Do you know what disaster tolerance is?
2021.11.12

Whether it is 3G, 4G or 5G, each operator has established a
disaster recovery site for the communication business in the region. In
addition to ensuring the reliability of various types of data, the disaster
recovery site can also ensure the availability of services. This is the most
important significance of establishing a disaster recovery system.

You have no accident. If an earthquake or other natural
disaster occurs, will your account information in a certain bank be lost?

In fact, this does not require us to worry about it. Bank
user information is very important data. Therefore, before the bank is opened,
it must have a complete set of disaster tolerance solutions to solve such
problems, that is, establish a disaster tolerance system.
The so-called disaster tolerance system, literally
understood, refers to a system that tolerates disasters. With this system, even
if a disaster strikes, the user data in the bank can be safe. This disaster can
range from a natural disaster to a physical failure. In order to ensure data
security and business reliability, each bank will establish one or several
disaster recovery sites in multiple regions of the country to back up data with
each other, which is equivalent to creating several "copies".
When the primary site is damaged by a disaster, resulting in
permanent data loss, the "copy" of the disaster-tolerant site can be
used to achieve data recovery. If there is no data backup at the disaster
recovery site, it will cause immeasurable economic losses and bad social
impact.
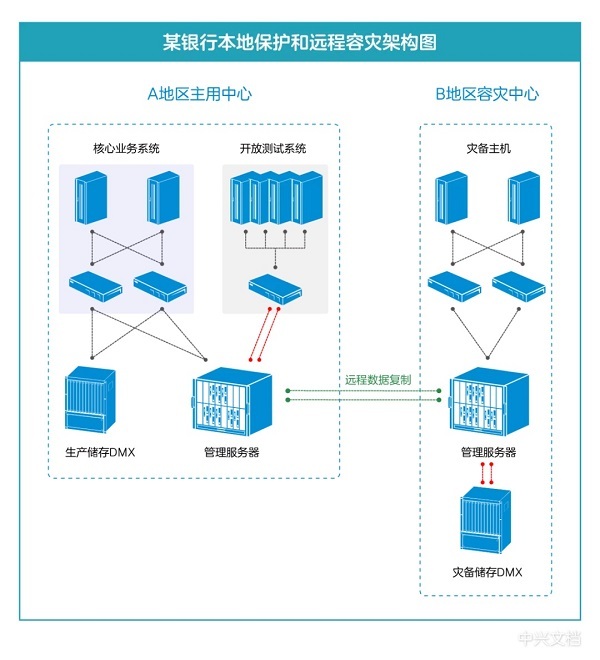
Banks have disaster tolerance systems. Does communications
have disaster tolerance systems? The answer is yes. Each operator has developed
a complete and rigorous disaster recovery solution to protect the communication
data of all users, including your call balance!
Whether it is 3G, 4G or 5G, each operator has established a
disaster recovery site for the communication business in the region. In
addition to ensuring the reliability of various types of data, the disaster
recovery site can also ensure the availability of services. This is the most
important significance of establishing a disaster recovery system.
Take 5GC as an example. Similar to the financial system, 5GC
also adopts cross-regional disaster recovery deployment methods. Deploy data
centers (DCs, Data Centers) in two different regions. When the network
equipment in a DC is unavailable for some reason, another DC will quickly take
over the business to ensure the availability of 5G services. This is the dual
DC deployment. Dual DC deployment is a way to achieve deployment reliability.
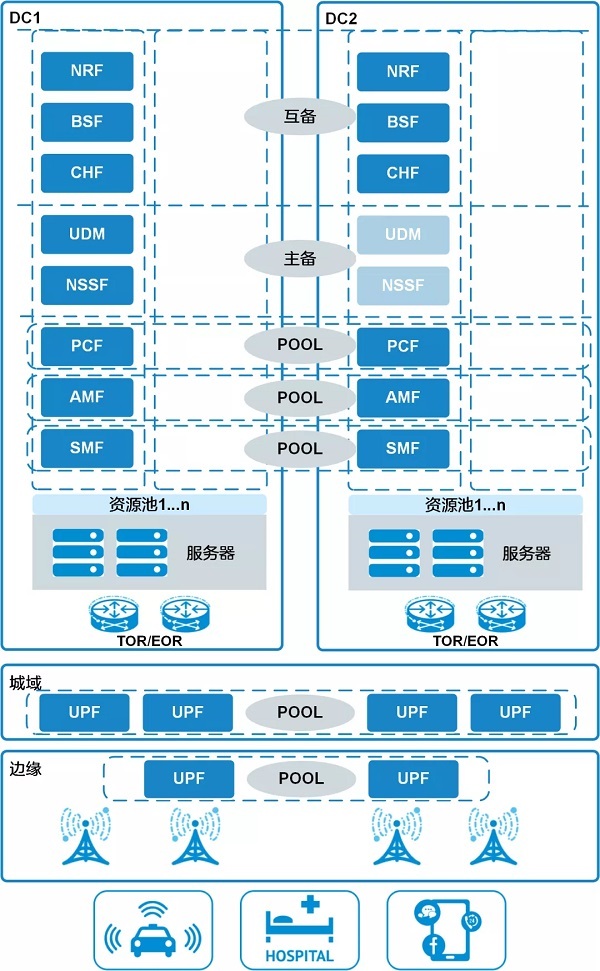
In addition to dual DC deployment, what measures does the 5GC disaster recovery solution provide to achieve disaster recovery?
 Pic
Pic
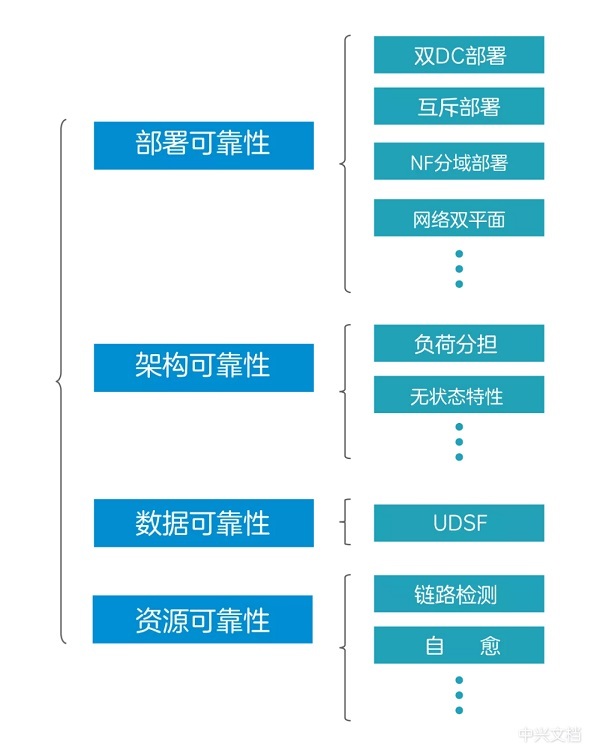
Deployment reliability
The 5GC disaster recovery solution supports dual DC
deployment, mutually exclusive deployment, NF (Network Function) domain
deployment, and network dual planes to achieve deployment reliability.
Mutually exclusive deployment refers to deploying virtual
machines on different physical machines to ensure that when a physical machine
is abnormal, other virtual machines can still provide services. In short, it is
"don't put eggs in one basket".
NF deployment by domain means that NF deployment adopts the
separation of management domain, service domain, and forwarding domain.
Network dual plane means that all logical network interfaces
of 5GC NF have at least two different physical network planes as backups for
each other. When one of the network planes fails, the other network plane can
take over all network traffic to ensure uninterrupted services.
Architecture reliability
The 5GC disaster tolerance solution supports load sharing
and stateless features to achieve architectural reliability.
Load sharing means that all running instances share the
processing business together. When some running instances go down abnormally,
the rest of the running instances share the processing business, so as to
ensure the normal operation of the business. Load sharing adopts the N+M
redundancy mode, that is, when N instances can meet the business processing of
the system capacity, M instances are provided for redundancy.
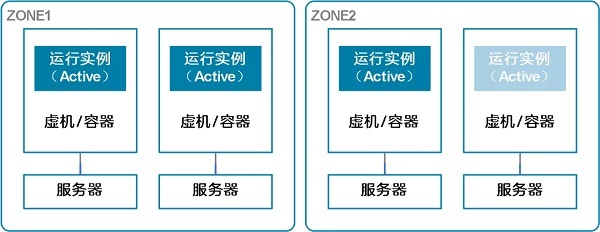
The above figure is a typical 3+1 redundancy mode. When 3
instances can meet the business processing of the system capacity, another
instance is provided for redundancy. When any one running instance fails, the
other three running instances continue to work, so as to ensure that the system
capacity and business processing are not affected.
Stateless refers to the stateless design of microservices.
3GPP defines UDSF (Unstructured Data Storage Function) for uniform storage of
NF state data (also known as unstructured data, such as mobile data, etc.).
The business logic APP can perform elasticity, expansion,
destruction, rebirth, and migration operations at any time. This is the
separation of computing and storage. Stateless design not only achieves
architecture reliability, but also guarantees data reliability.
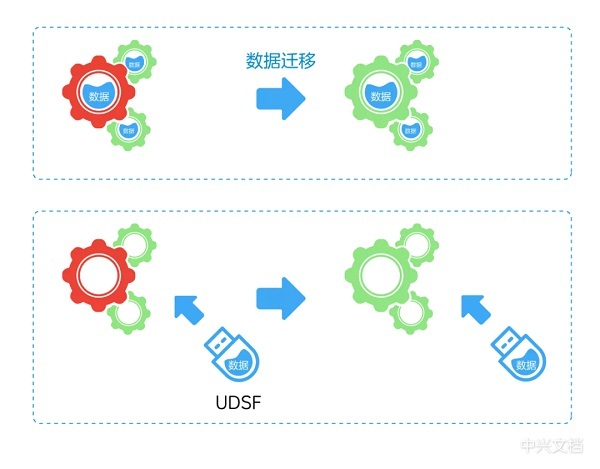
Data reliability
5GC's NF is designed in a stateless manner. After the
current processing flow is completed, state data such as the user and session
context are stored in the UDSF, and the UDSF saves multiple copies of the data.
UDSF supports 1+1 redundancy and dual-DC deployment disaster recovery mode to
ensure data reliability.
Resource reliability
The 5GC disaster tolerance solution supports mechanisms such
as link detection and self-healing to achieve resource reliability.
Self-healing refers to: For business processing nodes that
continue to fail, the system will perform multi-level self-healing of the
nodes. According to the user's self-healing strategy configuration, the system
successively adopts the strategy of restarting the container, re-pushing the
container, restarting the virtual machine, and rebuilding the virtual machine
step by step for self-healing, so as to restore the business as soon as
possible.
Link detection means that the business node will
periodically send heartbeat keep-alive messages to the management node. If the
management node detects a node that has not sent a heartbeat for a long time,
it is judged as a faulty node, which triggers the business migration process
and migrates the business of the faulty node To other normal nodes, so as to
ensure the reliability of the business.
Well, having said that, you don't have to worry about your
balance of phone bills anymore, let alone the money stored in the bank! You
also know what disaster tolerance is.