. This mode is the location-based addressing mode.
But if you think about it carefully, we actually only care about whether the content of the resource is what we want, not where the resource is.
The resources we need will be needed by others. If this resource is downloaded from someone's computer near us, we only need to download it directly from this person's computer, and there is no need to go to the source of this file to obtain it. This mode is the content-based addressing mode.
The point-to-point transmission mode is the basis of the above.
Modern Internet resources all require an http address to obtain, so a large number of URLs are stored in our browser's favorites. This mode is the location-based addressing mode.
But if you think about it carefully, we actually only care about whether the content of the resource is what we want, not where the resource is.
The resources we need will be needed by others. If this resource is downloaded from someone's computer near us, we only need to download it directly from this person's computer, and there is no need to go to the source of this file to obtain it. This mode is the content-based addressing mode.
The point-to-point transmission mode is the basis of the above.
How IPFS works
When we upload files on IPFS, we need to go through the following steps.
- IPFS first divides the file into several small data blocks with a unit of 256 kb, and then stamps hash fingerprints on them. A hash fingerprint is a unique string that corresponds to a data block one-to-one.
- Then IPFS performs hash operation on the hash value of every two small data blocks to get a new hash. It will repeat this process until all the hash values of all data blocks are calculated into one hash value. The final hash value is Root Hash, also called CID (Content Identifier). This process is the process of building Merkle DAG, which is the core principle of IPFS.
- IPFS will remove duplicate files. Because each file will correspond to a hash value, the same hash value means that it is a duplicate file. IPFS will remove duplicate files, but each node can keep a backup of this node.
- Each IPFS will store the data it needs, and use DHT to record what data each node stores. DHT is a mapping of content ID (CID) and user ID (PeerID). IPFS will send our file information to all other online nodes, but it is not a real file, but a structure. Contains CID and PeerID. Each node updates its own hash table. So the process is very fast. It's like copying the variable address in the program instead of copying the actual variable memory space.
- When we need to obtain a file, we will use the hash value of the file to find out who's computer the file is on, and then download it from these people's computers. If the files we need are stored on the computers of 100 people, and now these 100 people are online at the same time, then we can transfer files with these 100 people at the same time, and finally combine them into a complete file. Such a download would theoretically be 100 times faster than downloading from a single person. This is the main working logic of IPFS.
The data structure of the data block is roughly as follows:
data: contains data not exceeding 256 kb.
links: Links to other data blocks.
If a file is very large, its content will first be generated into N data blocks, and then a data block will be created from above them, with links pointing to all other data blocks.
When we upload files on IPFS, we need to go through the following steps.
- IPFS first divides the file into several small data blocks with a unit of 256 kb, and then stamps hash fingerprints on them. A hash fingerprint is a unique string that corresponds to a data block one-to-one.
- Then IPFS performs hash operation on the hash value of every two small data blocks to get a new hash. It will repeat this process until all the hash values of all data blocks are calculated into one hash value. The final hash value is Root Hash, also called CID (Content Identifier). This process is the process of building Merkle DAG, which is the core principle of IPFS.
- IPFS will remove duplicate files. Because each file will correspond to a hash value, the same hash value means that it is a duplicate file. IPFS will remove duplicate files, but each node can keep a backup of this node.
- Each IPFS will store the data it needs, and use DHT to record what data each node stores. DHT is a mapping of content ID (CID) and user ID (PeerID). IPFS will send our file information to all other online nodes, but it is not a real file, but a structure. Contains CID and PeerID. Each node updates its own hash table. So the process is very fast. It's like copying the variable address in the program instead of copying the actual variable memory space.
- When we need to obtain a file, we will use the hash value of the file to find out who's computer the file is on, and then download it from these people's computers. If the files we need are stored on the computers of 100 people, and now these 100 people are online at the same time, then we can transfer files with these 100 people at the same time, and finally combine them into a complete file. Such a download would theoretically be 100 times faster than downloading from a single person. This is the main working logic of IPFS.
The data structure of the data block is roughly as follows:
data: contains data not exceeding 256 kb.
links: Links to other data blocks.
If a file is very large, its content will first be generated into N data blocks, and then a data block will be created from above them, with links pointing to all other data blocks.
Why does IPFS need Git?
Once the content of the file changes, the original hash value will become invalid. So the file content of IPFS is immutable.
But what if we need to update the content of the file?
In order to track file updates, IPFS introduces a version control model, which is basically the same as Git.
When we first upload a file to IPFS. IPFS will create a Commit object. Its structure is roughly as follows:
- parent: point to the previous commit, the first commit points to none.
- object: file content.
If we need to update the content of the file, first upload the new file to IPFS.
IPFS will create a new Commit object for us, and its commit will point to the previous commit object.
This way we can track changes to the contents of the file.
Once the content of the file changes, the original hash value will become invalid. So the file content of IPFS is immutable.
But what if we need to update the content of the file?
In order to track file updates, IPFS introduces a version control model, which is basically the same as Git.
When we first upload a file to IPFS. IPFS will create a Commit object. Its structure is roughly as follows:
- parent: point to the previous commit, the first commit points to none.
- object: file content.
If we need to update the content of the file, first upload the new file to IPFS.
IPFS will create a new Commit object for us, and its commit will point to the previous commit object.
This way we can track changes to the contents of the file.
IPFS cannot ensure resources are always available
If all nodes that own a certain resource go offline, the resource will never be downloaded. It's like BT download without seeds.
In order to solve this problem, we need a corresponding solution.
IPFS has two schemes.
- Through the incentive mechanism, nodes are encouraged to store more files and share them online for a long time.
- Proactively distribute files to ensure there is always an online backup.
And this incentive mechanism is Filecoin. We will talk about Filecoin later.
If all nodes that own a certain resource go offline, the resource will never be downloaded. It's like BT download without seeds.
In order to solve this problem, we need a corresponding solution.
IPFS has two schemes.
- Through the incentive mechanism, nodes are encouraged to store more files and share them online for a long time.
- Proactively distribute files to ensure there is always an online backup.
And this incentive mechanism is Filecoin. We will talk about Filecoin later.
What is the relationship between IPFS and blockchain?
Strictly speaking, there is no relationship between the two, and IPFS does not use any blockchain technology. However, people in the blockchain industry still know about IPFS because Filecoin, another product of the IPFS team, is related to the blockchain.
Strictly speaking, there is no relationship between the two, and IPFS does not use any blockchain technology. However, people in the blockchain industry still know about IPFS because Filecoin, another product of the IPFS team, is related to the blockchain.
The relationship between IPFS and Filecoin
Filecoin is a blockchain application, which can be simply understood as a digital currency.
There is no direct relationship between the two, just two products of one team.
However, IPFS will provide underlying support for Filecoin, and Filecoin will also inject more vitality into IPFS.
We mentioned in the operating principle of IPFS that we end up downloading files on other users' computers, and downloading from other users' computers requires a certain network cost. In order to encourage everyone to share resources with others, IPFS has an incentive model called BitSwap.
If our computer has a lot of free storage space, we can store resources through Filecoin and share them with others. And when we share it with others, we will be rewarded with Filecoin.
Filecoin is a blockchain application, which can be simply understood as a digital currency.
There is no direct relationship between the two, just two products of one team.
However, IPFS will provide underlying support for Filecoin, and Filecoin will also inject more vitality into IPFS.
We mentioned in the operating principle of IPFS that we end up downloading files on other users' computers, and downloading from other users' computers requires a certain network cost. In order to encourage everyone to share resources with others, IPFS has an incentive model called BitSwap.
If our computer has a lot of free storage space, we can store resources through Filecoin and share them with others. And when we share it with others, we will be rewarded with Filecoin.
Why is IPFS called IPFS?
IPFS is called the Interplanetary File System. This name is not just because of cool, futuristic or sci-fi sense. Rather it's really good for transferring data between the stars.
Juan's ambition is not just to replace the Internet. Elon Musk is thinking of ways to allow humans to migrate to Mars, but he certainly won't let all people on Earth migrate to Mars at once. In the future, it is very likely that some people will be on the earth and some people will be on Mars.
If a website on Earth is obtained from Mars, the delay is very long, and it takes 4-24 minutes to transmit a signal. A round trip takes 8-48 minutes. This delay is very unbearable. But once any person on Mars obtains this webpage, other Martians can avoid this delay by obtaining the webpage of this person's computer.
So IPFS is a veritable universe-level transport protocol.
IPFS is called the Interplanetary File System. This name is not just because of cool, futuristic or sci-fi sense. Rather it's really good for transferring data between the stars.
Juan's ambition is not just to replace the Internet. Elon Musk is thinking of ways to allow humans to migrate to Mars, but he certainly won't let all people on Earth migrate to Mars at once. In the future, it is very likely that some people will be on the earth and some people will be on Mars.
If a website on Earth is obtained from Mars, the delay is very long, and it takes 4-24 minutes to transmit a signal. A round trip takes 8-48 minutes. This delay is very unbearable. But once any person on Mars obtains this webpage, other Martians can avoid this delay by obtaining the webpage of this person's computer.
So IPFS is a veritable universe-level transport protocol.
How is IPFS used?
The official website of IPFS is ipfs.tech/.
There is an installation method in the middle of the official website. There are two ways to install IPFS, desktop client and CLI.
We chose to download the desktop client.
We mainly participate in the IPFS network through this client.
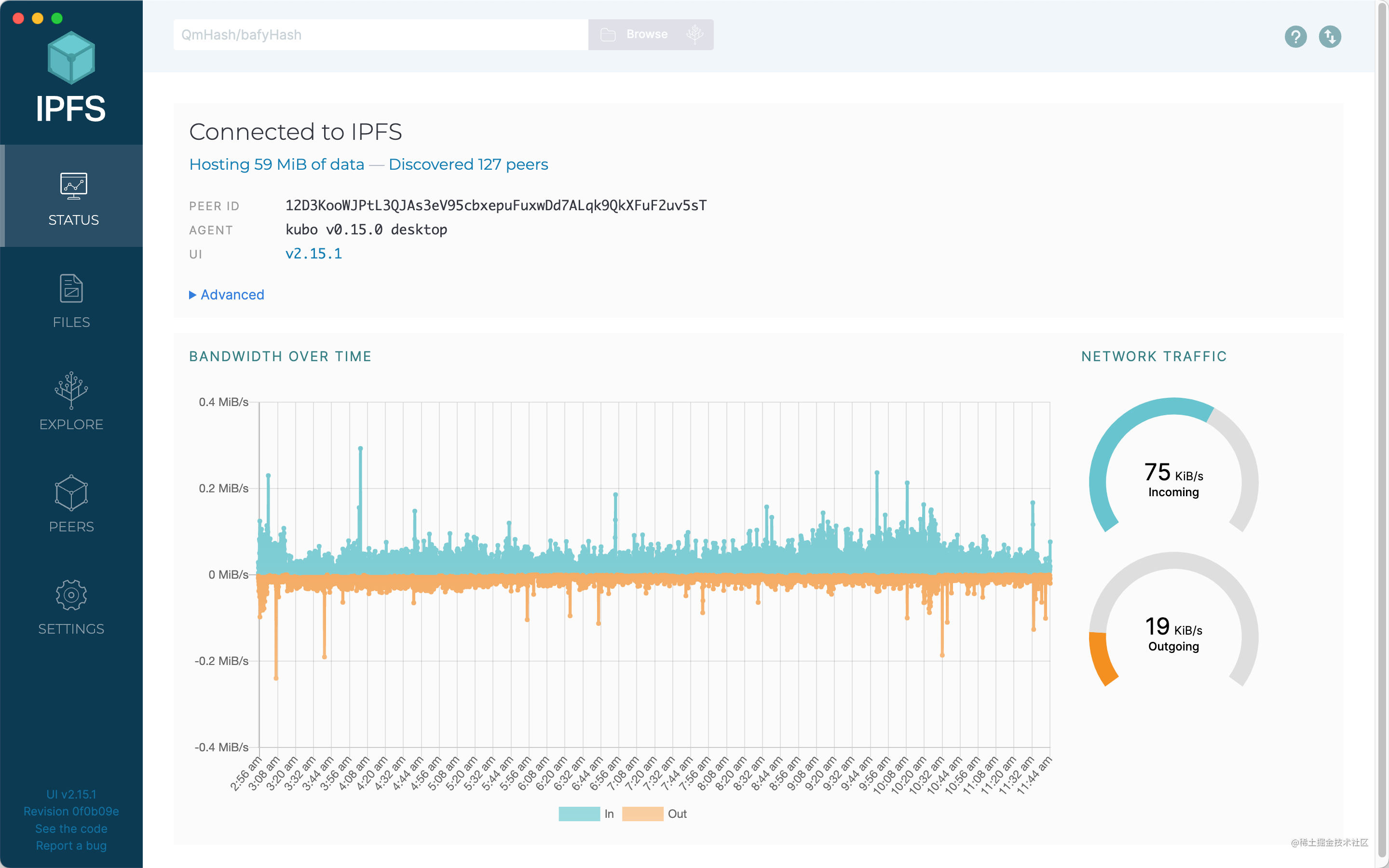
There are five menus on the left, and I will introduce their functions respectively.
The official website of IPFS is ipfs.tech/.
There is an installation method in the middle of the official website. There are two ways to install IPFS, desktop client and CLI.
We chose to download the desktop client.
We mainly participate in the IPFS network through this client.
There are five menus on the left, and I will introduce their functions respectively.
Status
This page is some general data, including information such as managed data size, online nodes, node ID, agent version, UI version, and real-time bandwidth.
This page is some general data, including information such as managed data size, online nodes, node ID, agent version, UI version, and real-time bandwidth.
Files
Here you can upload and delete files.
Click the import button to select the uploaded file or folder.
Its upload speed is very fast, but it does not actually upload the file. It just hashes the file and distributes the CID and PID to all currently online nodes.
After the upload is complete, we will get a CID. Click the three dots on the right side of the file and select Copy CID to share this CID with other IPFS users.
After other users get the CID, they can search in the search box at the top of the IPFS client.
If you can find it, you can preview or download it.
In addition, the IPFS protocol can also be used in the browser. Enter ipfs://{cid} directly in the browser to open the file resource directly. However, this requires the IPFS client to be started locally.
If IPFS develops very smoothly in the future, this function may be built into the browser instead of starting the client separately.
Here you can upload and delete files.
Click the import button to select the uploaded file or folder.
Its upload speed is very fast, but it does not actually upload the file. It just hashes the file and distributes the CID and PID to all currently online nodes.
After the upload is complete, we will get a CID. Click the three dots on the right side of the file and select Copy CID to share this CID with other IPFS users.
After other users get the CID, they can search in the search box at the top of the IPFS client.
If you can find it, you can preview or download it.
In addition, the IPFS protocol can also be used in the browser. Enter ipfs://{cid} directly in the browser to open the file resource directly. However, this requires the IPFS client to be started locally.
If IPFS develops very smoothly in the future, this function may be built into the browser instead of starting the client separately.
Explore
Here you can search for CID, get addressable IPLD nodes, file objects, CID information, etc.
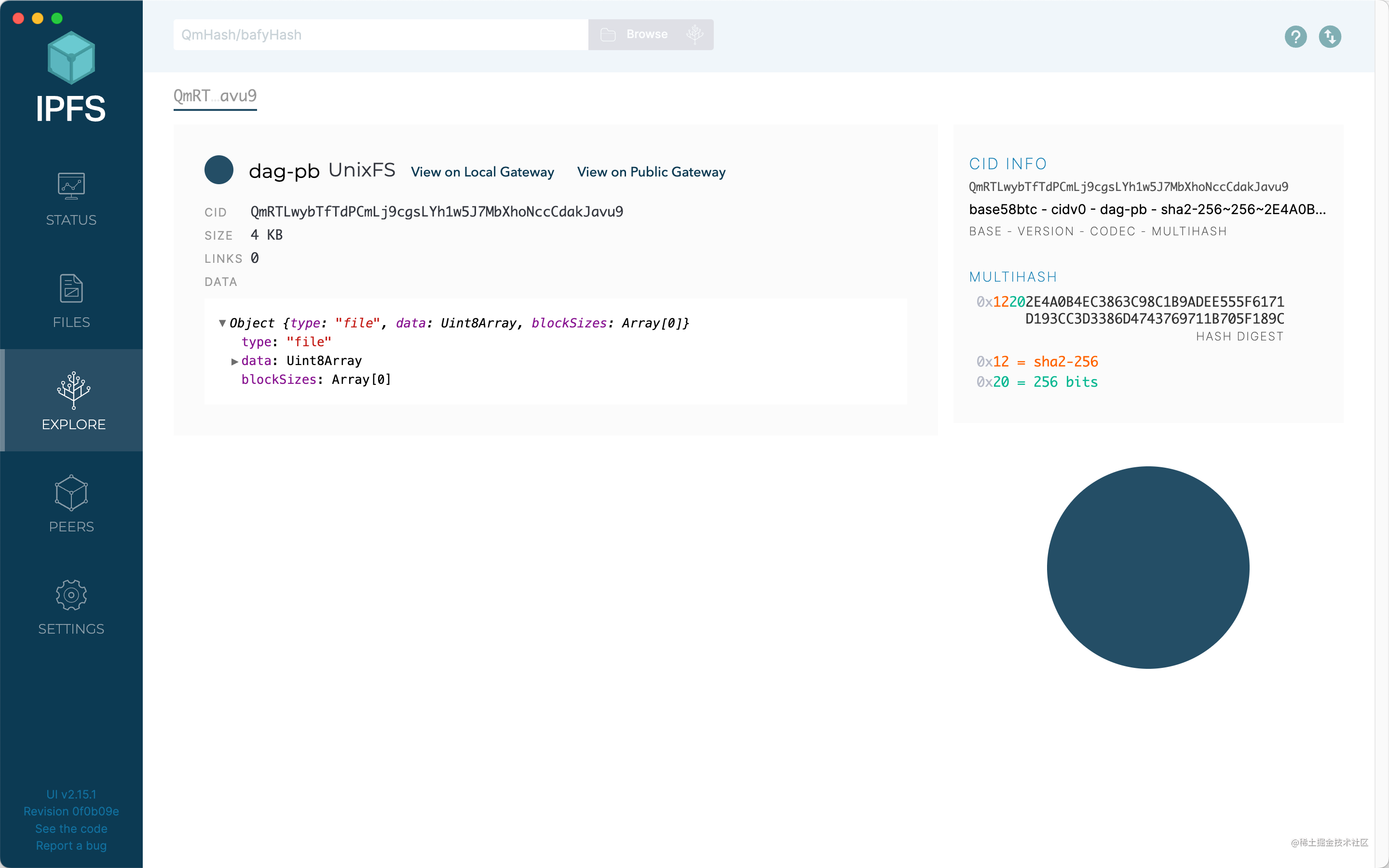
Here you can search for CID, get addressable IPLD nodes, file objects, CID information, etc.
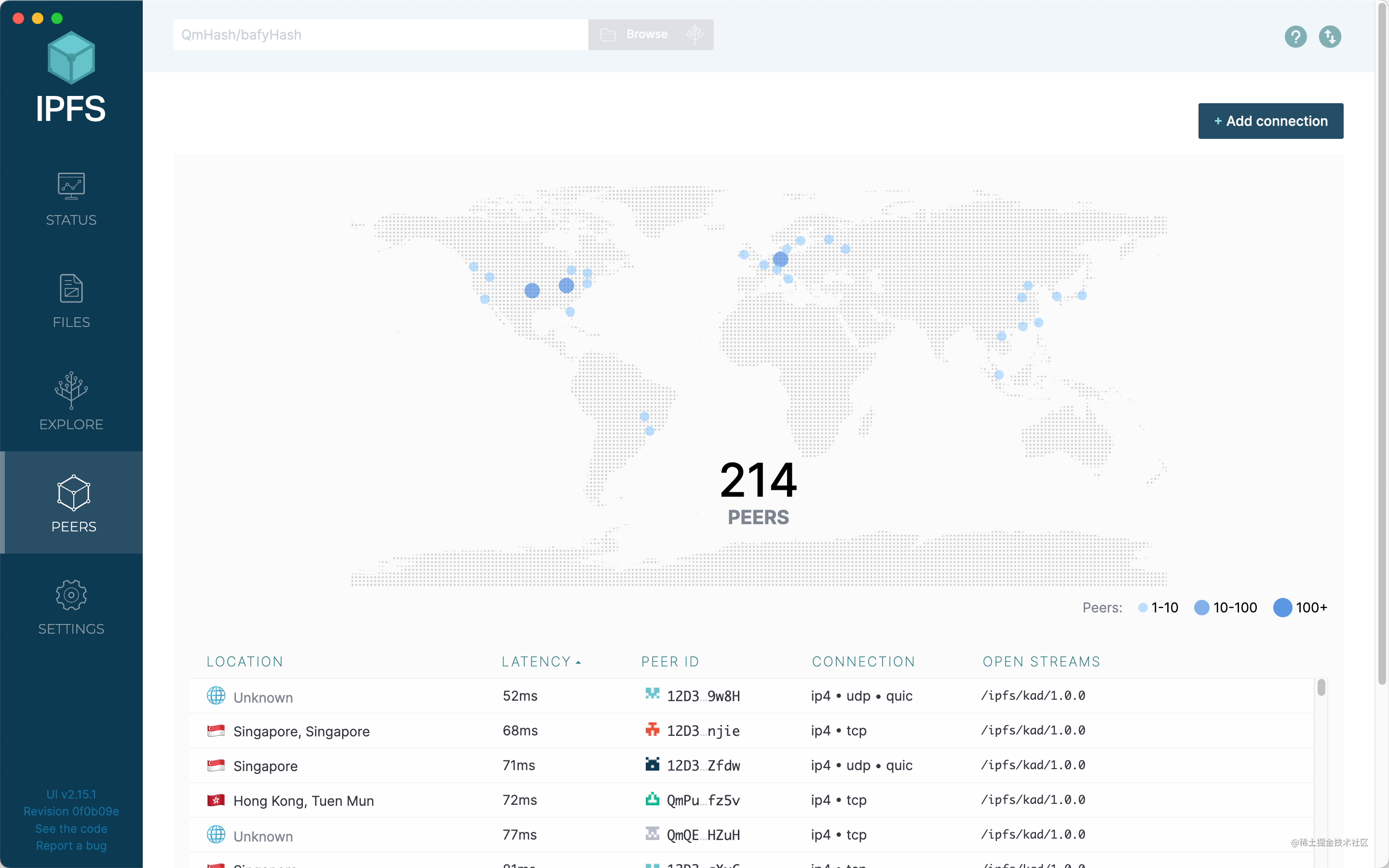
Peers
Here you can see information about other nodes.
Including the physical address of the node, delay, node ID, transmission protocol, connection protocol, etc.
The more nodes there are, the better our experience will be.
Here you can see information about other nodes.
Including the physical address of the node, delay, node ID, transmission protocol, connection protocol, etc.
The more nodes there are, the better our experience will be.
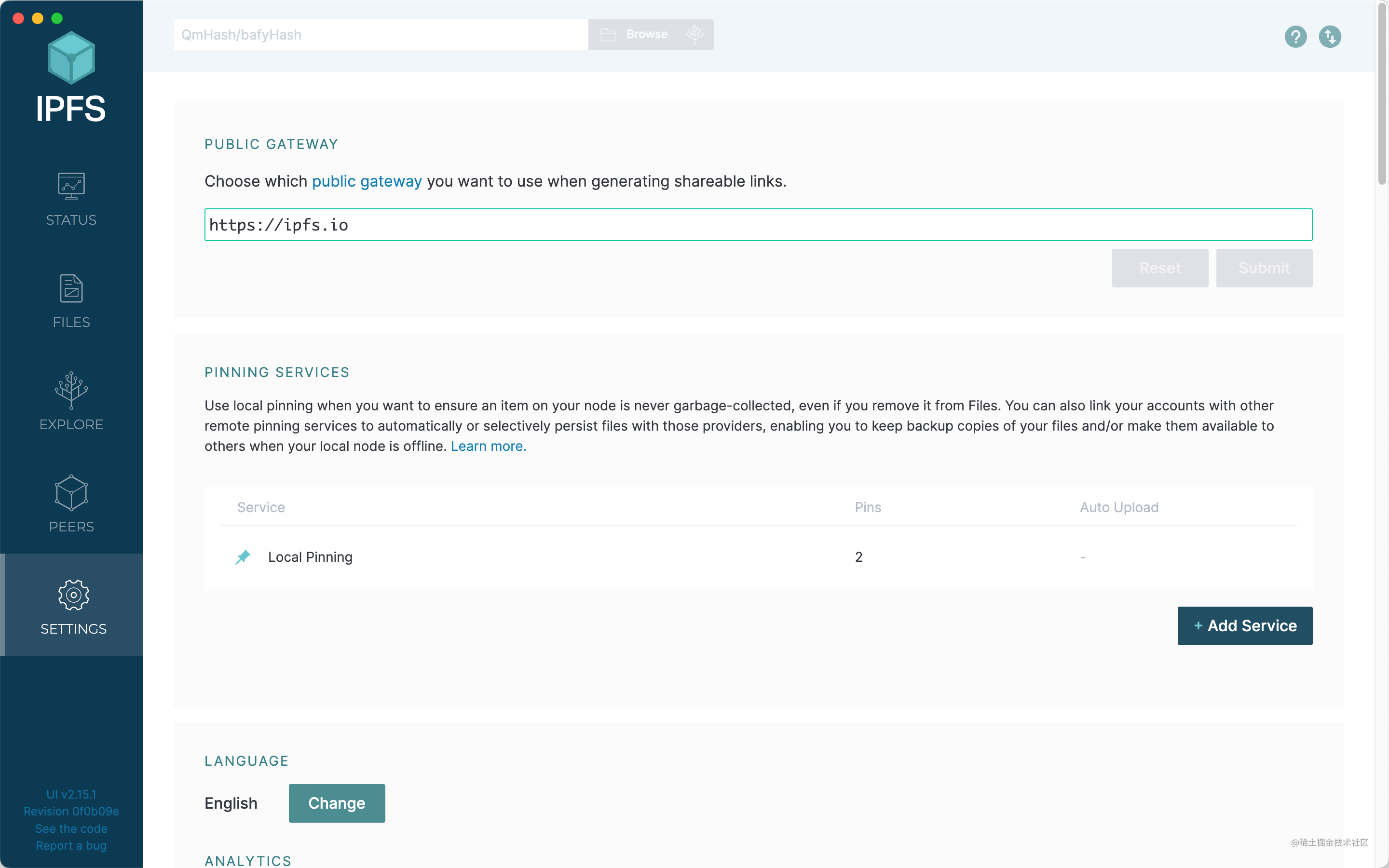
Settings
Here you can modify the gateway, fixed service, language, IPFS JSON configuration and other content of the shared link.
Here you can modify the gateway, fixed service, language, IPFS JSON configuration and other content of the shared link.
Disadvantages of IPFS and Pin Services
Talking about so many advantages of IPFS, IPFS seems to be a technology that is infinitely tending to perfection.
But is it really flawless? Not really. IPFS also has a shortcoming that all P2P applications have, that is, if all nodes holding a certain file go offline, we will no longer be able to download this file.
This problem is also easy to solve. If we want a file to be downloaded forever, then we can store this file in our local IPFS system, and our local IPFS is always online.
But obviously, if you leave the computer on 24 hours a day, it is no different from a server.
Isn't this kind of thing renting a certain cloud service in Web2.0? There are also people in Web3 who do this.
This kind of service is called Pin service, which means fixed.
The role of the Pin service is to pin a file in the IPFS system.
Pinata is a platform dedicated to providing IPFS Pin services for NFTs, and it is also one of the largest Pin service platforms currently in the IPFS ecosystem.
However, Pinata is not free, and similar platforms are also like this. They are charged according to certain rules, which is a bit like the network disk in the Web2.0 era.
Some people think that this solution is not a long-term feasible solution, because when the fixed file size is very large, the price of Pinata will also be very expensive, and the current highest price is 1,000 US dollars per month.
In fact, it is not difficult to conclude that in the current Internet world, there is no 100% free, absolutely decentralized, and absolutely guaranteed permanent storage.
If this vision is really to be realized, then everyone needs to have a network storage device that is powered on online 7*24 hours a day. It's a bit like some science fiction idea that humans are born with a device implanted in their bodies. Humans can even rewrite genes, allowing babies to develop this device from their mothers, just like one of our organs, except that it can store data and connect to other people.
I can assert that this era will eventually come. The speed of entering this era will depend on the development of a series of technological fields such as energy, network, disk, and computing.
Talking about so many advantages of IPFS, IPFS seems to be a technology that is infinitely tending to perfection.
But is it really flawless? Not really. IPFS also has a shortcoming that all P2P applications have, that is, if all nodes holding a certain file go offline, we will no longer be able to download this file.
This problem is also easy to solve. If we want a file to be downloaded forever, then we can store this file in our local IPFS system, and our local IPFS is always online.
But obviously, if you leave the computer on 24 hours a day, it is no different from a server.
Isn't this kind of thing renting a certain cloud service in Web2.0? There are also people in Web3 who do this.
This kind of service is called Pin service, which means fixed.
The role of the Pin service is to pin a file in the IPFS system.
Pinata is a platform dedicated to providing IPFS Pin services for NFTs, and it is also one of the largest Pin service platforms currently in the IPFS ecosystem.
However, Pinata is not free, and similar platforms are also like this. They are charged according to certain rules, which is a bit like the network disk in the Web2.0 era.
Some people think that this solution is not a long-term feasible solution, because when the fixed file size is very large, the price of Pinata will also be very expensive, and the current highest price is 1,000 US dollars per month.
In fact, it is not difficult to conclude that in the current Internet world, there is no 100% free, absolutely decentralized, and absolutely guaranteed permanent storage.
If this vision is really to be realized, then everyone needs to have a network storage device that is powered on online 7*24 hours a day. It's a bit like some science fiction idea that humans are born with a device implanted in their bodies. Humans can even rewrite genes, allowing babies to develop this device from their mothers, just like one of our organs, except that it can store data and connect to other people.
I can assert that this era will eventually come. The speed of entering this era will depend on the development of a series of technological fields such as energy, network, disk, and computing.