nuScenes最新SOTA | SparseAD:稀疏查詢協助高效端對端自動駕駛!
2024.04.17

寫在前面&出發點
端到端的范式使用统一的框架在自动驾驶系统中实现多任务。尽管这种范式具有简单性和清晰性,但端到端的自动驾驶方法在子任务上的性能仍然远远落后于单任务方法。同时,先前端到端方法中广泛使用的密集鸟瞰图(BEV)特征使得扩展到更多模态或任务变得成本高昂。这里提出了一种稀疏查询为中心的端到端自动驾驶范式(SparseAD),其中稀疏查询完全代表整个驾驶场景,包括空间、时间和任务,无需任何密集的BEV表示。具体来说,设计了一个统一的稀疏架构,用于包括检测、跟踪和在线地图绘制在内的感知任务。此外,重新审视了运动预测和规划,并设计了一个更合理的运动规划框架。在具有挑战性的nuScenes数据集上,SparseAD在端到端方法中实现了最先进的全任务性能,并显著缩小了端到端范式与单任务方法之间的性能差距。
領域背景
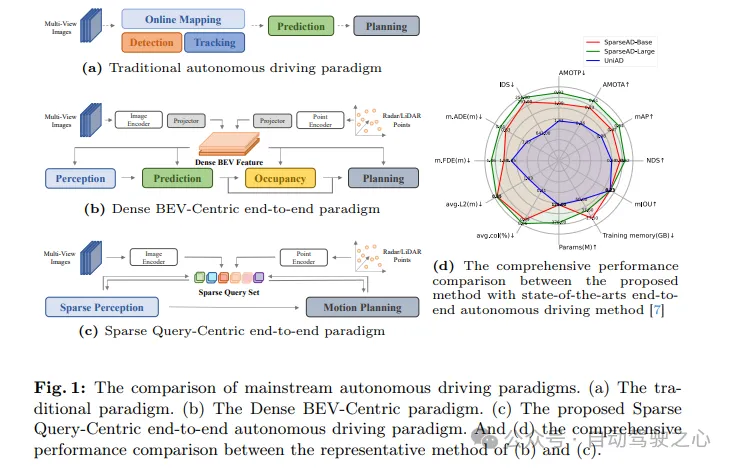
自動駕駛系統需要在複雜的駕駛場景中做出正確的決策,以確保駕駛的安全性和舒適性。通常,自動駕駛系統整合了多個任務,如偵測、追蹤、線上地圖、運動預測和規劃。如圖1a所示,傳統的模組化範式將複雜的系統拆分為多個單獨的任務,每個任務都獨立優化。在這種範式中,獨立的單任務模組之間需要手動進行後處理,這使得整個流程變得更繁瑣。另一方面,由於堆疊任務之間的場景資訊損失壓縮,整個系統的誤差會逐漸累積,這可能導致潛在的安全問題。
關於上述問題,端到端自動駕駛系統以原始感測器數據作為輸入,並以更簡潔的方式返回規劃結果。早期的工作提出跳過中間任務,直接從原始感測器資料預測規劃結果。儘管這種方法更為直接,但在模型最佳化、可解釋性和規劃性能方面並不令人滿意。另一種具有更好可解釋性的多面範式是將自動駕駛的多個部分整合到一個模組化的端到端模型中,其中引入了多維度的監督,以提高對複雜駕駛場景的理解能力,並帶來多工的能力。
如图1b所示,在大多数先前的模块化端到端方法中,整个驾驶场景通过密集的鸟瞰图(BEV)特征进行表示,这些特征包括多传感器和时间信息,并作为全栈驾驶任务(包括感知、预测和规划)的源输入。尽管密集的BEV特征在跨空间和时间的多模态和多任务中确实发挥了关键作用,将之前使用BEV表示的端到端方法总结为Dense BEV-Centric范式。然而,尽管这些方法具有简洁性和可解释性,它们在自动驾驶的每个子任务上的性能仍然远远落后于相应的单任务方法。此外,在Dense BEV-Centric范式下,长期时间融合和多模态融合主要是通过多个BEV特征图来实现的,这导致了计算成本、内存占用显著增加,给实际部署带来了更大的负担。
这里提出了一种新颖的以稀疏查询为中心的端到端自动驾驶范式(SparseAD)。在该范式中,整个驾驶场景中的空间和时间元素均由稀疏查询表示,摒弃了传统的密集鸟瞰图(BEV)特征,如图1c所示。这种稀疏表示使得端到端模型能够更高效地利用更长的历史信息,并扩展到更多模态和任务,同时显著降低了计算成本和内存占用。
具體來說,重新設計了模組化端到端架構,並將其簡化為由稀疏感知和運動規劃器組成的簡潔結構。在稀疏感知模組中,利用通用的時間解碼器[將包括檢測、追蹤和線上地圖繪製在內的感知任務統一起來。在這個過程中,多感測器特徵和歷史記憶被視為tokens,而物件查詢和地圖查詢則分別代表駕駛場景中的障礙物和道路元素。在運動規劃器中,以稀疏感知查詢作為環境表示,同時對自車和周圍代理進行多模態運動預測,以獲取自車的多種初始規劃方案。隨後,充分考慮多維度的駕駛約束,產生最終的規劃結果。
主要貢獻:
- 提出了一種新穎的以稀疏查詢為中心的端到端自動駕駛範式(SparseAD),該範式摒棄了傳統的密集鳥瞰圖(BEV)表示方法,因此具有巨大的潛力,能夠高效地擴展到更多模態和任務。
- 將模組化的端到端架構簡化為稀疏感知和運動規劃兩部分。在稀疏感知部分,以完全稀疏的方式統一了檢測、追蹤和線上地圖繪製等感知任務;而在運動規劃部分,則在更合理的框架下進行了運動預測和規劃。
- 在具有挑战性的nuScenes数据集上,SparseAD在端到端方法中取得了最先进的性能,并显著缩小了端到端范式与单任务方法之间的性能差距。这充分证明了所提出的稀疏端到端范式具有巨大的潜力。SparseAD不仅提高了自动驾驶系统的性能和效率,还为未来的研究和应用提供了新的方向和可能性。
SparseAD網路結構
如圖1c所示,在提出的以稀疏查詢為中心的範式中,不同的稀疏查詢完全代表了整個駕駛場景,不僅負責模組之間的信息傳遞和交互,還以端到端的方式在多任務中傳播反向梯度以進行最佳化。與以往以密集鳥瞰圖(BEV)為中心的方法不同,SparseAD中沒有使用任何視圖投影和密集BEV特徵,從而避免了沉重的計算和內存負擔,SparseAD的詳細架構如圖2所示。
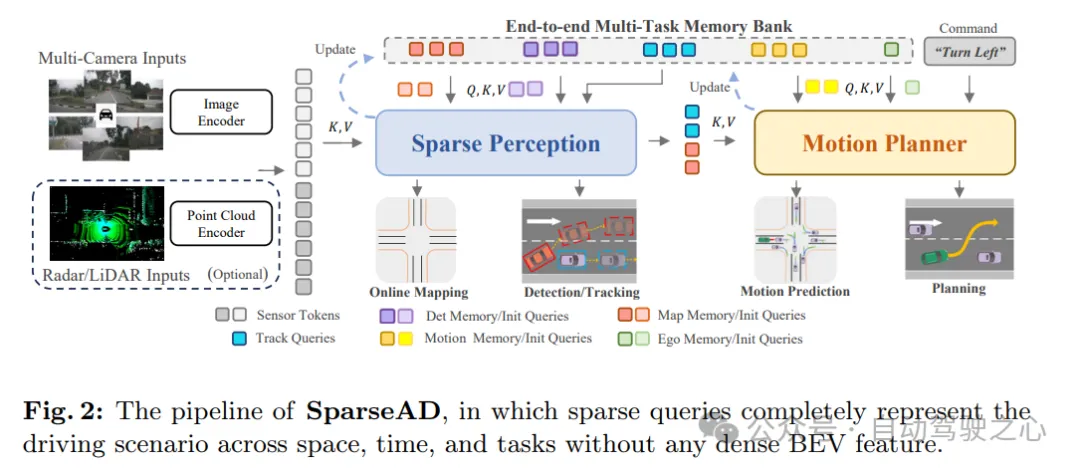
從架構示意圖來看,SparseAD主要由三個部分組成,包括感測器編碼器、稀疏感知和運動規劃器。具體來說,感測器編碼器將多視圖相機影像、雷達或光達點作為輸入,並將其編碼成高維特徵。這些特徵隨後與位置嵌入(PE)一起作為感測器tokens輸入到稀疏感知模組中。在稀疏感知模組中,來自感測器的原始資料將被聚合成多種稀疏感知查詢,如檢測查詢、追蹤查詢和地圖查詢,它們分別代表駕駛場景中的不同元素,並將進一步傳播到下游任務中。在運動規劃器中,感知查詢被視為駕駛場景的稀疏表示,並被充分利用於所有周圍agent和自車。同時,考慮了多方面的駕駛約束以產生既安全又符合動力學要求的最終規劃。
此外,架構中引入了端到端多任務記憶庫,用於統一儲存整個駕駛場景的時序訊息,這使得系統能夠受益於長時間歷史資訊的聚合,從而完成全端駕駛任務。
如圖3所示,SparseAD的稀疏感知模組以稀疏的方式統一了多個感知任務,包括檢測、追蹤和線上地圖繪製。具體來說,這裡有兩個結構完全相同的時序解碼器,它們利用來自記憶庫的長期歷史資訊。其中一個解碼器用於障礙物感知,另一個用於線上地圖繪製。
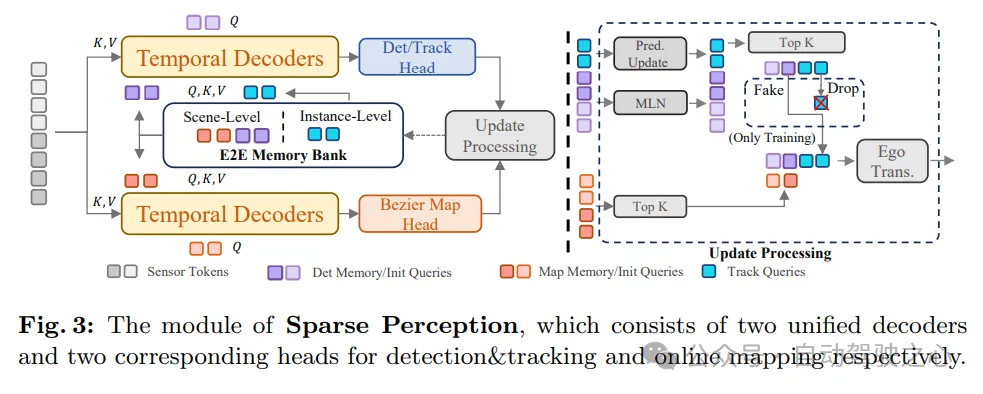
透過不同任務對應的感知查詢進行資訊聚合後,檢測和追蹤頭以及地圖部分別被用於解碼和輸出障礙物和地圖元素。之後,進行更新過程,該過程會過濾並保存當前幀的高置信度感知查詢,並相應地更新記憶庫,這將有利於下一幀的感知過程。
透過這種方式,SparseAD的稀疏感知模組實現了對駕駛場景的高效、準確的感知,為後續的運動規劃提供了重要的資訊基礎。同時,透過利用記憶庫中的歷史訊息,模組能夠進一步提高感知的準確性和穩定性,確保自動駕駛系統的可靠運作。
稀疏感知
在障碍物感知方面,在统一的解码器内采用联合检测和跟踪的方式,无需任何额外的手工后处理。检测和跟踪查询之间存在明显的不平衡,这可能导致检测性能的显著下降。为了缓解上述问题,从多个角度改进了障碍物感知的性能。首先,引入了两级记忆机制来跨帧传播时序信息。其中,场景级记忆维持没有跨帧关联的查询信息,而实例级记忆则保持跟踪障碍物相邻帧之间的对应关系。其次,考虑到两者起源和任务的不同,对场景级和实例级记忆采用了不同的更新策略。具体来说,通过MLN来更新场景级记忆,而实例级记忆则通过每个障碍物的未来预测进行更新。此外,在训练过程中,还对跟踪查询采用了增强策略,以平衡两级记忆之间的监督,从而增强检测和跟踪性能。之后,通过检测和跟踪头部,可以从检测或跟踪查询中解码出具有属性和唯一ID的3D边界框,然后进一步用于下游任务。
線上地圖建構是一個複雜而重要的任務。根據目前所了解的知識,現有的線上地圖建立方法大多依賴密集的鳥瞰視圖(BEV)特徵來表示駕駛環境。這種方法在擴展感知範圍或利用歷史資訊方面存在困難,因為需要大量的記憶體和計算資源。我們堅信所有的地圖元素都可以以稀疏的方式表示,因此,嘗試在稀疏範式下完成線上地圖建構。具體來說,採用了與障礙物感知任務中相同的時序解碼器結構。最初,帶有先驗類別的地圖查詢被初始化為在駕駛平面上均勻分佈。在時序解碼器中,地圖查詢與感測器標記和歷史記憶標記互動。這些歷史記憶標記實際上是由先前幀中高度可信的地圖查詢組成的。然後,更新後的地圖查詢攜帶了當前幀地圖元素的有效訊息,可以被推送到記憶庫中,以便在未來的幀或下游任務中使用。
顯然,線上地圖建構的流程與障礙物感知大致相同。也就是說,統一了包括檢測、追蹤和線上地圖建構在內的感知任務,採用了一種通用的稀疏方式,這種方式在擴展到更大範圍(例如100m × 100m)或長期融合時更加高效,而且不需要任何複雜的操作(如可變形注意力或多點注意力)。據我們所知,這是第一個在稀疏方式下在統一感知架構中實現線上地圖建構的。隨後,利用分段貝塞爾地圖Head來回歸每個稀疏地圖元素的分段貝塞爾控制點,這些控制點可以方便地轉換以滿足下游任務的要求。
運動規劃器
我們重新審視了自動駕駛系統中的運動預測與規劃問題,並發現許多先前的方法在預測周圍車輛運動時忽略了本車(ego-vehicle)的動態。雖然這在大多數情況下可能不會顯現出來,但在諸如交叉口等場景中,當近處車輛與本車之間交互緊密時,這可能會帶來潛在風險。受此啟發,設計了一個更合理的運動規劃架構。在這個框架中,運動預測器同時預測周圍車輛和本車的移動。隨後,本車的預測結果作為運動先驗被用於後續的規劃優化器。在規劃過程中,我們考慮了不同方面的約束,以產生既滿足安全性又符合動力學要求的最終規劃結果。
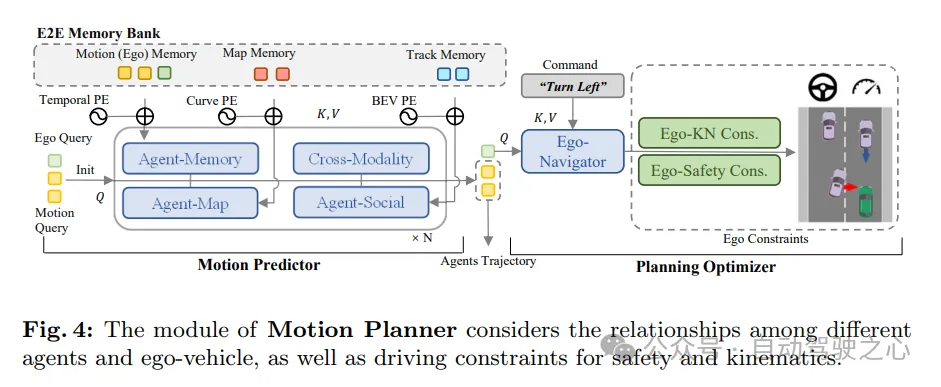
如圖4所示,SparseAD中的運動規劃器將感知查詢(包括軌跡查詢和地圖查詢)作為當前駕駛場景的稀疏表示。多模態運動查詢被用作媒介,以實現對駕駛場景的理解、對所有車輛(包括本車)之間交互的感知,以及對不同未來可能性的博弈。隨後,本車的多模態運動查詢被送入規劃優化器,其中充分考慮了包括高級指令、安全性和動力學在內的多個方面的駕駛約束。
運動預測器。遵循先前的方法,透過標準的transformer層實現了運動查詢與當前駕駛場景表示(包括軌跡查詢和地圖查詢)之間的感知和整合。此外,應用自車agent和跨模態互動來共同建模未來時空場景中周圍agent和本車之間的交互作用。透過多層堆疊結構內部和之間的模組協同作用,運動查詢能夠聚合來自靜態和動態環境的豐富語義資訊。
除了上述內容外,還引入了兩種策略來進一步提高運動預測器的性能。首先,利用軌跡查詢的實例層級時間記憶進行簡單直接的預測,並將其作為周圍agent運動查詢初始化的一部分。透過這種方式,運動預測器能夠從上游任務中獲得的先驗知識中受益。其次,由於端到端記憶庫,能夠以幾乎可忽略的成本、以流式方式透過代理記憶聚合器從保存的歷史運動查詢中同化有用資訊。
要注意的是,本車的多模態運動查詢是同時更新的。透過這種方式,可以獲得本車的運動先驗,這可以進一步促進規劃的學習過程。
規劃優化器。借助運動預測器提供的運動先驗,獲得了更好的初始化,從而在訓練過程中減少了繞行。作為運動規劃器的關鍵組成部分,成本函數的設計至關重要,因為它將極大地影響甚至決定最終性能的品質。在所提出的SparseAD運動規劃器中,主要考慮安全和動力學兩大方面的約束,旨在產生令人滿意的規劃結果。具體來說,除了VAD中確定的約束外,還重點關注本車與附近agent之間的動態安全關係,並考慮它們在未來時刻的相對位置。例如,如果agent i相對於本車持續保持在前方左側區域,從而阻止本車向左變換車道,那麼agent i將獲得一個左標籤,表示agent i對本車施加了向左的約束。因此,約束在縱向方向上分為前、後或無,在橫向方向上分為左、右或無。在規劃器中,我們從對應的查詢中解碼其他agent與本車在橫向和縱向方向上的關係。這個過程涉及確定這些方向上其他代理與本車之間所有約束關係的機率。然後,我們利用focal loss作為Ego-Agent關係(EAR)的成本函數,有效地捕捉附近agent帶來的潛在風險:
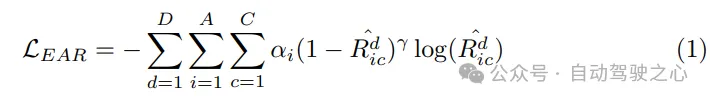
由於規劃軌跡必須遵循控制系統執行的動力學規律,因此在運動規劃器中嵌入了輔助任務,以促進本車動力學狀態的學習。從本車查詢Qego中解碼速度、加速度和偏航角等狀態,並使用動力學損失對這些狀態進行監督:
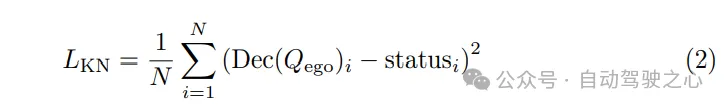
實驗結果
在nuScenes資料集上進行了大量實驗,以證明該方法的有效性和優越性。公正地說,將對每個完整任務的表現進行評估,並與先前的方法進行比較。本節實驗使用了SparseAD的三種不同配置,分別是僅使用影像輸入的SparseAD-B和SparseAD-L,以及使用雷達點雲和影像多模態輸入的SparseAD-BR。 SparseAD-B和SparseAD-BR都使用V2-99作為影像骨幹網絡,輸入影像解析度為1600 × 640。 SparseAD-L則進一步利用ViTLarge作為影像骨幹網絡,輸入影像解析度為1600×800。
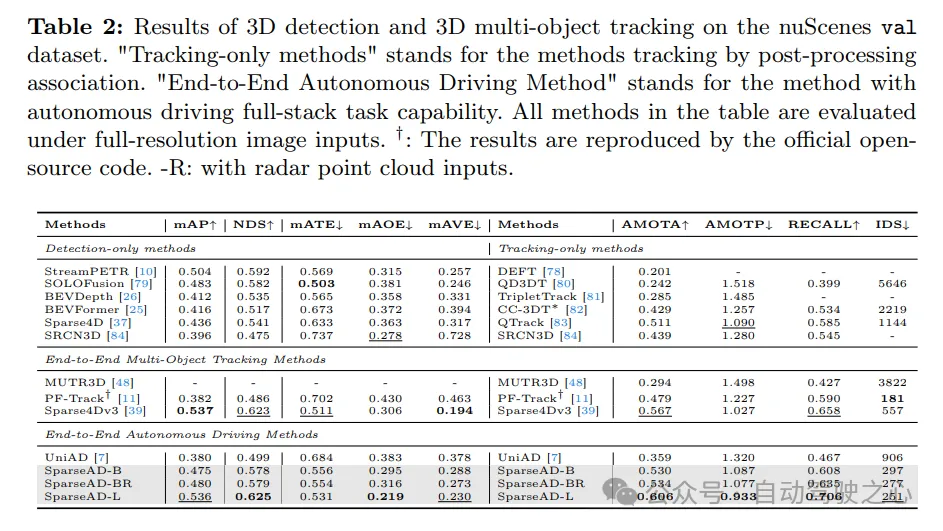
在nuScenes驗證資料集上的3D偵測和3D多目標追蹤結果如下。 「僅追蹤方法」指的是透過後製關聯進行追蹤的方法。 「端到端自動駕駛方法」指的是具備自動駕駛全端任務能力的方法。表中的所有方法都是在全解析度影像輸入下進行評估的。 †:結果是透過官方開源程式碼復現的。 -R:表示使用了雷達點雲輸入。
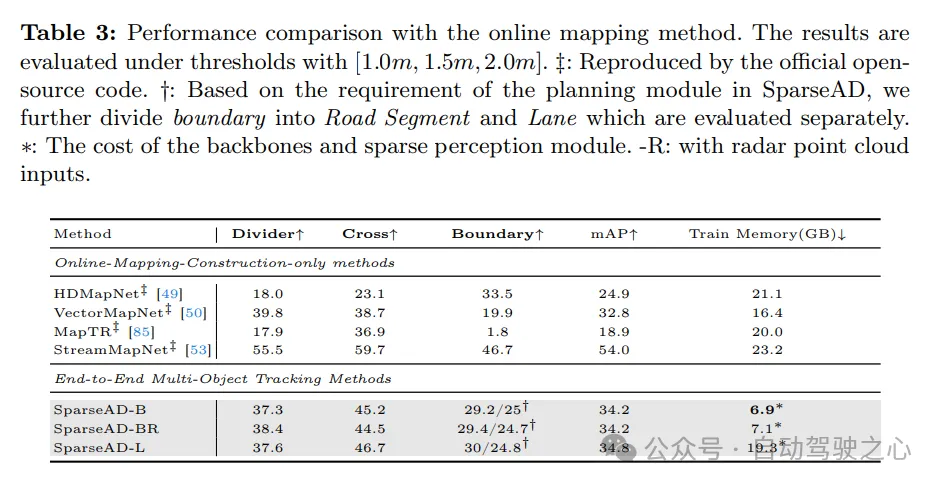
與在線建圖方法的效能比較如下,結果是在[1.0m, 1.5m, 2.0m]的閾值下進行評估的。 ‡:透過官方開源程式碼復現的結果。 †:根據SparseAD中規劃模組的需求,我們進一步將邊界細分為路段和車道,並分別進行評估。 ∗:骨幹網路和稀疏感知模組的成本。 -R:表示使用了雷達點雲輸入。
Multi-Task結果
障礙感知。在Tab. 2中將SparseAD的檢測和追蹤性能與nuScenes驗證集上的其他方法進行了比較。顯然,SparseAD-B在大多數流行的僅檢測、僅追蹤和端到端多目標追蹤方法中表現出色,同時與SOTA方法如StreamPETR、QTrack在相應任務上的表現相當。透過採用更先進的骨幹網路進行擴展,SparseAD-Large實現了整體更好的性能,其mAP為53.6%,NDS為62.5%,AMOTA為60.6%,整體上優於之前的最佳方法Sparse4Dv3。
在线建图。在Tab. 3中展示了SparseAD与其他先前方法在nuScenes验证集上的在线建图性能比较结果。需要指出的是,根据规划的需求,我们将边界细分为路段和车道,并分别进行评估,同时将范围从通常的60m × 30m扩展到102.4m × 102.4m,以与障碍感知保持一致。在不失公平性的前提下,SparseAD以稀疏的端到端方式实现了34.2%的mAP,无需任何密集的BEV表示,这优于大多数之前流行的方法,如HDMapNet、VectorMapNet和MapTR,在性能和训练成本方面都具有明显优势。尽管性能略逊于StreamMapNet,但我们的方法证明了在线建图可以在统一的稀疏方式下完成,无需任何密集的BEV表示,这对于以显著较低成本实现端到端自动驾驶的实际部署具有重要意义。诚然,如何有效利用其他模态(如雷达)的有用信息仍是一个值得进一步探索的任务。我们相信在稀疏方式下仍有很大的探索空间。
运动预测。在Tab. 4a中展示了运动预测的比较结果,其中指标与VIP3D保持一致。SparseAD在所有端到端方法中实现了最佳性能,具有最低的0.83m minADE、1.58m minFDE、18.7%的遗漏率以及最高的0.308 EPA,优势巨大。此外,得益于稀疏查询中心范式的效率和可扩展性,SparseAD可以有效地扩展到更多模态,并从先进的骨干网络中受益,从而进一步显著提高预测性能。
規劃。規劃的結果呈現在Tab. 4b。由於上游感知模組和運動規劃器的卓越設計,SparseAD的所有版本在nuScenes驗證資料集上都達到了最先進水準。具體來說,與包括UniAD和VAD在內的所有其他方法相比,SparseAD-B實現了最低的平均L2誤差和碰撞率,這證明了我們的方法和架構的優越性。與上游任務(包括障礙感知和運動預測)類似,SparseAD透過雷達或更強大的骨幹網路進一步提升了效能。