Stable Video 3D震撼登場:單圖生成無死角3D影片、模型權重開放
2024.03.20

Stability AI 的大模型家族來了一位新成員。
昨日,Stability AI 繼推出文生圖Stable Diffusion、文生影片Stable Video Diffusion 之後,又為社群帶來了3D 影片產生大模型「Stable Video 3D」(簡稱SV3D)。
该模型基于 Stable Video Diffusion 打造,能够显著提升 3D 生成的质量和多视角一致性,效果要优于之前 Stability AI 推出的 Stable Zero123 以及丰田研究院和哥伦比亚大学联合开源的 Zero123-XL。
目前,Stable Video 3D 既支援商用,需要加入Stability AI 會員(Membership);也支援非商用,使用者在Hugging Face 上下載模型權重即可。

Stability AI 提供了兩個模型變體,分別是SV3D_u 和SV3D_p。其中SV3D_u 基於單一影像輸入生成軌道視頻,不需要相機調整;SV3D_p 透過適配單一影像和軌道視角擴展了生成能力,允許沿著指定的相機路徑創建3D 視訊。
目前,Stable Video 3D 的研究論文已經放出,核心作者有三位。

- 論文網址:https://stability.ai/s/SV3D_report.pdf
- 部落格網址:https://stability.ai/news/introducing-stable-video-3d
- Huggingface 地址:https://huggingface.co/stabilityai/sv3d
技術概覽
Stable Video 3D 在3D 生成領域實現重大進步,尤其是在新穎視圖生成(novel view synthesis,NVS)方面。
過去的方法通常傾向於解決有限視角和輸入不一致的問題,而Stable Video 3D 能夠從任何給定角度提供連貫視圖,並且能夠很好地泛化。因此,此模型不僅增加了姿勢可控性,還能確保多個視圖中物件外觀的一致性,進一步改善了影響真實和準確3D 產生的關鍵問題。
如下圖所示,與Stable Zero123、Zero-XL 相比,Stable Video 3D 能夠產生細節更強、更忠實於輸入影像和多視角更一致的新穎多視圖。

此外,Stable Video 3D 利用其多視角一致性來優化3D 神經輻射場(Neural Radiance Fields,NeRF),以提高直接從新視圖產生3D 網格的品質。
為此,Stability AI 設計了掩碼分數蒸餾採樣損失,進一步增強了預測視圖中未見過區域的3D 品質。同時為了減輕烘焙照明問題,Stable Video 3D 採用了與3D 形狀和紋理共同優化的解耦照明模型。
下圖為使用Stable Video 3D 模型及其輸出時,透過3D 最佳化改進後的3D 網格產生範例。

下圖為使用Stable Video 3D 產生的3D 網格結果與EscherNet、Stable Zero123 的生成結果比較。

架構細節
Stable Video 3D 模型的架構如下圖2 所示,它是基於Stable Video Diffusion 架構建構而成,包含一個具有多個層的UNet,其中每一層又包含一個帶有Conv3D 層的殘差塊序列,以及兩個帶有註意力圖層(空間和時間)的transformer 區塊。
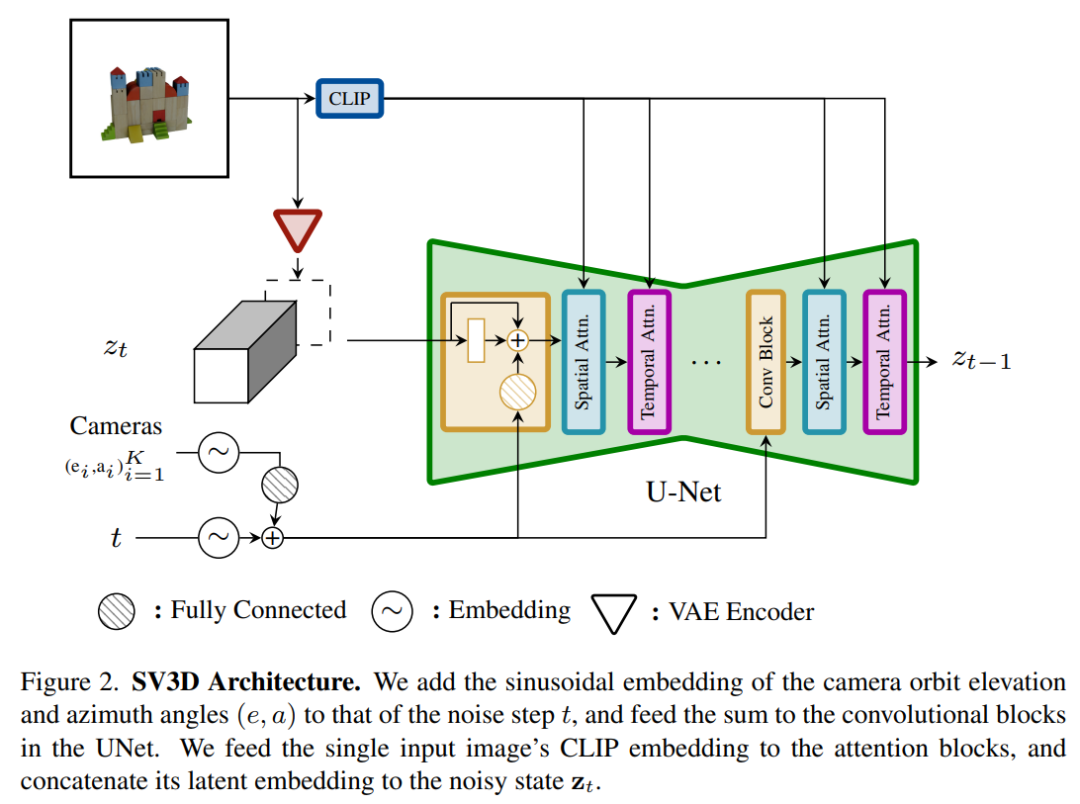
具體流程如下圖所示:
(i) 刪除「fps id」和「motion bucket id」的向量條件, 原因是它們與Stable Video 3D 無關;
(ii) 條件影像透過Stable Video Diffusion 的VAE 編碼器嵌入到潛在空間,然後在通往UNet 的雜訊時間步t 處連接到雜訊潛在狀態輸入zt;
(iii) 條件影像的CLIPembedding 矩陣被提供給每個transformer 區塊的交叉注意力層來充當鍵和值,而查詢成為對應層的特徵;
(iv) 相機軌跡沿著擴散噪音時間步被饋入到殘差塊中。相機姿勢角度ei 和ai 以及噪聲時間步t 首先被嵌入到正弦位置嵌入中,然後將相機姿勢嵌入連接在一起進行線性變換並添加到噪聲時間步嵌入中,最後被饋入到每個殘差塊並被加入到該區塊的輸入特徵中。
此外,Stability AI 設計了靜態軌道和動態軌道來研究相機姿勢調整的影響,具體如下圖3 所示。
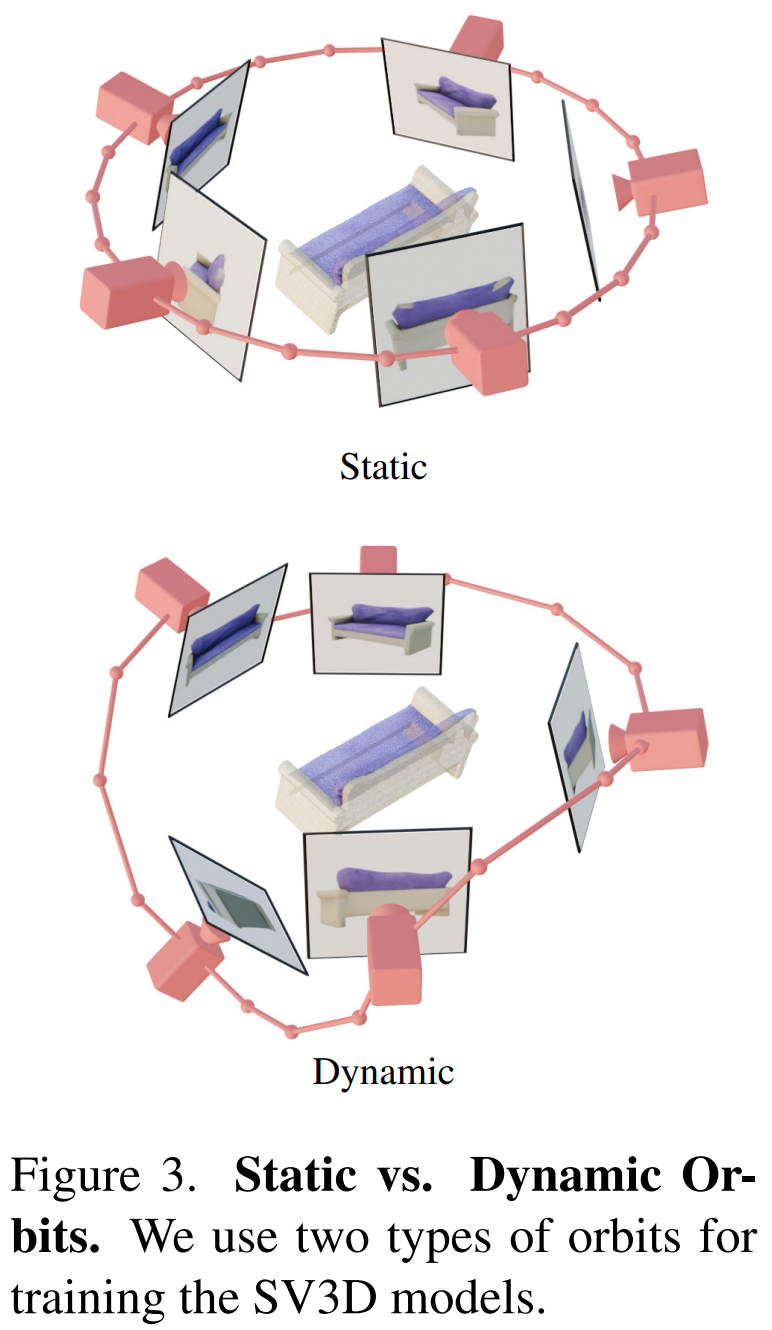
在靜態軌道上,相機採用與條件影像相同的仰角,以等距方位角圍繞物件旋轉。這樣做的缺點是基於調整的仰角,可能無法獲得關於物件頂部或底部的任何資訊。而在動態軌道上,方位角可以不等距,每個視圖的仰角也可以不同。
為了建立動態軌道,Stability AI 對靜態軌道採樣,向方位角添加小的隨機噪聲,並向其仰角添加不同頻率的正弦曲線的隨機加權組合。這樣做提供了時間平滑性,並確保相機軌跡沿著與條件影像相同的方位角和仰角循環結束。
實驗結果
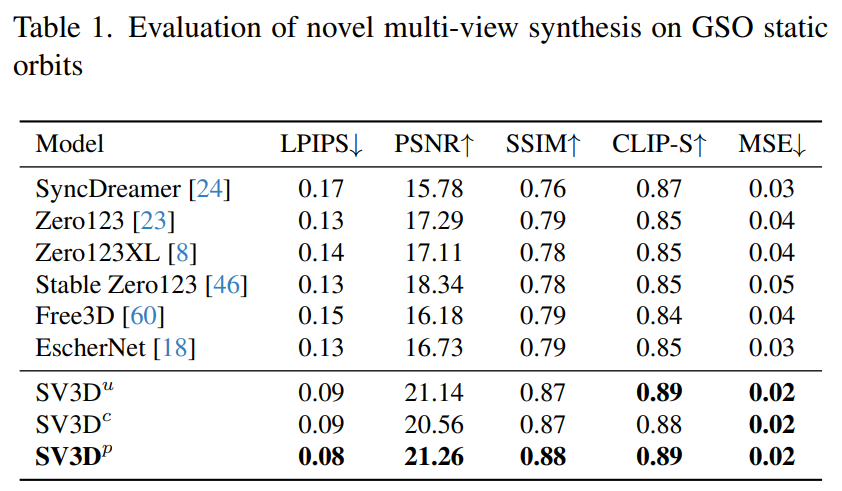
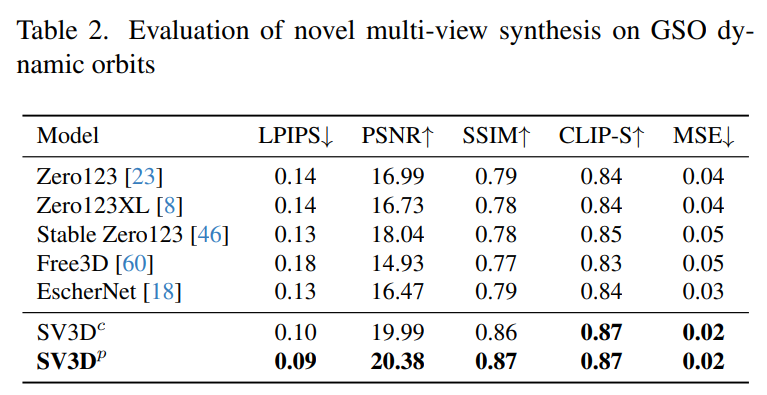
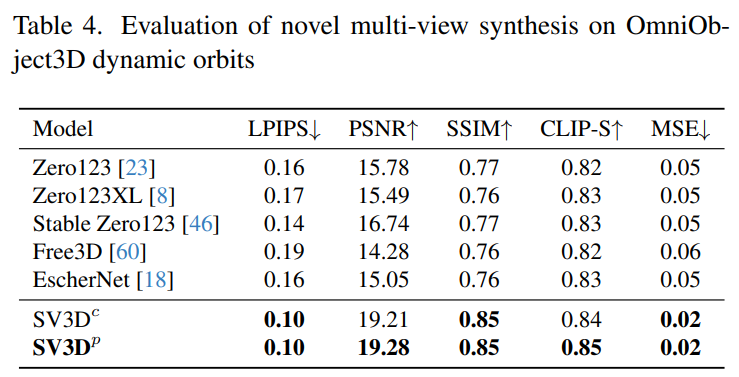
Stability AI 在未見過的GSO 和OmniObject3D 資料集上,評估了靜態和動態軌道上的Stable Video 3D 合成多視圖效果。結果如下表1 至表4 所示,Stable Video 3D 在新穎多視圖合成方面實現了SOTA 效果。
表1 和表3 顯示了Stable Video 3D 與其他模型在靜態軌道的結果,顯示了即使是無姿勢調整的模型SV3D_u,也比所有先前的方法表現得更好。
消融分析結果表明,SV3D_c 和SV3D_p 在靜態軌道的生成方面優於SV3D_u,儘管後者專門在靜態軌道上進行了訓練。
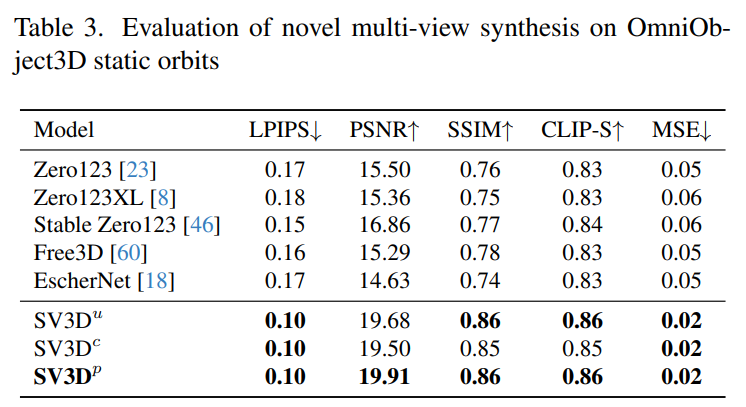
下表2 和表4 展示了動態軌道的產生結果,包括姿勢調整模型SV3D_c 和SV3D_p,後者在所有指標上實現了SOTA。
下圖6 的視覺比較結果進一步表明,與以往工作相比,Stable Video 3D 產生的影像細節更強、更忠實於條件影像、多視角更加一致。

更多技術細節和實驗結果請參閱原論文。