When the Network Transport Protocol SRD meets the DPU

When the Network Transport Protocol SRD meets the DPU

What?
SRD (Scalable Reliable Datagram) is a protocol introduced by AWS to solve Amazon's cloud performance challenges. It is a high-throughput, low-latency network transmission protocol designed for AWS data center networks, based on Nitro chips, and implemented to improve HPC performance.
{kind=link}
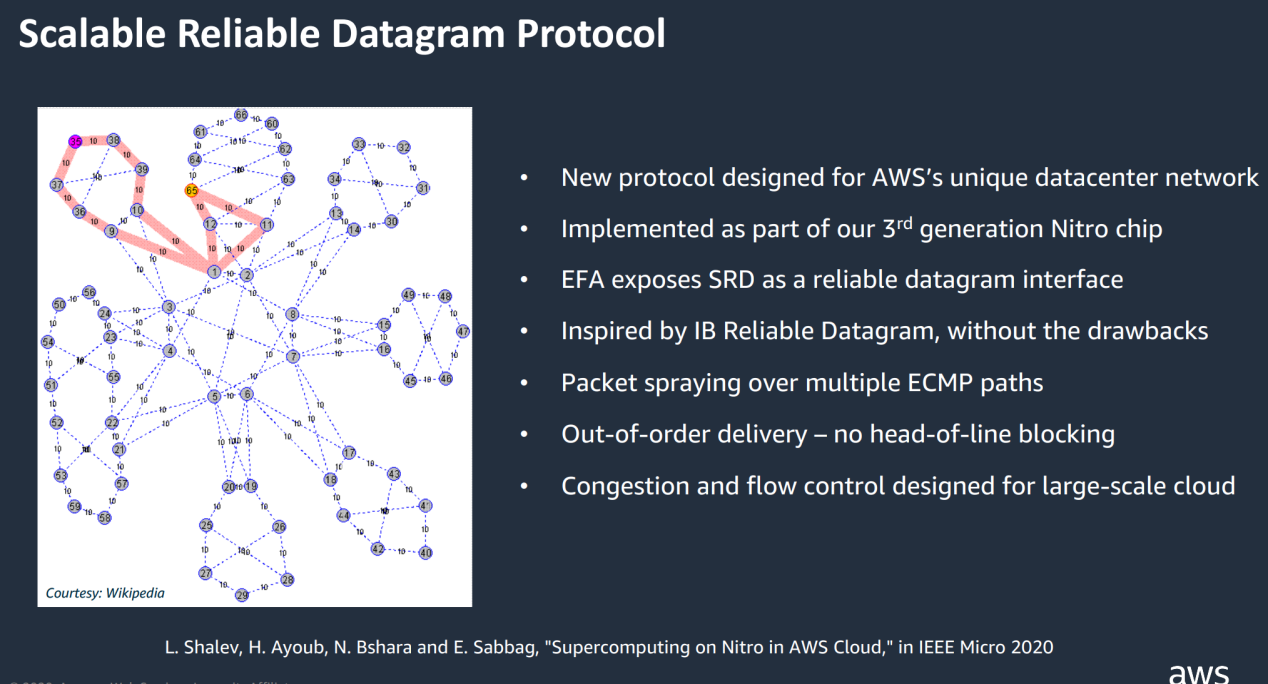
Instead of preserving packet order, SRD sends packets through as many network paths as possible while avoiding path overload. To minimize jitter and ensure the fastest response to network congestion fluctuations, SRD is implemented in AWS-developed Nitro chip.
SRD is used by the HPC/ML framework on EC2 hosts through the AWS EFA (Elastic Fabric Adapter) kernel bypass interface.
Features of SRD:
- The packet order is not preserved and is handled by the upper messaging layer
- Through as many network paths as possible, using the ECMP standard, the origination control packet encapsulation controls the ECMP path selection to achieve multi-path load balancing
- Its own congestion control algorithm, dynamic rate limiting based on each connection, combined with RTT (Round Trip Time) flight time to detect congestion, can quickly recover from packet loss or link failure
- Due to out-of-order packet issuance and lack of fragmentation, the QP (queue pair) required for SRD transmission is significantly reduced
Why?
Why not TCP?
TCP is the primary means of reliable data transmission in IP networks, has served the Internet well since its inception, and remains the best protocol for most communications. However, it is not suitable for latency-sensitive processing, the best round-trip latency of TCP in the data center is almost 25us, and the outlier due to congestion (or link failure) wait can be 50 ms, or even seconds, and the main reason for these delays is the retransmission mechanism after TCP packet loss. In addition, TCP transmission is a one-to-one connection, even if the delay problem is solved, it is difficult to quickly reconnect in the event of a failure.
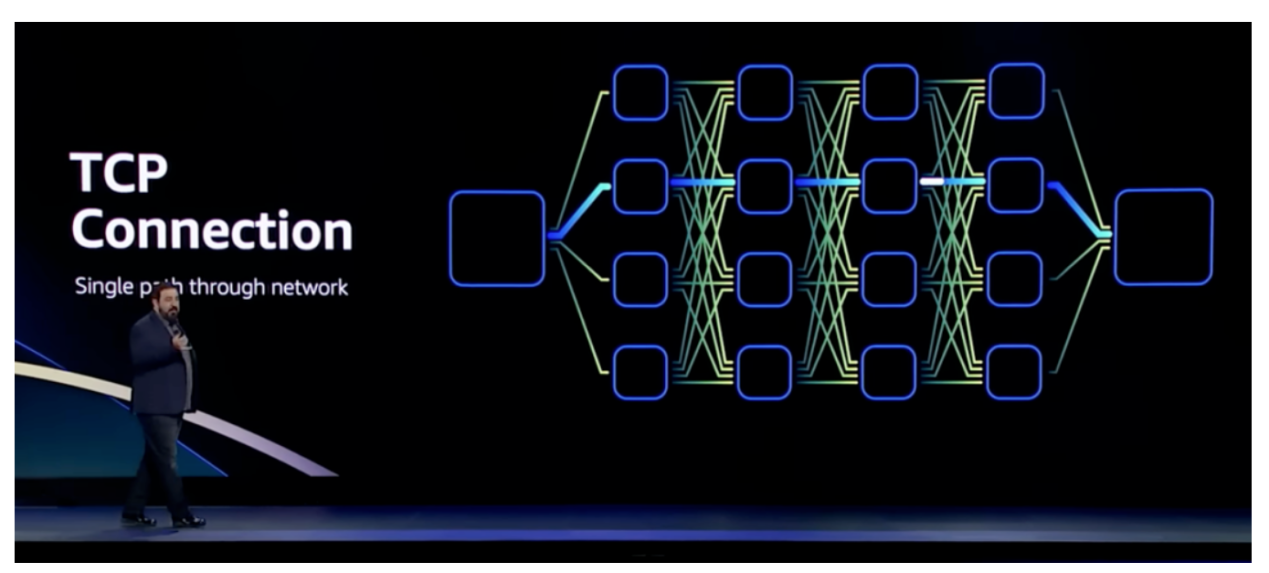
TCP is a generic protocol that is not optimized for HPC scenarios, and back in 2020, AWS proposed the need to remove TCP.
Why not RoCE?
InfiniBand is a popular high-throughput, low-latency interconnect for high-performance computing that supports kernel bypass and transport offloading. RoCE (RDMA over Converged Ethernet), also known as InfiniBand over Ethernet, allows InfiniBand transport to run over Ethernet and could theoretically provide an alternative to TCP in AWS data centers.
The EFA host interface is very similar to the InfiniBand/RoCE interface. However, InfiniBand transport does not fit into AWS scalability requirements. One reason is that RoCE requires PFC (Priority Flow Control), which is not feasible on large networks because it causes head-of-line congestion, congestion proliferation, and occasional deadlocks. PFC is better suited for smaller data centers than AWS. In addition, even with PFC, RoCE suffers from ECMP (Equal Cost Multipath Routing) conflicts under congestion (similar to TCP) and suboptimal congestion control.
Why SRD?
SRD is a reliable, high-performance, low-latency network transmission designed specifically for AWS. This is a major improvement in data transfer over data center networks. SRD is inspired by InfiniBand reliable datagrams, combined with large-scale cloud computing scenarios, SRD has also undergone many changes and improvements. SRD leverages the resources and features of cloud computing, such as AWS's complex multipath backbone network, to support new transport strategies that deliver value in tightly coupled workloads.
任何真实的网络中都会出现丢包、拥塞阻塞等一系列问题。这不是说每天会发生一次的事情,而是一直在发生。
大多数协议(如 TCP)是按顺序发送数据包,这意味着单个数据包丢失会扰乱队列中所有数据包的准时到达(这种效应称为“队头阻塞”)。而这实际上会对丢包恢复和吞吐量产生巨大影响。
SRD 的创新在于有意通过多个路径分别发包,虽然包到达后通常是乱序的,但AWS实现了在接收处以极快的速度进行重新排序,最终在充分利用网络吞吐能力的基础上,极大地降低了传输延迟。
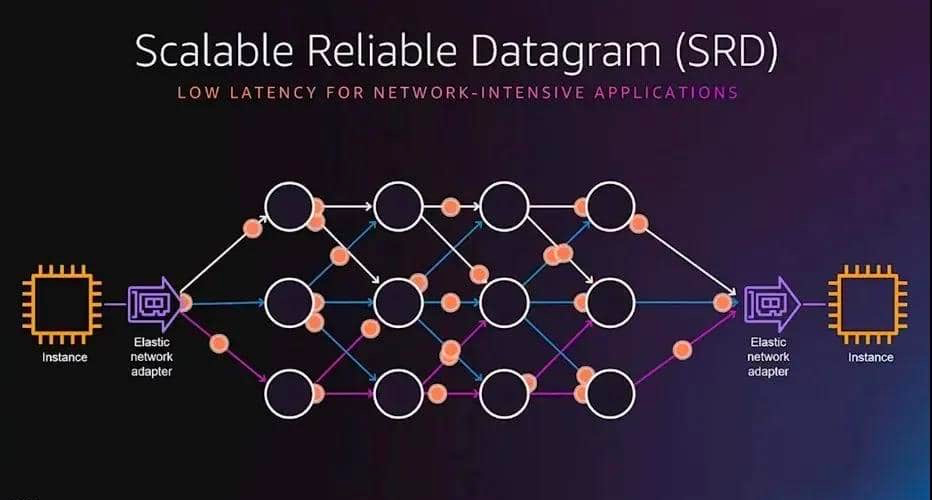
SRD can push all packets that make up a block to all possible paths at once, which means that SRD is not affected by head-of-line blocking and can recover faster from packet loss scenarios to maintain high throughput.
{kind=link}
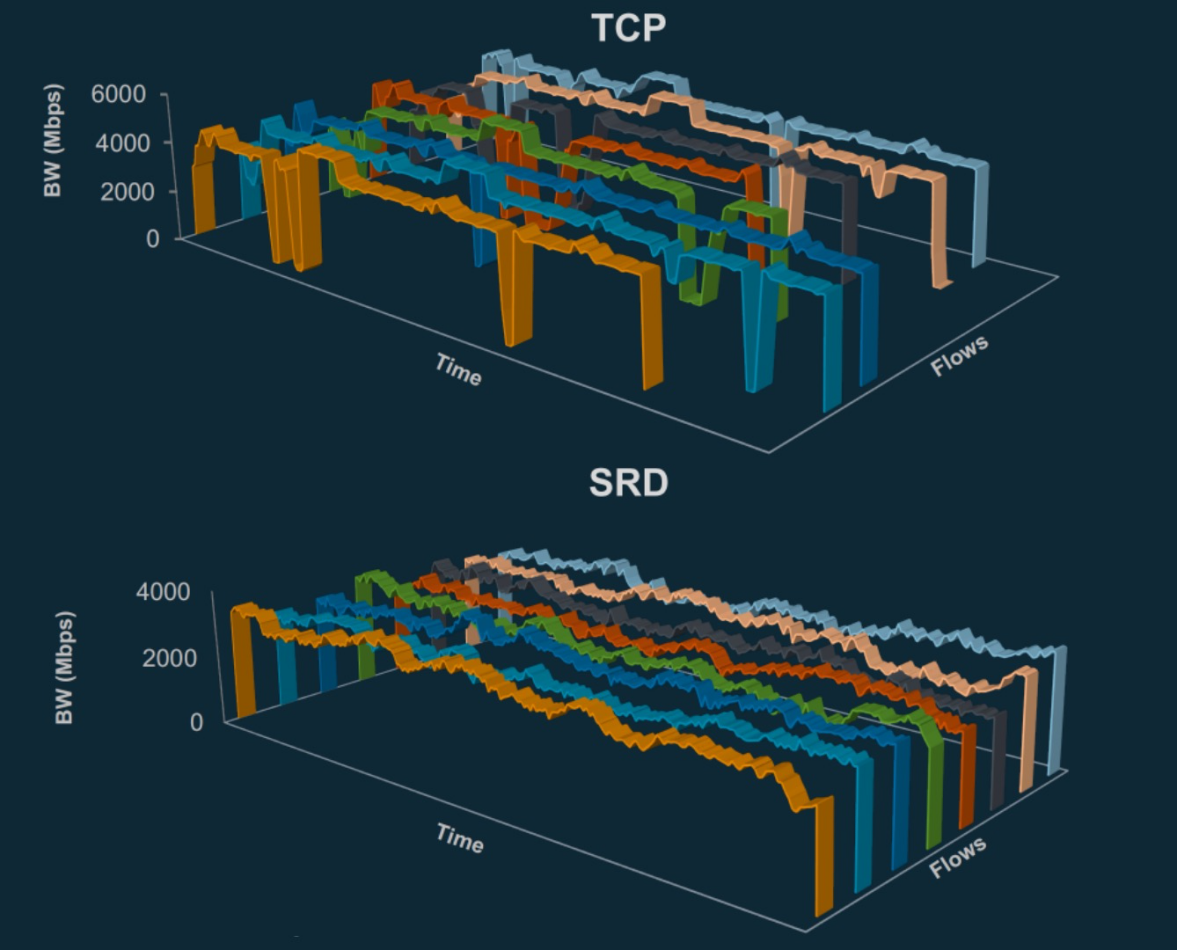
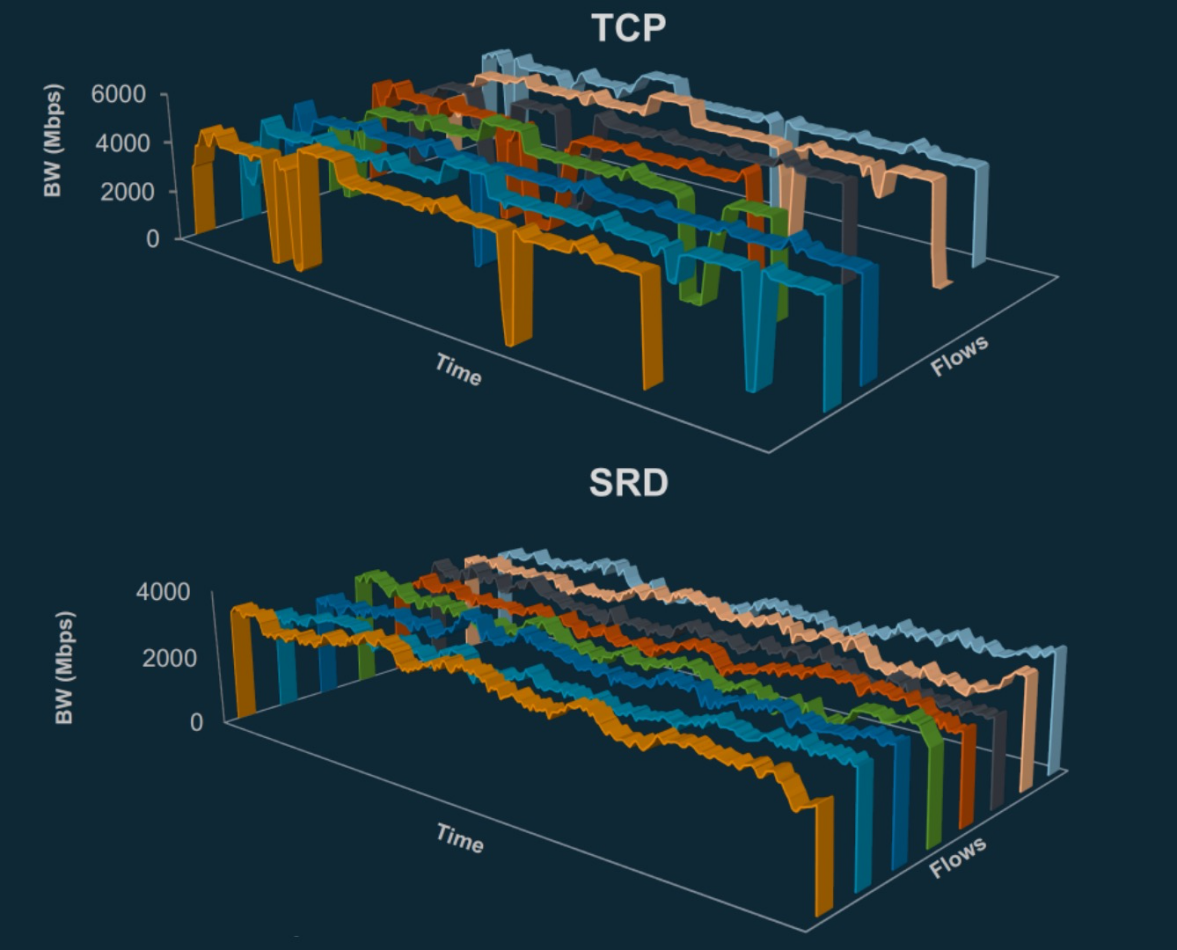
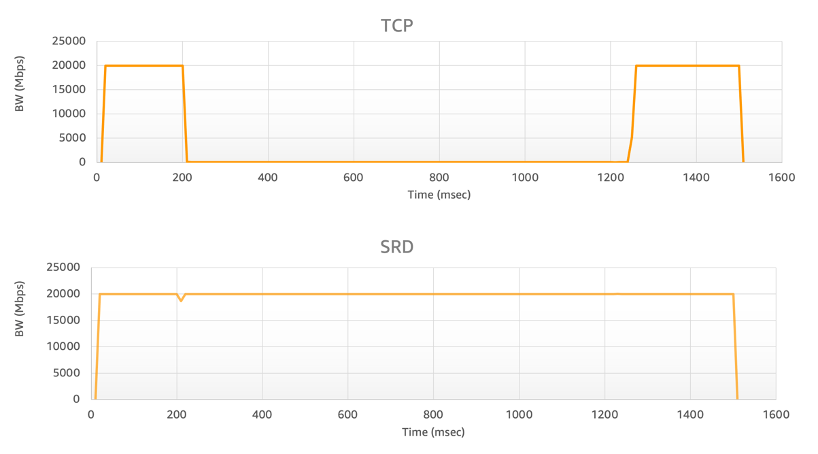
As we all know, the P99 tail delay means that only 1% of requests are allowed to slow down, but this also reflects the final performance of all packet loss, retransmission, and congestion in the network, and it is more indicative of the "real" network situation. SRD causes the P99 tail delay to plummet (approximately 10 times).
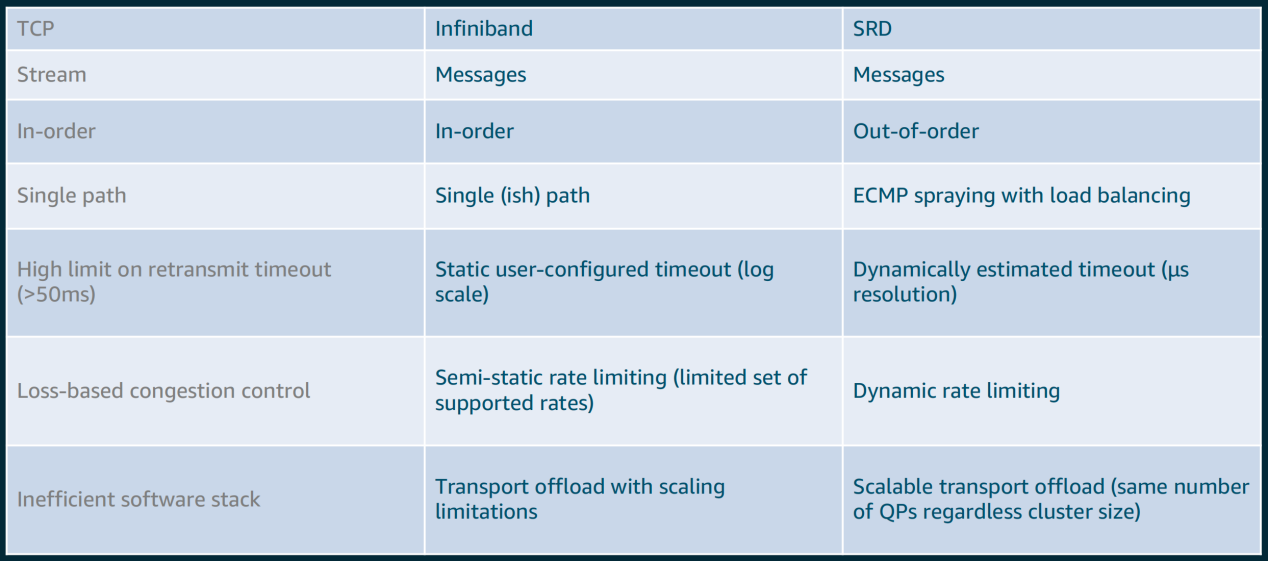
Key features of SRD include:
- Out-of-order delivery: Removing the constraint of delivering messages sequentially, eliminating head-of-line blocking, AWS implemented a packet reordering processing engine in the EFA user-space software stack
- Equal Cost Multipath Routing (ECMP): There may be hundreds of paths between two EFA instances, and the most efficient path for a message can be found by using the properties of consistent flow hashes of large multipath networks and the SRD's ability to react quickly to network conditions. Packet Spraying prevents congestion hotspots and can recover quickly and insensitively from network failures
- Fast packet loss response: SRD responds to packet loss much faster than any higher-level protocol. Occasional packet loss, especially for long-running HPC applications, is part of normal network operation and is not an anomaly
- Scalable transport offload: With SRD, unlike other reliable protocols such as InfiniBand Reliable Connection IBRC, a process can create and use a queue pair to communicate with any number of peers
How
The key to how SRD actually works is not the protocol, but how it is implemented in hardware. In other words, for now, SRD is only valid when using AWS Nitro DPUs.
Packets delivered out of order by SRD need to be reordered to be read by the operating system, and processing the chaotic packet flow obviously cannot be expected from the CPU of the "day-to-day" machine. Even if the CPU is fully responsible for the SRD protocol and reassembles the packet stream, it is undoubtedly an anti-aircraft gun to beat the mosquito - overkill, which will keep the system busy with things that shouldn't take too much time, and there will be no real performance improvement.
在SRD这一不寻常的“协议保证”下,当网络中的并行导致数据包无序到达时,AWS将消息顺序恢复留给上层,因为它对所需的排序语义有更好的理解,并选择在AWS Nitro卡中实施SRD可靠性层。其目标是让SRD尽可能靠近物理网络层,并避免主机操作系统和管理程序注入的性能噪音。这允许快速适应网络行为:快速重传并迅速减速以响应队列建立。
When AWS says they want the packets to be reassembled "on the stack," they're actually saying they want the DPU to finish putting the pieces back together before returning the packets to the system. The system itself does not know that the packets are out of order. The system doesn't even know how the packet arrived. It only knows that it sent data elsewhere and arrived without error.
The key here is the DPU. AWS SRD is only available for systems configured with Nitro in AWS. Many servers using AWS now have this additional hardware installed and configured, and the value is that enabling this feature will improve performance. Users need to specifically enable it on their own servers, and if they need to communicate with devices that do not have SRD enabled or Nitro DPU configured, they will not get a corresponding performance gain.
As for whether SRD, which many people care about, will be open source in the future, we can only say that let's wait and see!