Breakthrough million-level video and language world model: Large World Model~
2024.03.26

A recent breakthrough study has attracted widespread attention in exploring how to make AI better understand the world. A research team from the University of California, Berkeley, released the "Large World Model, LWM", which can simultaneously process millions of video and language sequences, achieving in-depth understanding of complex scenes. This research undoubtedly opens a new chapter for the future development of AI.
Paper address: World Model on Million-Length Video And Language With RingAttention

Blog address: Large World Models
huggingface: LargeWorldModel (Large World Model)
In traditional methods, AI models can often only handle short text or video clips and lack the ability to understand long-term complex scenes. However, many real-world scenarios, such as long-form books, movies, or TV series, contain rich information and require longer context for in-depth understanding. To address this challenge, the LWM team adopted RingAttention technology and successfully expanded the model's context window to enable it to handle sequences up to 1 million tokens (1M tokens). For example, to implement a Q&A video of more than 1 hour:

Figure 1. Long video understanding. LWM can answer questions about YouTube videos longer than 1 hour.
Fact retrieval over 1M contexts:
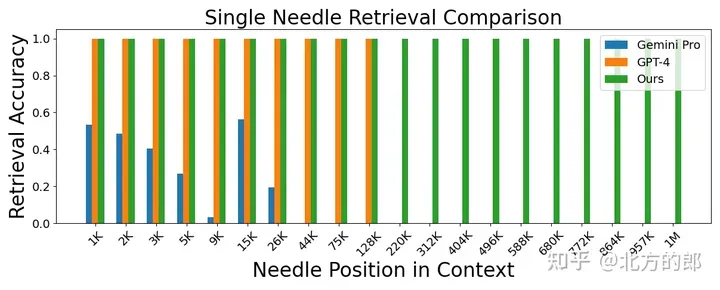
Figure 2. Needle retrieval task. LWM achieves high accuracy within a 1M context window and outperforms GPT-4V and Gemini Pro.
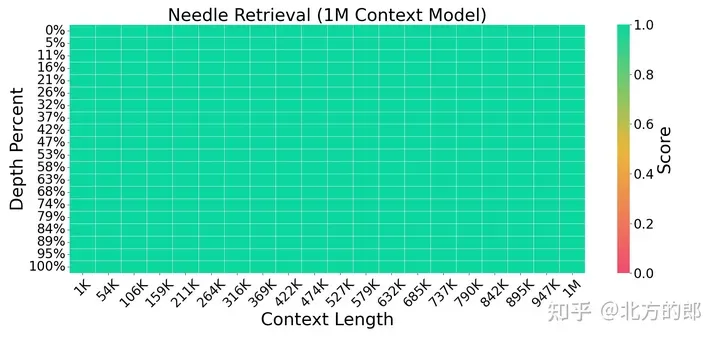
Figure 3. Needle retrieval task. LWM achieves high accuracy for different context sizes and positions within the context window.
Technical realization
To train and evaluate LWM, the researchers first collected a large dataset containing various videos and books. Then, they gradually increased the context length of training, starting from 4K tokens and gradually expanding to 1M tokens. This process not only effectively reduces training costs, but also enables the model to gradually adapt to the learning of longer sequences. During the training process, the researchers also found that mixing image, video, and text data of varying lengths was critical to the model's multimodal understanding. Specifically include:
Model training occurs in two stages: first, the context size is expanded by training a large language model. Then conduct joint training of video and language.
Stage I: Learning Long-Context Language Models
Extended context: Using RingAttention technology, the context length can be extended to millions of tokens without approximation. At the same time, the computational cost is reduced by gradually increasing the training sequence length, starting from 32K tokens and gradually increasing to 1M tokens. Furthermore, to extend the positional encoding to accommodate longer sequences, the simple approach of increasing θ in RoPE as the context window size increases is adopted.
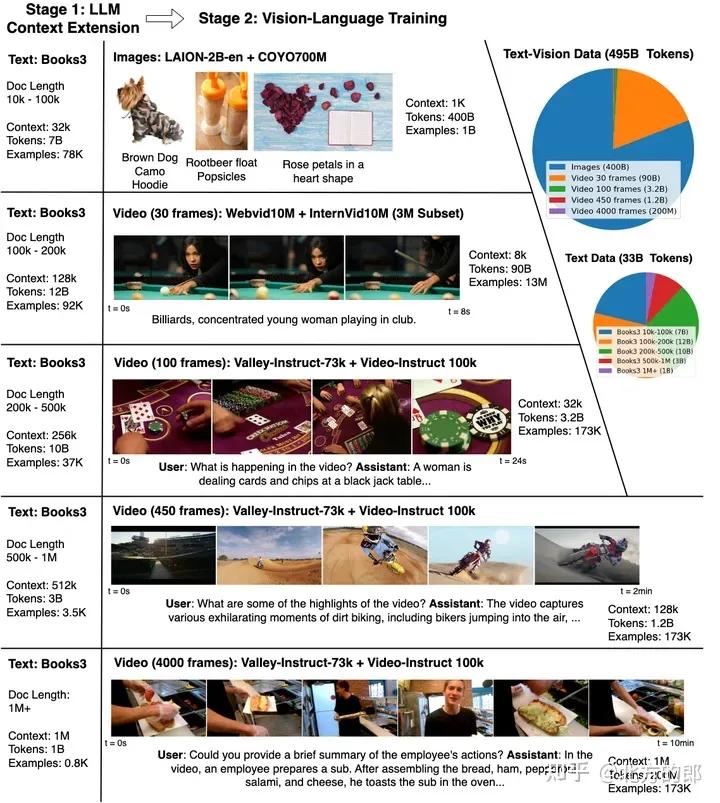
Context expansion and visual language training. Use RingAttention to scale the context size on books from 4K to 1M, and then perform visual language training on multiple forms of visual content ranging from 32K to 1M in length. The lower panel shows interactive capabilities for understanding and responding to queries about a complex multimodal world.
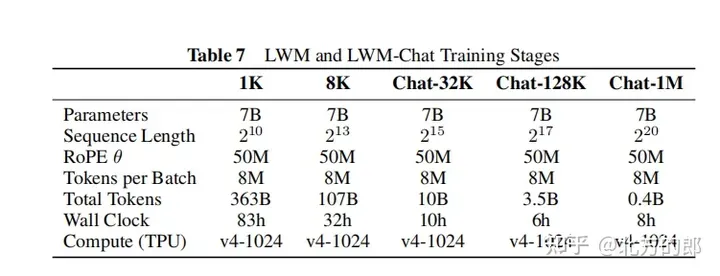
Training steps: First initialize from LLaMA-2 7B model, then gradually increase the context length in 5 stages, which are 32K, 128K, 256K, 512K and 1M tokens. Each stage is trained using different filtered versions of the Books3 dataset. As the context length increases, the model is able to handle more tokens.
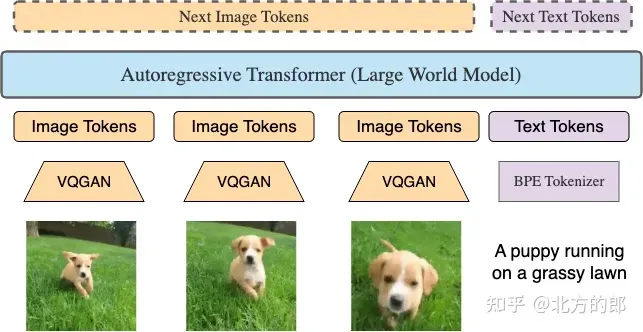
Predict any long sequence. RingAttention is capable of training across multiple formats including video-text, text-video, image-text, text-image, video-only, image-only, and text-only, using very large context windows. See the LWM paper for key features, including masked sequence packing and loss weighting, that enable efficient video language training.
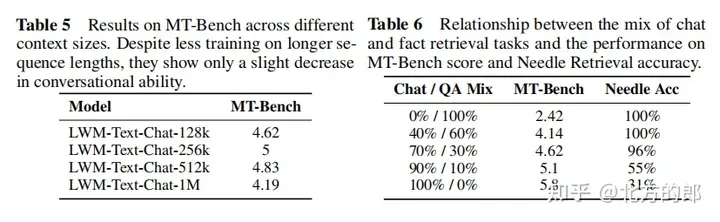
Dialogue fine-tuning: In order to learn the dialogue ability of long context, a simple question and answer data set was constructed. The documents of the Books3 data set were divided into blocks of 1000 tokens, and then a short context language model was used to generate a question and answer pair for each block. Finally, Adjacent blocks are concatenated to construct a long context question and answer example. In the fine-tuning phase, the model is trained on UltraChat and custom question and answer datasets with a ratio of 7:3.
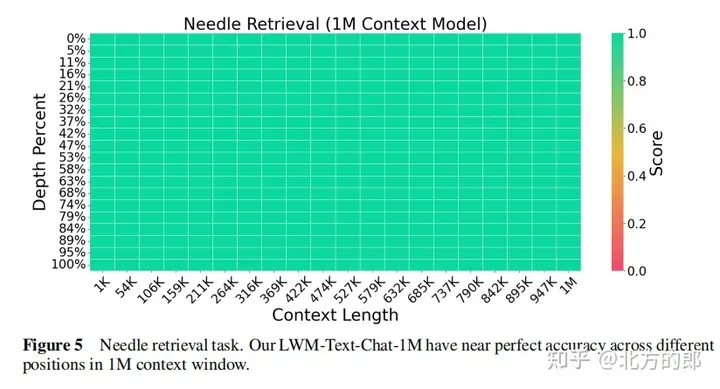
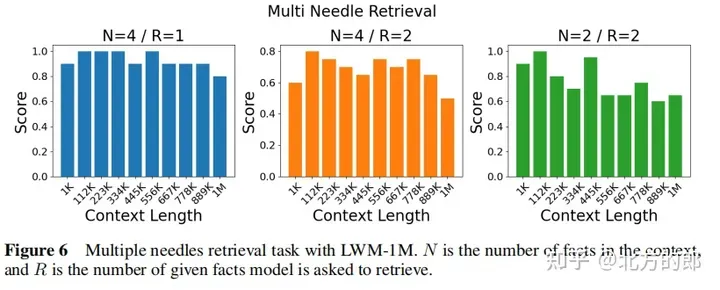
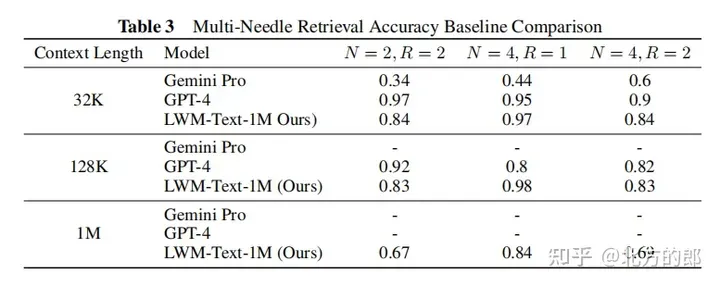
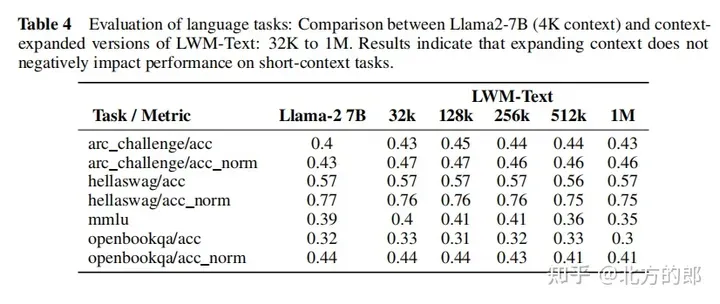
Language evaluation results: In the single-needle retrieval task, the model with 1M context can retrieve numbers randomly assigned to random cities almost perfectly across the entire context. In the multi-needle retrieval task, the model performed well when retrieving one needle, and the performance dropped slightly when retrieving multiple needles. Expanding context length did not decrease performance when assessed on a short-context language task. In conversational evaluation, increasing conversational interaction capabilities may reduce the accuracy with which the system can retrieve specific information, or "pins."
Stage II: Learning Long-Context Vision-Language Models
Architecture modification: Based on the first stage, LWM and LWM-Chat are modified to enable them to accept visual input. Specifically, pre-trained VQGAN is used to convert the 256x256 input image into a 16x16 discrete token, the video is VQGAN encoded frame by frame and the encodings are connected. In addition, special marker symbols and are introduced to distinguish text and visual tokens, as well as and to mark the end of images and video frames.

Training steps: Initialize from the LWM-Text-1M model, using a similar training method of gradually increasing the sequence length as in the first stage, first training on 1K tokens, then 8K tokens, and finally 32K, 128K and 1M tokens. The training data includes text-image pairs, text-video pairs, and chat data for downstream tasks such as text-image generation, image understanding, text-video generation, and video understanding. During the training process, the mixing ratio of downstream tasks is gradually increased.
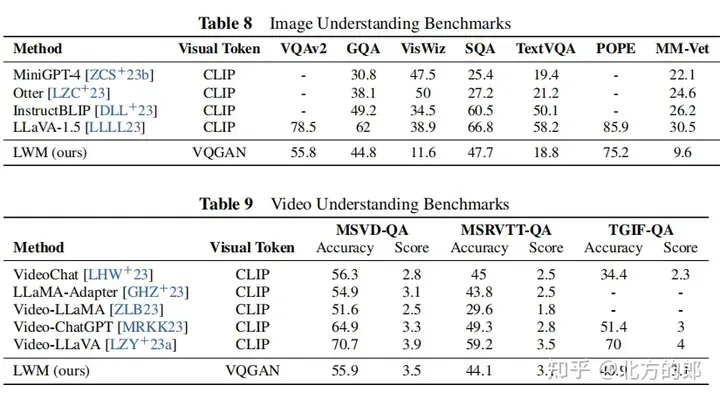
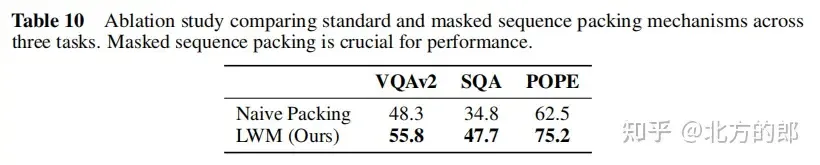
Visual-language evaluation results: In terms of long video understanding, the model can process YouTube videos up to 1 hour long and answer questions accurately, which has obvious advantages over existing models. In terms of image understanding and short video understanding, the model performance is average, but there is potential for improvement through more rigorous training and better word segmenters. In terms of image and video generation, models can generate images and videos from text. Ablation research shows that masked sequence padding is critical for downstream tasks such as image understanding.


Text to image. LWM generates images based on textual cues in an autoregressive manner.
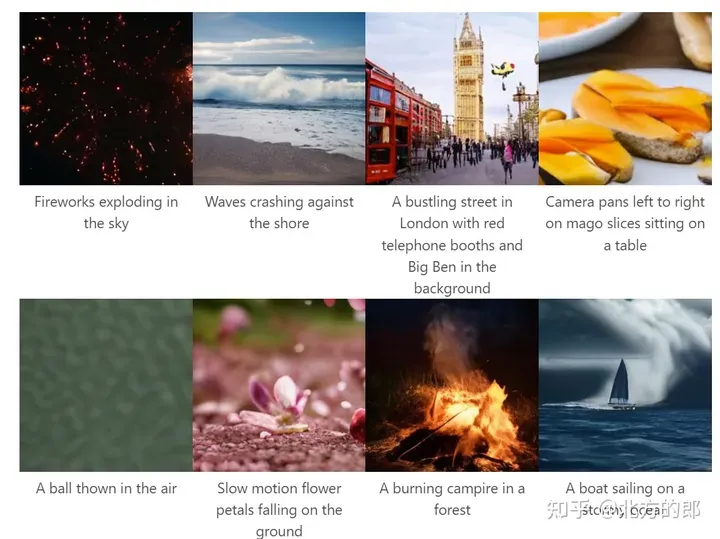
Text to video. LWM generates videos based on textual cues in an autoregressive manner.
The second stage successfully extended the language model of the first stage to include visual understanding capabilities by gradually increasing the sequence length and training on large amounts of text-image and text-video data. The model at this stage can handle multi-modal sequences up to 1M tokens, and shows strong capabilities in long video understanding, image understanding and generation.
Further Details
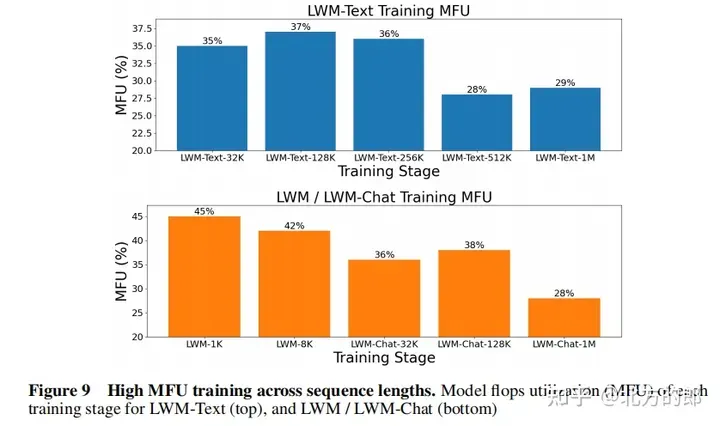
Training computing resources: The model is trained using TPUv4-1024, which is equivalent to 450 A100 GPUs, uses FSDP for data parallelism, and supports large contexts through RingAttention.
Training loss curves: Figures 10 and 11 show the training loss curves of the first-stage language model and the second-stage visual-language model. It can be seen that the loss continues to decrease as training proceeds.
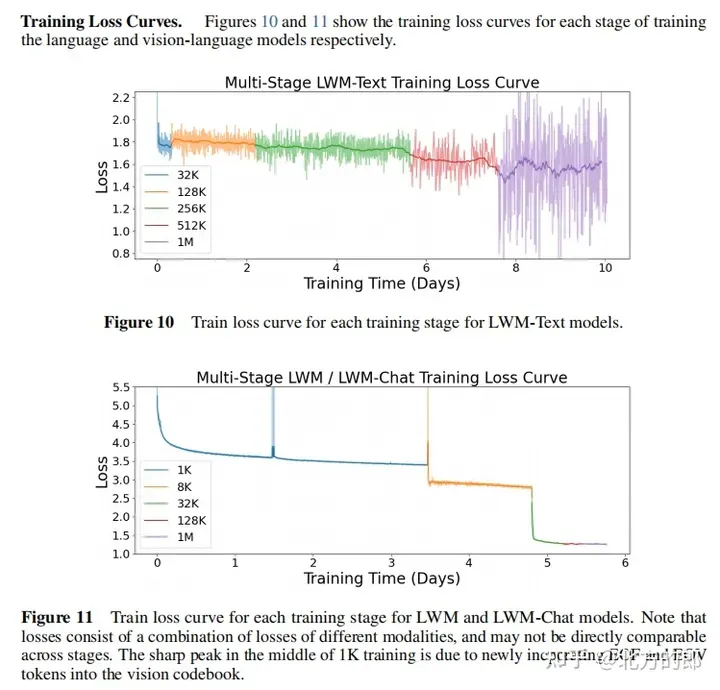
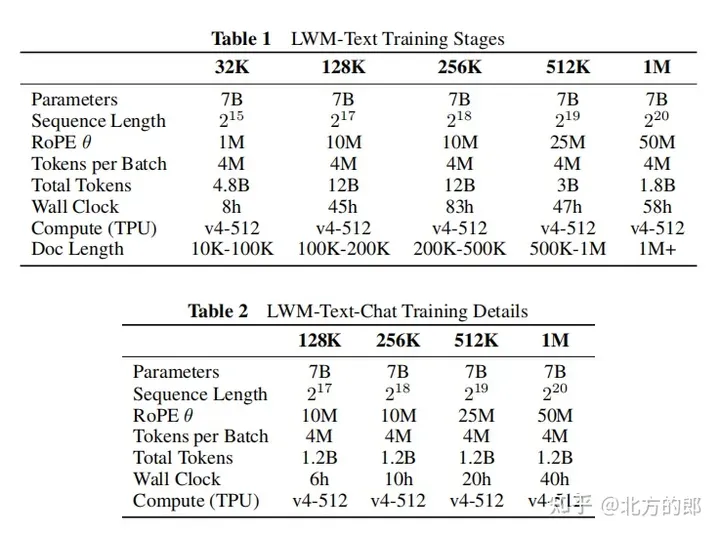
Training hyperparameters: Appendix F provides detailed training hyperparameters, including parameter amount, initialization model, sequence length, RoPE parameters, number of tokens in each batch, total number of tokens, number of training steps, learning rate plan, and number of learning rate warm-up steps. , maximum learning rate and minimum learning rate, computing resources, etc.
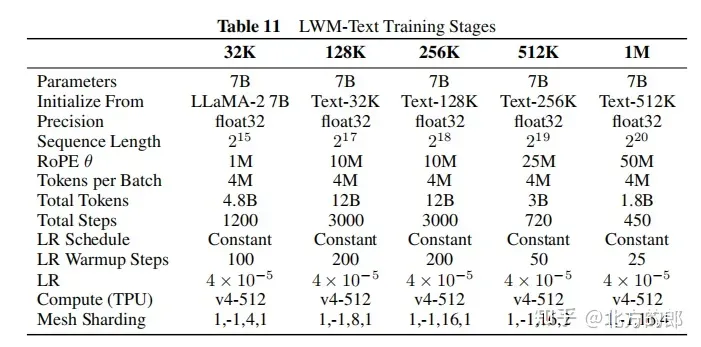
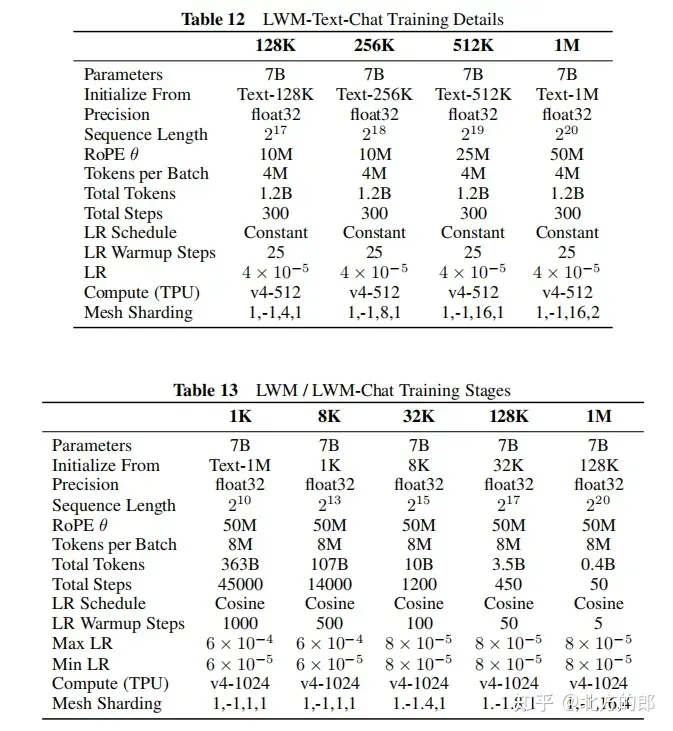
Inference extension: Implemented RingAttention for decoding, supporting inference of sequences up to millions of tokens, requiring the use of at least v4-128 TPU, and 32-way tensor parallelism and 4-way sequence parallelism.

Quantization: The documentation states that the model uses single precision for inference, and scalability can be further improved through techniques such as quantization.
some examples
Image-based dialogue.

Figure 6. Image understanding. LWM can answer questions about images.
Over 1 hour of video chat on YouTube.

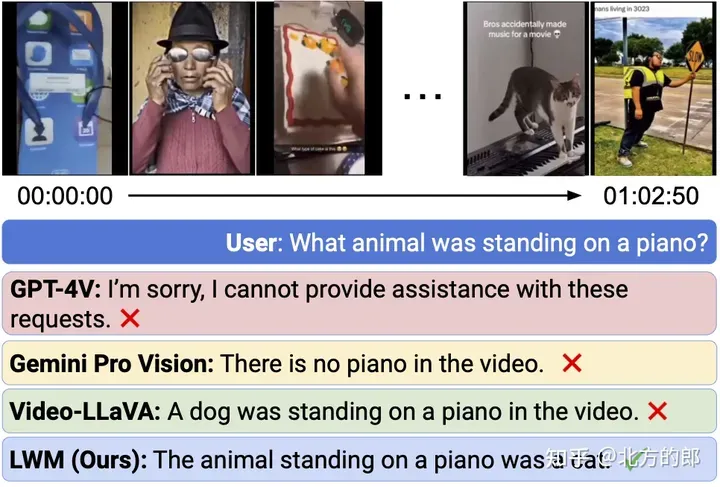
Figure 7. Long video chat.
Even when state-of-the-art commercial models GPT-4V and Gemini Pro failed, LWM was still able to answer questions about a 1-hour long YouTube video. The relevant clips for each example are at timestamps 9:56 (top) and 6:49 (bottom).