Sora竟是用這些資料訓練的?OpenAI CTO坦白惹眾怒
2024.03.17

OpenAI 的Sora 在今年2 月橫空出世,把文生影片帶向了新階段。它能夠根據文字提示產生超現實場景。Sora 的可適用人群受限,但在各媒體平台上,Sora 的身影無所不在,大家都在期待著使用它。
在前幾天的訪談中,三位作者透露出Sora 的更多細節,包括它處理手部時仍然存在困難,但正在優化。他們也對Sora 更多的最佳化方向進行了闡述,要讓使用者對影片畫面有更精準的控制。不過,短期內,Sora 並不會對公眾公開。畢竟Sora 能夠產生與現實十分接近的視頻,這會引發很多問題。而也因為如此,它還需要更多的改進,人們也需要更多時間來適應。
不過不用氣餒,這個短期可能不會太久。OpenAI 技術長Mira Murati 接受了華爾街日報科技專欄作家Joanna Stern 的採訪。她在談到Sora 何時推出時,透露道Sora 將於今年推出,大家可能要等幾個月,一切都取決於紅隊的進展。
OpenAI 也計畫在Sora 中加入音訊生成的功能,讓影片產生效果更逼真。接下來,他們也會繼續優化Sora,包括幀與幀之間連貫性、產品的易用性以及成本。OpenAI 也希望加入用戶編輯Sora 生成影片的功能。畢竟AI 工具的成果並不是百分之百準確。如果用戶能夠在Sora 的基礎上進行再創作,想必會有更好的影片效果和更準確的內容表達。
當然,科技解讀上的深入淺出只是訪談的一部分,另一部分則始終圍繞著安全、擔憂這樣的大眾議題。例如,一段20 秒的720p 視頻,不需要幾個小時的生成時間,只要幾分鐘,Sora 在安全方面又將採取怎樣的舉措?
在訪談中,主持人也刻意將主題引到Sora 訓練資料上,Mira Murati 表示,Sora 接受過公開可用和授權資料的訓練。當記者追問是否用到了YouTube 上的影片時,Mira Murati 表示自己不是很確定。記者又追問是否用到了Facebook 或Instagram 上的影片?Mira Murati 回答如果它們是公開可用的,可能會成為資料地一部分,但我不確定,我不敢打包票。
此外她也承認Shutterstock(是美國圖片庫、圖片素材、圖片音樂和編輯工具供應商) 是訓練資料的來源之一,也強調了他們的合作關係。
不過看似一場普通的採訪,但也引來了眾多爭議,很多人指責Mira Murati 不夠坦誠:

還有人從微表情推測Murati 在說謊,表示道「記得不要讓自己看起來像是在說謊。」
「我只是好奇,作為OpenAI 的CTO 居然不知道使用了什麼樣的訓練數據。這不是在明目張膽的撒謊嗎?」
「作為這樣一家公司的首席技術官,她怎麼能不準備好回答這麼基本的問題呢?讓人摸不著頭腦...」
還有人認為Murati 並沒有說謊,也許Facebook(FB)真的允許OpenAI 使用部分數據。
但這種說法立刻遭到反駁「Facebook 是瘋了嗎?這些數據對Facebook 來說絕對是無價的。為什麼他們要把數據賣給或授權給他們最大的競爭對手,這實際上是他們在GenAI競賽中唯一的競爭優勢。」
顯然,許多人認為Murati 沒有說實話:「身為OpenAI 的首席技術官,當被問及Sora 是否接受過YouTube 影片的訓練時,她卻表示自己不確定,並拒絕討論有關訓練數據的進一步問題。要么是她對自己的產品相當無知,要么是在說謊—— 無論哪種方式都非常可惡。」
這就不得不將話題引入另一個層面:版權問題。一直以來,OpenAI 深受數據版權的困擾,前段時間,《紐約時報》一紙訴狀將OpenAI 告到法庭,起訴書中《紐約時報》列出了GPT-4 輸出“抄襲”《紐約時報》的“證據」,GPT-4 的許多回答與《紐約時報》的報道段落幾乎完全一致。
數據監管問題該如何解決?史丹佛教授曼寧表示「目前最簡單但最有用和最合適的AI 監管之一是要求模型提供者記錄他們使用的訓練數據。歐洲議會剛剛通過並批准的《人工智慧法案》也強調了這一點。 」
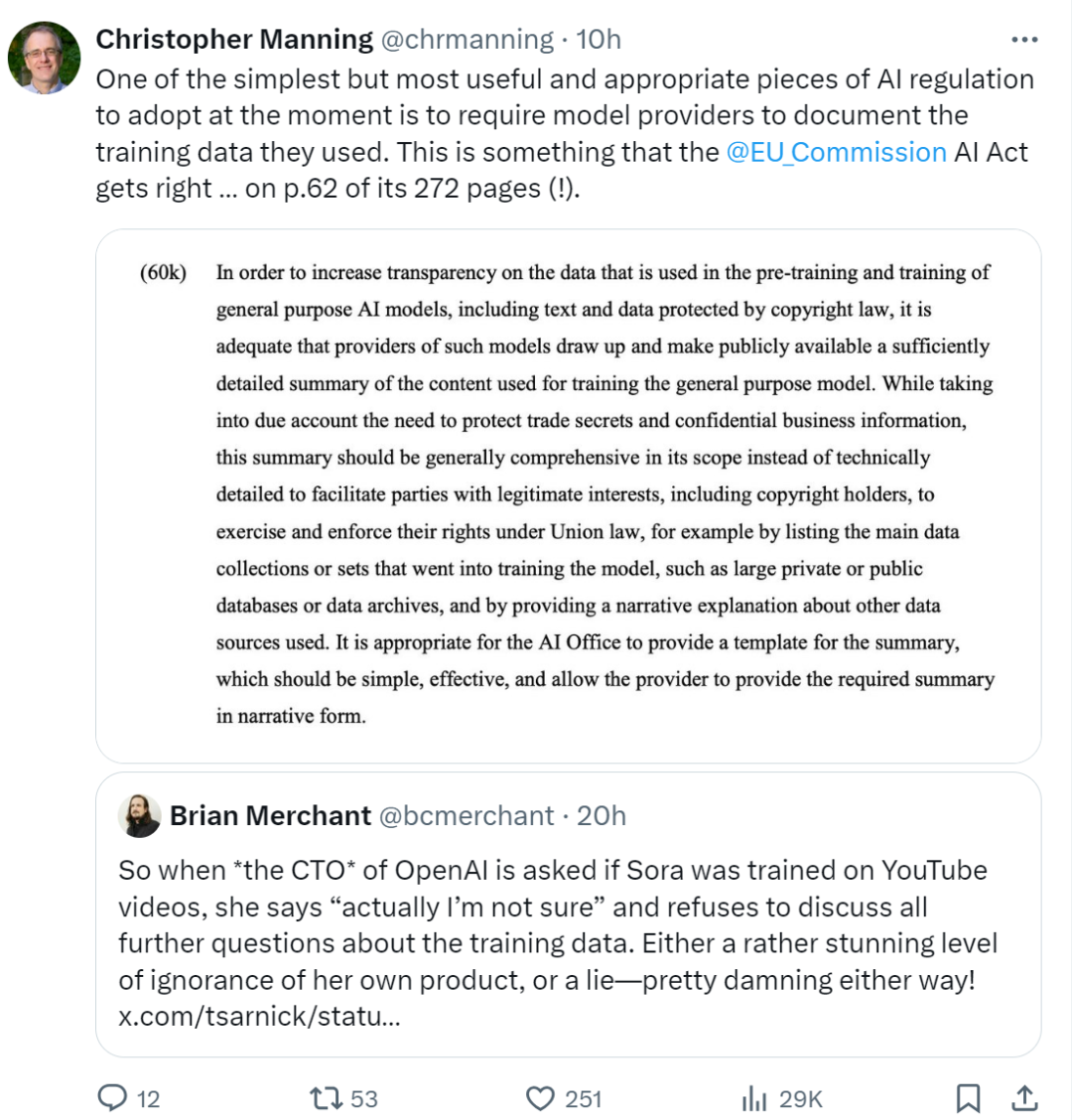
圖源:https://twitter.com/chrmanning/status/1768311283445796946
OpenAI 到底使用了什麼資料來訓練Sora,現在看來,這座巨大的冰山已經露出了一角。這次訪談除了大家關心的數據問題,還有更多資訊值得大家一看。
以下是這次訪談的主要內容,我們做了不變更原意的編輯:

記者:我被人工智慧生成的影片震撼了,但我也擔心它們的影響。所以我請OpenAI 來做一期新的視頻,並和Murati 坐下來解答一些困惑。Sora 是如何運作的?
Mira Murati:它從根本上來說是一種擴散模型,這是一種生成模型。它從隨機噪聲開始創建一個圖像。如果是電影製作,人們必須確保上一幀延續到下一幀,物體之間保持一致性。這就給你一種現實感和存在感。如果你在幀之間打破它,你就會斷開,現實就不存在了。這就是Sora 做得很好的地方。
記者:假如我現在給出prompt:「紐約市人行道上的一名女性視頻製作人手裡拿著一台電影攝影機。突然,一個機器人從她手中偷走了照相機。」

Mira Murati:你可以看到它並沒有非常忠實地遵循提示。機器人並沒有把相機從她手中拉出來,反而這個人變成了機器人。這還有很多不完美的地方。
記者:我還注意到了一件事,當汽車經過時,它們會改變顏色。
Mira Murati:是的,所以雖然這個模型很擅長連續性,但它並不完美。所以你會看到黃色的計程車從框架中消失了一會兒,然後它以不同的形式回來了。
記者:那我們可以在生成後下達「讓計程車保持一致,讓它回來」這樣的指令嗎?
Mira Murati:現在是沒有辦法的,但我們正在為此而努力:怎麼把它變成人們可以編輯的、用來創造的一個工具。
記者:你覺得下面這段影片的prompt 是什麼?

Mira Murati:一頭公牛在瓷器商舖中嗎?可以看到它在不停地踩,但是沒有任何東西破碎。其實這應該是可以預測的,我們未來會提升穩定性和可控性,讓它更準確地反映出你的意圖。
記者:然後還有一個視頻,左邊的女人在一個鏡頭中看起來大概有15 個手指。

Mira Murati:手實際上有自己的運動方式。而且很難模擬手的運動。
記者:影片中的人物嘴巴有動作,但是沒有聲音。Sora 在這一方面有做功課嗎?
Mira Murati:目前確實是沒有聲音的,但未來一定會有的。
記者:你們用了哪些數據來訓練Sora?
Mira Murati:我們使用了公開可取得的資料和授權資料。
記者:例如YouTube 上的影片?
Mira Murati:這我不是很確定。
記者:那Facebook 或Instagram 上的影片?
Mira Murati:如果它們是公開可用的,可能會成為資料地一部分,但我不確定,我不敢打包票。
記者:那Shutterstock 呢?我知道你們和他們有協議。
Mira Murati:我只是不想詳細說明所使用的數據,但它是公開可獲得的或獲得許可的數據。
記者:產生一段20 秒的720p 影片需要多長時間?
Mira Murati:根據prompt 的複雜性,可能需要幾分鐘。我們的目標是真正專注於開發最好的能力。現在我們將開始研究優化技術,以便人們可以低成本使用它,使它易於使用。
記者:創造這些作品,肯定需要消耗大量的算力。與ChatGPT 反應或動態影像相比,產生這樣的東西需要多少算力?
Mira Murati:ChatGPT 和DALL・E 是為公眾使用它們而優化的,而Sora 實際上是一個研究輸出,要貴得多。我們當時不知道最終向公眾提供它時到底會是什麼樣子,但我們正試圖最終用與DALL・E 相似的成本提供它。
記者:最終是什麼時候呢?我真的很期待。
Mira Murati:肯定是今年,但可能是幾個月後了。
記者:你覺得是在11 月選舉前還是後呢?
Mira Murati:這是了一個需要慎重考慮處理錯誤訊息和有害偏見的問題。我們也不會公佈任何可能會影響選舉或其他議題,我們沒有把握的東西。
記者:有什麼東西是不能生成的。
Mira Murati:我們還沒有做出這些決定,但我認為我們的平台將會保持一致。所以應該類似DALL・E,你可以產生公眾人物的圖像。他們會有類似的Sora 政策。現在我們正處於探索模式,我們還沒有弄清楚所有的限制在哪裡,以及我們將如何圍繞它們。
記者:那裸體呢?
Mira Murati:你知道的,有一些創造性的設置,藝術家可能想要有更多的控制。現在,我們正在與來自不同領域的藝術家和創作者合作,以弄清楚該工具應該提供什麼樣的靈活性。
記者:你如何確保測試這些產品的人不會被非法或有害的內容吞噬?
Mira Murati:這當然很難。在早期階段,這是Red Teaming(紅隊測試)的一部分,你必須考慮到它,並確保人們願意並能夠做到這一點。當我們與承包商合作時,我們會更深入地了解這個過程,但這無疑是困難的。
記者:我們現在正在嘲笑這些影片(產生效果不好的影片),但是當這類技術影響到工作時,影片產業的人可能在幾年後就不會笑了。
Mira Murati:我認為這是一種擴展創造力的工具,我們希望電影行業的人們,無論在哪裡的創作者,都能參與其中,告知我們如何進一步開發和部署它。此外,當人們貢獻數據等時,使用這些模型的經濟學是什麼。
記者:從所有這些技術中可以清楚地看出,科技很快就會變得更快、更好,而且廣泛可用。到時,怎麼將真實影片和AI 影片區分開?
Mira Murati:我們也在研究這些問題,包括為影片加浮水印。不過我們要先搞清楚內容來源,人們如何區分真實內容、現實中發生的事情和虛假內容,這也是我們還沒有部署這些系統的原因,大規模部署前要先解決這些問題。
記者:有你這些話就能安心點了。不過,人們還是非常擔心矽谷籌集資金創造AI 工具,還有他們對金錢和權利的野心會危害人類的安全。
Mira Murati:平衡利潤和安全並不是真正的難題,真正困難的部分是搞清楚安全與社會問題,這就是我堅持下去的真正原因。
記者:這個產品確實讓人驚艷,但也引發不少擔憂,我們也討論過了,真值得嗎?
Mira Murati:絕對值得。AI 工具將擴展我們的知識和創造力、集體想像、做任何事情的能力。在這個過程中,找到將AI 融入日常生活的正確道路,也是極其困難的,但我認為這絕對值得一試。
AI 時代,第一是人才,第二是數據,第三是算力。OpenAI 在儲備了眾多人才的同時,該如何解決數據問題,還需要時間給出答案。