FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
2024.04.26

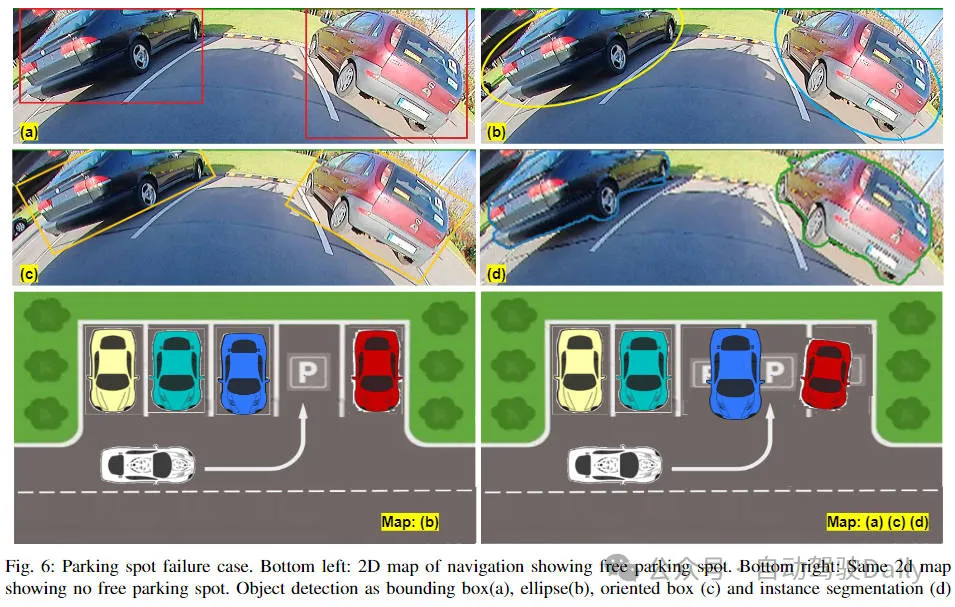
目標偵測在自動駕駛系統當中是一個比較成熟的問題,其中行人偵測是最早得以部署演算法之一。在多數論文當中已經進行了非常全面的研究。然而,利用魚眼相機進行環視的近距離的感知相對來說研究較少。由於徑向畸變較大,標準的邊界框表示在魚眼相機當中很難實施。為了緩解上述提到的相關問題,我們探討了擴展邊界框的標準物件偵測輸出表示。我們將旋轉的邊界框、橢圓、通用多邊形設計為極座標弧/角度表示,並定義一個實例分割mIOU度量來分析這些表示。所提出的具有多邊形的模型FisheyeDetNet優於其他模型,同時在用於自動駕駛的Valeo魚眼相機資料集上實現了49.5%的mAP指標。目前,這是第一個關於自動駕駛場景中基於魚眼相機的目標偵測演算法研究。
文章連結:https://arxiv.org/pdf/2404.13443.pdf
網路結構
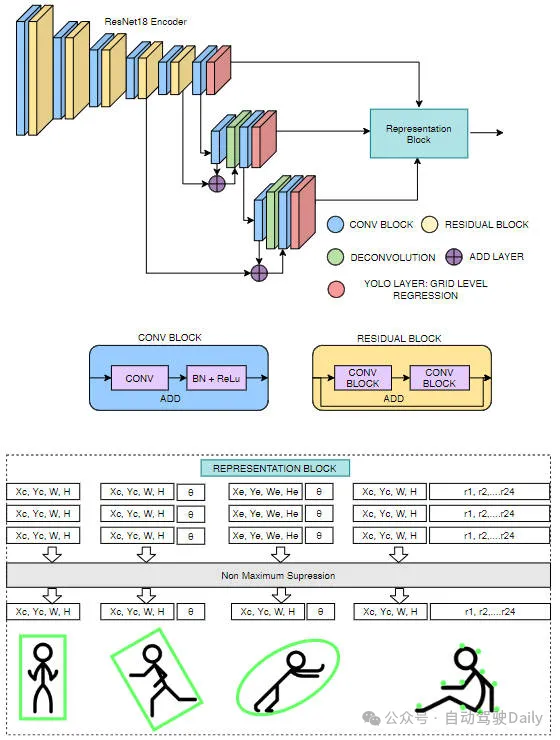
我們的網路結構建立在YOLOv3網路模型的基礎上,並且對邊界框,旋轉邊界框、橢圓以及多邊形等進行多種表示。為了使網路能夠移植到低功率汽車硬體上,我們使用ResNet18作為編碼器。與標準Darknet53編碼器相比,參數減少了近60%。提出了網路架構如下圖。
邊界框偵測
我們的邊界框模型與YOLOv3 相同,只是Darknet53 編碼器被替換為ResNet18 編碼器。與YOLOv3類似,目標偵測是在多個尺度上執行的。對於每個尺度中的每個網格,預測物件寬度()、高度()、物件中心座標(,)和物件類別。最後,使用非最大抑制來過濾冗餘檢測。
旋轉邊界框偵測
在這個模型中,與常規框資訊(,,,)一起回歸框的方向。方向地面實況範圍(-180 到+180°) 在-1 到+1 之間進行歸一化。
橢圓檢測
橢圓回歸與定向框回歸相同。唯一的區別是輸出表示。因此損失函數也與定向框損失相同。
多邊形檢測
我們提出的基於多邊形的實例分割方法與PolarMask和PolyYOLO方法非常相似。而不是使用稀疏多邊形點和像PolyYOLO這樣的單尺度預測。我們使用密集多邊形註釋和多尺度預測。
實驗對比
我們在Valeo魚眼資料集上評估,該資料集有60K 影像,這些影像是從歐洲、北美和亞洲的4 個環繞視圖相機捕獲的。
所有模型都使用IoU 閾值為50% 的平均精度度量(mAP) 進行比較。結果如下表所示。每個演算法都基於兩個標準進行評估—相同表示和實例分割的效能。