The world's most powerful open source model changed hands overnight! Google Gemma 7B crushes Llama 2 13B, rekindling the open source war
2024.02.22

There was a loud bang in the middle of the night, Google actually open sourced LLM? !

This time, the heavy open source Gemma is available in 2B and 7B scales and is built using the same research and technology as Gemini.

With the blessing of Gemini homologous technology, Gemma not only achieves SOTA performance at the same scale.
And even more impressively, it can outperform larger models, such as the Llama 2 13B, on key benchmarks.
At the same time, Google also released a 16-page technical report.

Technical report address: https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
Google said that the name Gemma comes from the Latin word "gemma", which means "gem", and seems to symbolize its preciousness.
Historically, Transformers, TensorFlow, BERT, T5, JAX, AlphaFold and AlphaCode are all innovations contributed by Google to the open source community.

Google: Today I will show you what Open AI is
And Gemma, which Google launched simultaneously globally today, is bound to once again set off an upsurge in building open source AI.
At the same time, it also confirmed OpenAI’s reputation as “the only ClosedAI”.
OpenAI has become very popular recently due to Sora, Llame is said to be making big moves, and Google is taking the lead again. The big companies in Silicon Valley have taken over the world!

Google: I want them all, open source and closed source
Hugging Face CEO also posted congratulations.

A screenshot of Gemma's appearance on the Hugging Face hot list was also posted.

Keras author François Chollet said bluntly: The most powerful open source large model has changed hands today.

Some netizens have personally tried it and said that Gemma 7B is really fast.
Google simply punched GPT-4 with Gemini and kicked Llama 2 with Gemma!

Netizens are also watching the excitement, calling on Mistral AI and OpenAI to make some big moves tonight to prevent Google from really stealing the headlines. (Manual dog head)
Refresh SOTA on the same scale, leapfrog Llama 2 13B
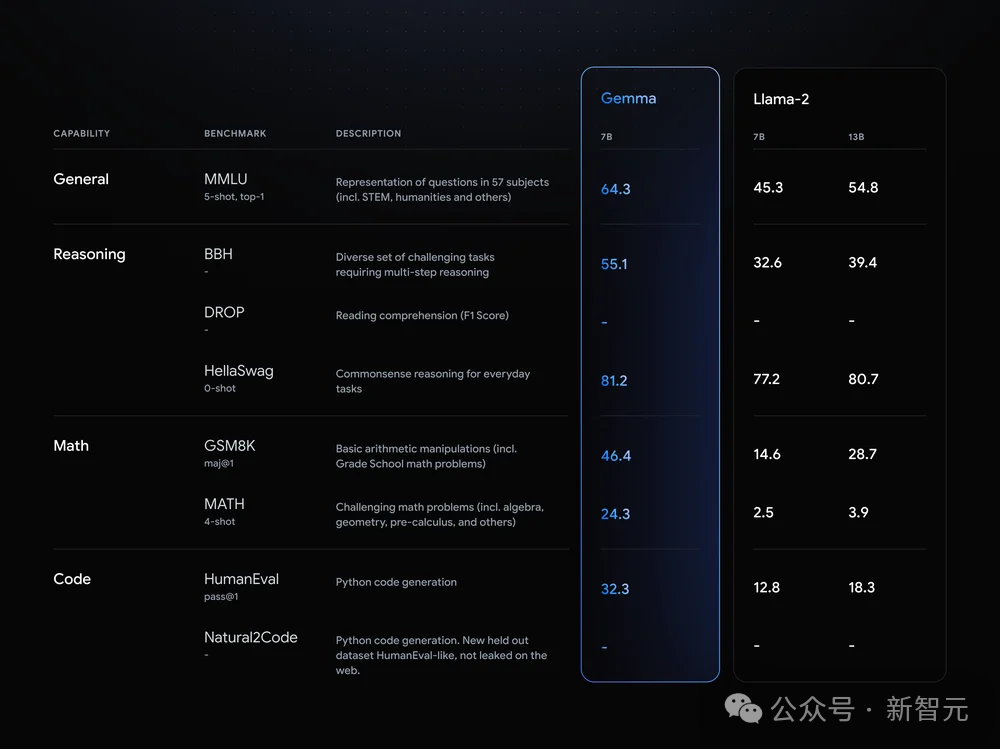
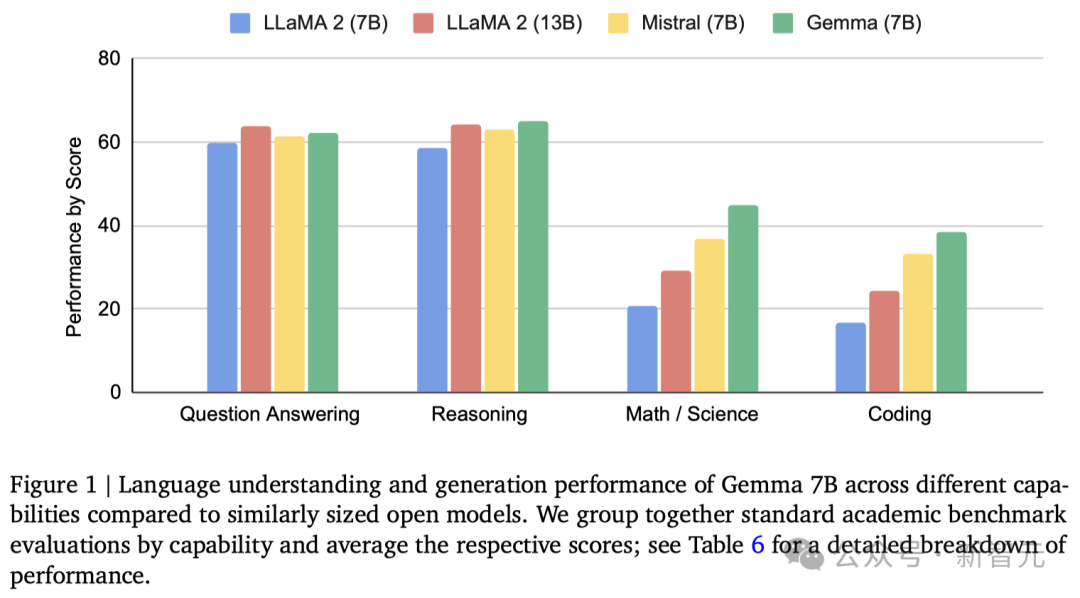
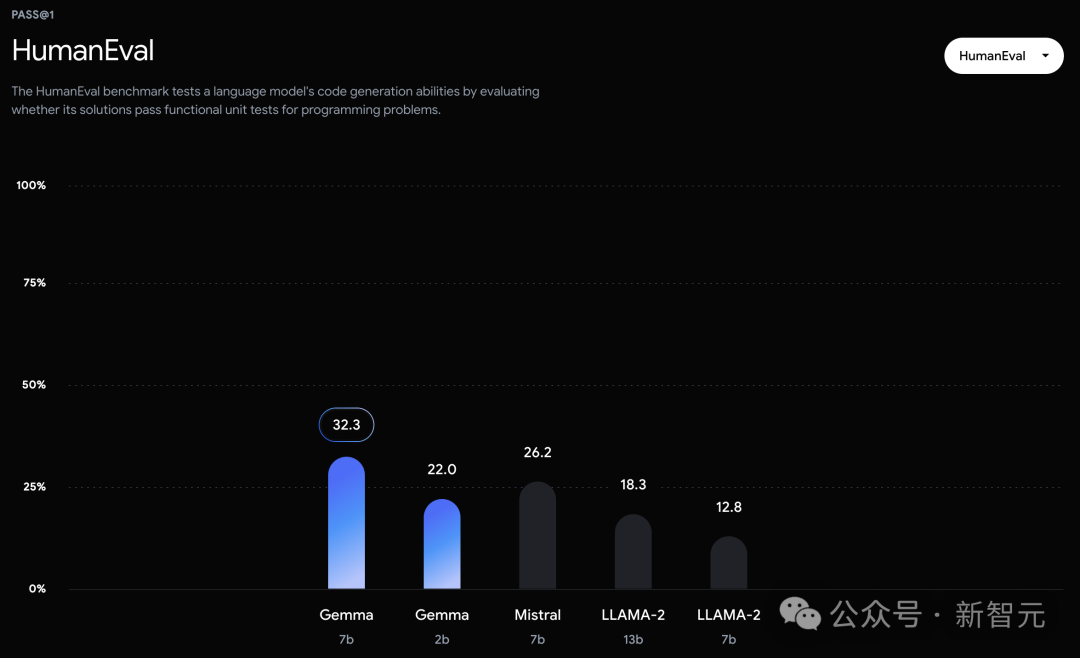
It can be seen that the performance of the Gemma-7B model has surpassed Llama 2 7B and 13B in 8 benchmark tests covering general language understanding, reasoning, mathematics and coding!
And it also surpassed the performance of the Mistral 7B model, especially in math, science, and coding-related tasks.

In terms of security, both the Gemma-2B IT and Gemma-7B IT models, which were fine-tuned with instructions, exceeded the Mistal-7B v0.2 model in human preference evaluations.
In particular, the Gemma-7B IT model performs even better in understanding and executing specific instructions.

A complete set of tools: Optimize across frameworks, tools and hardware
This time, in addition to the model itself, Google also provides a set of tools to help developers ensure the responsible use of Gemma models and help developers use Gemma to build safer AI applications.
- Google provides a complete tool chain for JAX, PyTorch and TensorFlow, supports model inference and supervised fine-tuning (SFT), and is fully compatible with the latest Keras 3.0.
- Users can easily start exploring Gemma through pre-built Colab and Kaggle notebooks, as well as integration with popular tools such as Hugging Face, MaxText, NVIDIA NeMo and TensorRT-LLM.
- Gemma models can be run on personal laptops and workstations, or deployed on Google Cloud, supporting easy deployment on Vertex AI and Google Kubernetes Engine (GKE).
- Google has also optimized Gemma cross-platform to ensure its excellent performance on a variety of AI hardware such as NVIDIA GPU and Google Cloud TPU.
And, the Terms of Use provide all organizations with access to responsible commercial use and distribution, regardless of organization size.

But, there is no complete victory
However, Gemma was not able to win SOTA in all lists.
In the official evaluation, Gemma 7B successfully defeated the Llama 2 7B and 13B models in MMLU, HellaSwag, SIQA, CQA, ARC-e, HumanEval, MBPP, GSM8K, MATH and AGIEval.
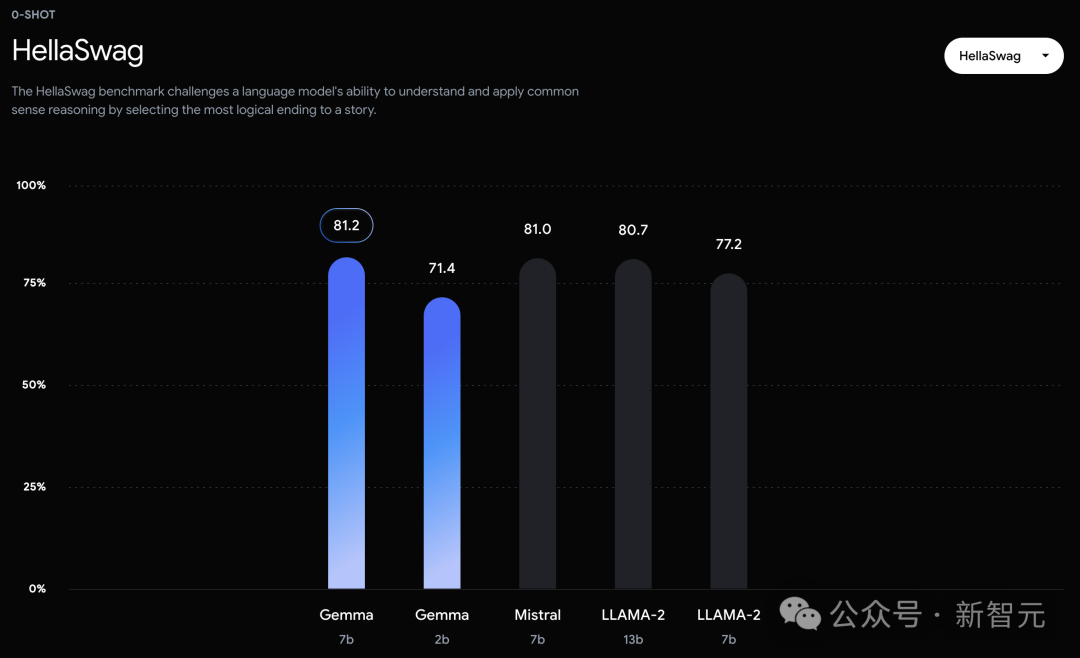
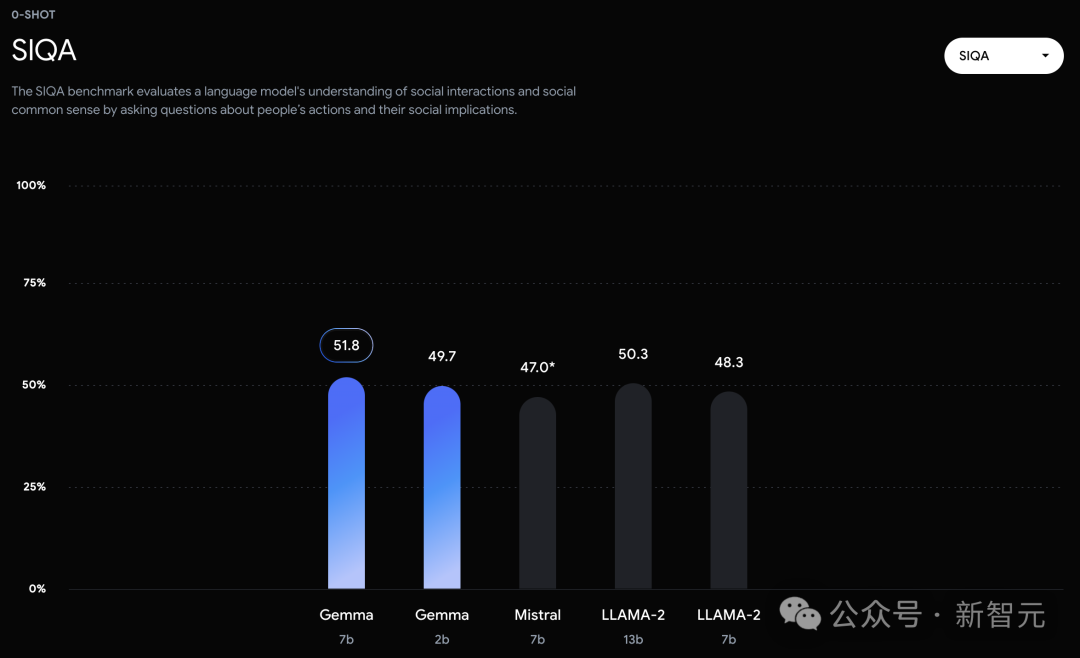
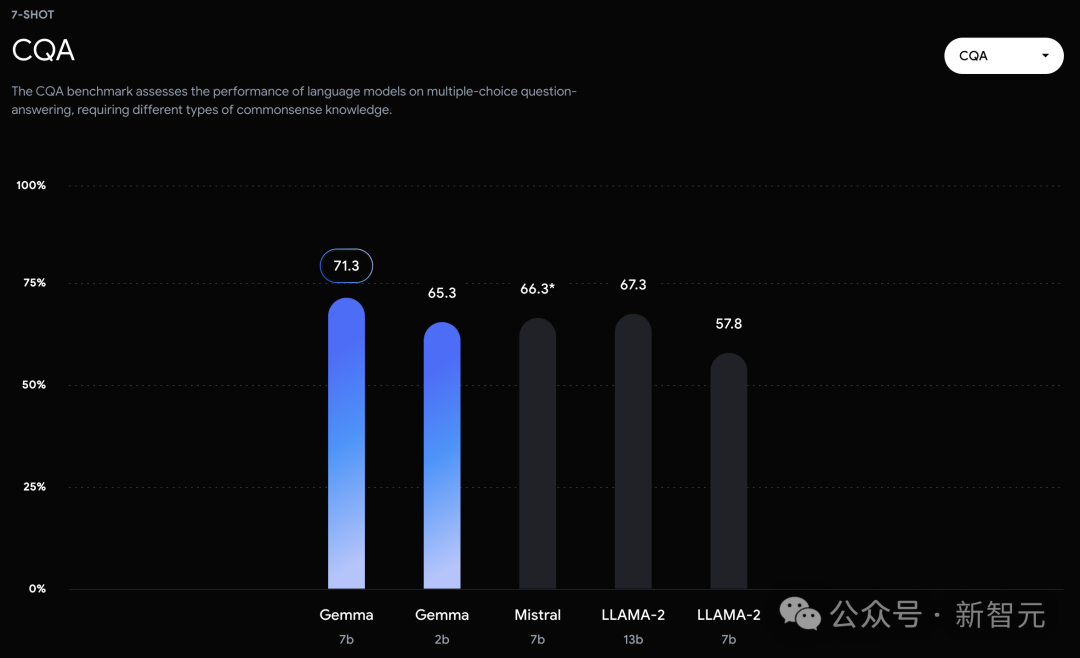
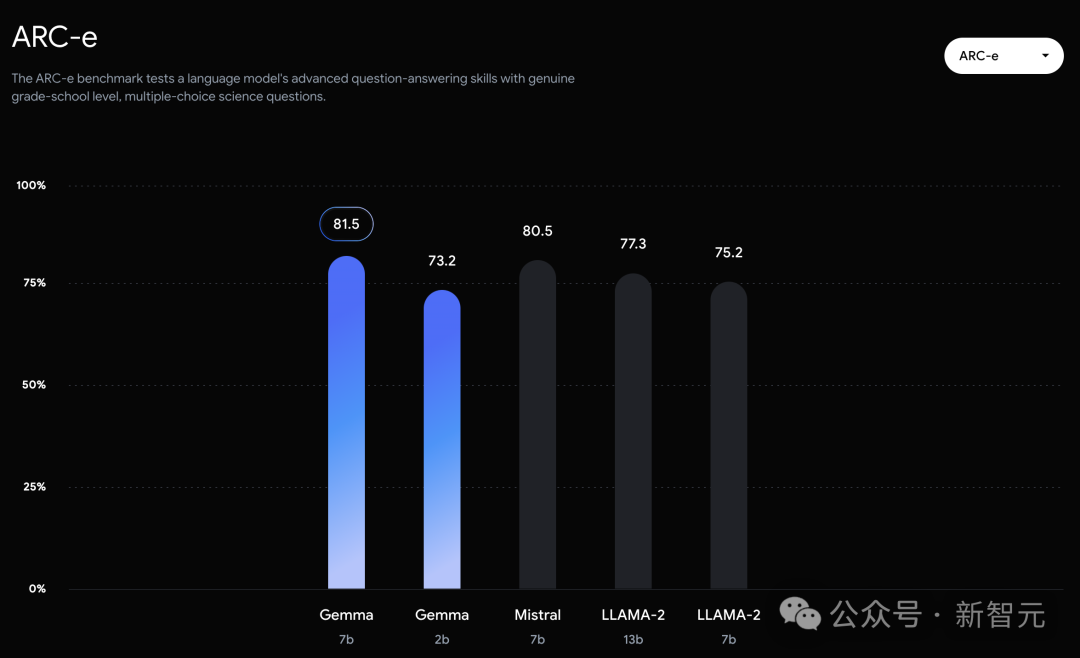
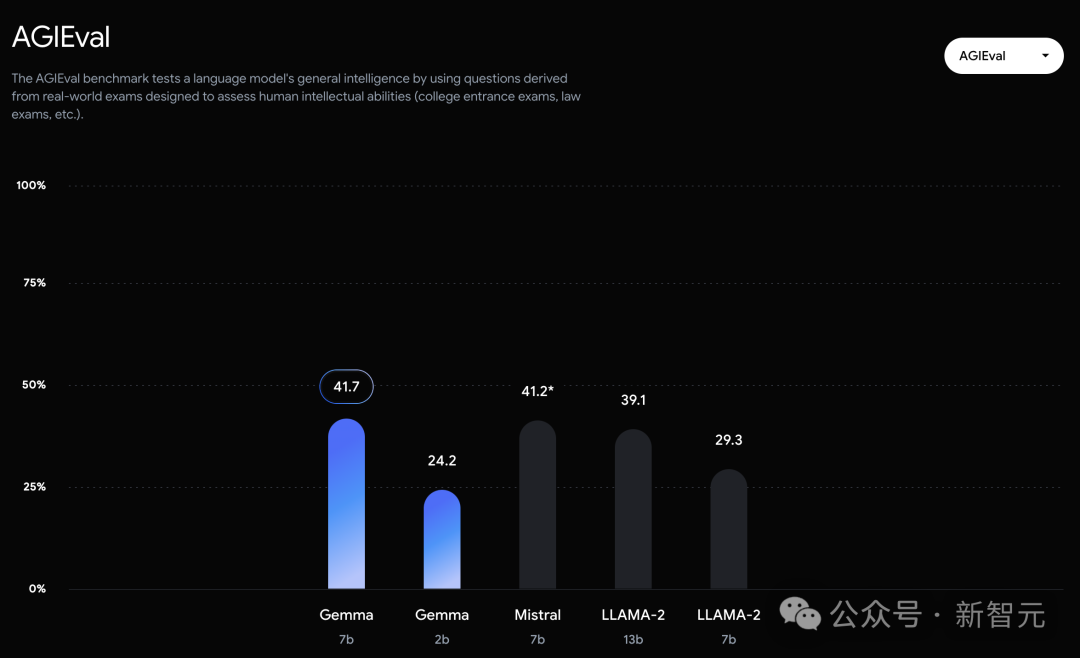
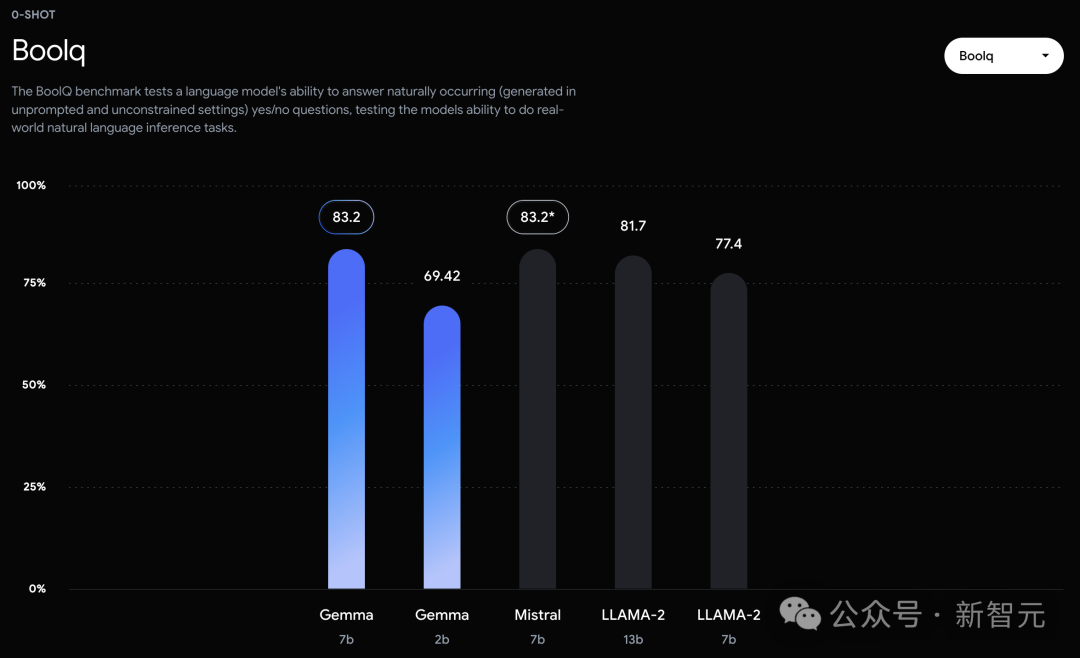
In contrast, the Gemma 7B only tied with the Mistral 7B in the Boolq test.
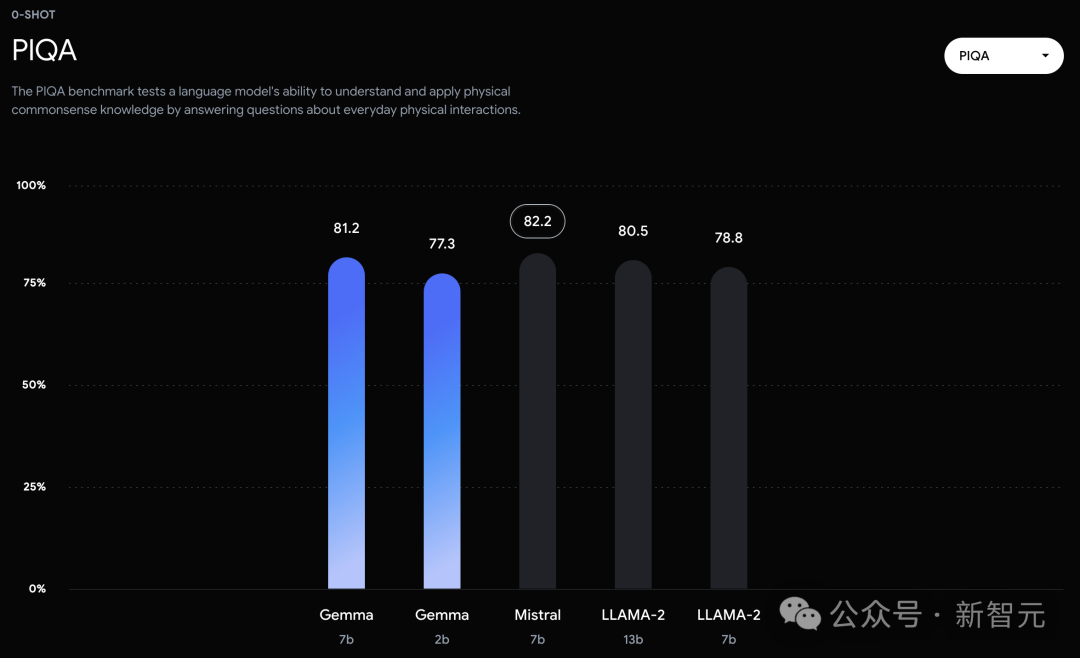
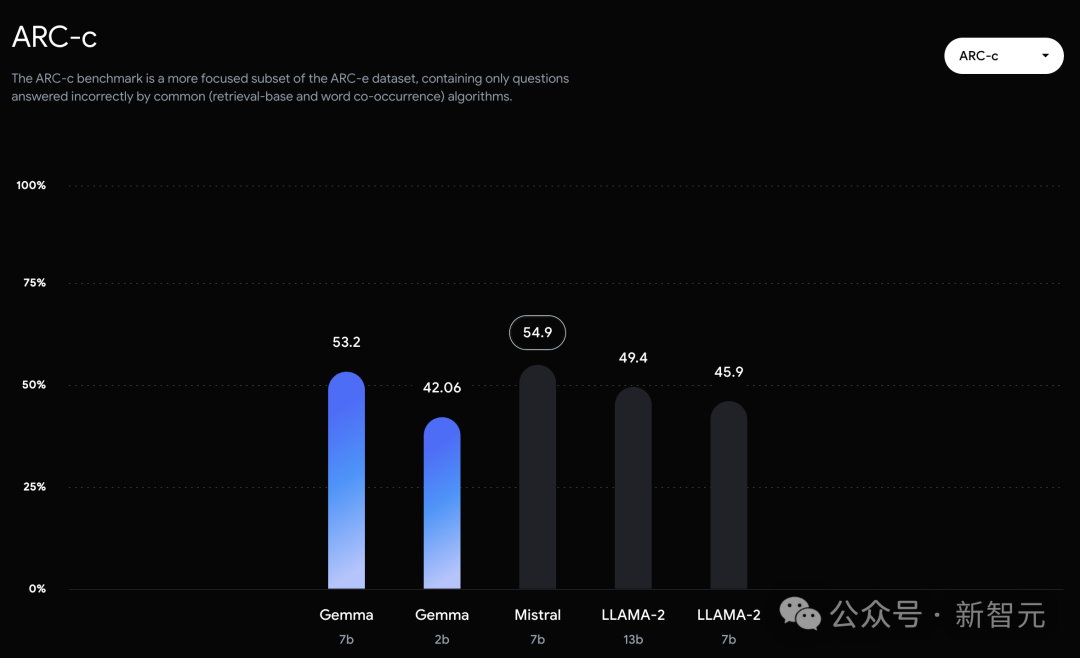
In PIQA, ARC-c, Winogrande and BBH, it is defeated by Mistral 7B.
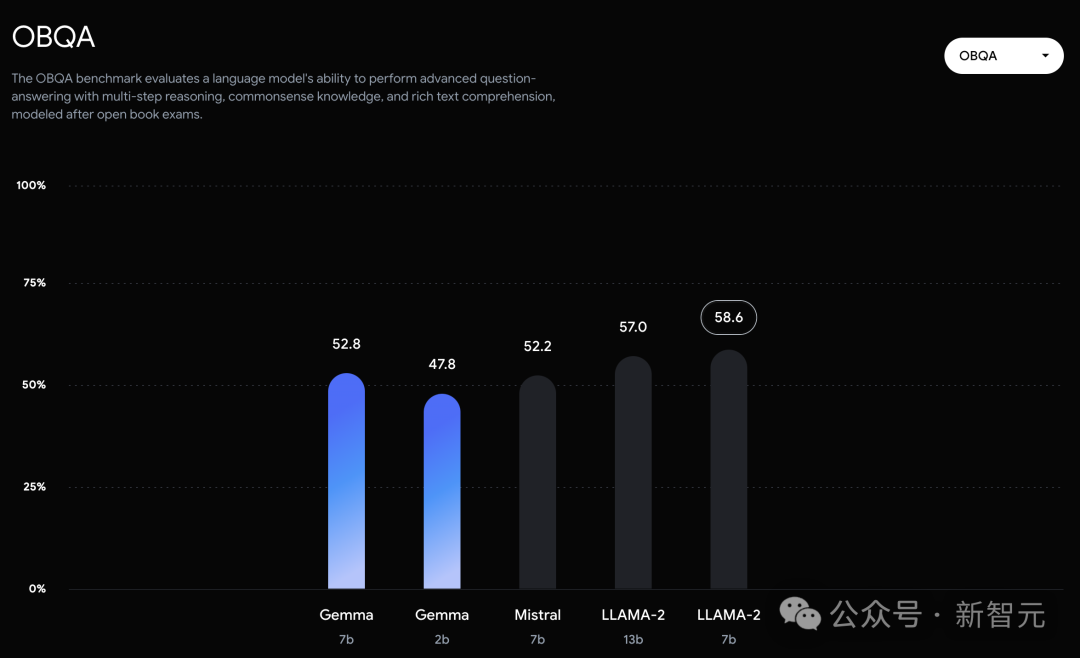
In OBQA and trivalent QA, they were defeated by Llama 2 7B of 7B and 13B scale.
Technical Reports
Google released two versions of the Gemma model this time. The 7 billion parameter model is used for efficient deployment and development on GPUs and TPUs, and the 2 billion parameter model is used for CPU and end-side applications.
Gemma outperforms open source models of similar parameter sizes in 11 of 18 text-based tasks, such as question answering, common sense reasoning, mathematics and science, and coding.
In terms of model architecture, Gemma has made several improvements based on Transformer, allowing it to demonstrate better performance and efficiency when handling complex tasks.
- Multi-query attention mechanism
Among them, the 7B model uses a multi-head attention mechanism, while the 2B model uses a multi-query attention mechanism. The results show that these specific attention mechanisms can improve performance at different model sizes.
- RoPE embedded
Unlike traditional absolute position embedding, the model uses rotational position embedding technology at each layer, and the embedding is shared between the input and output of the model, which can effectively reduce the size of the model.
- GeGLU activation function
Replacing the standard ReLU activation function with the GeGLU activation function can improve the performance of the model.
- Normalizer Location
The input and output of each Transformer sub-layer are normalized. RMSNorm is used here as the normalization layer to ensure the stability and efficiency of the model.
The core parameters of the architecture are as follows:

The parameters for the two scales are as follows:

pre-training
training data
Gemma 2B and 7B were trained on 2T and 6T tokens, respectively, on primarily English data from web documents, mathematics, and code.
Unlike Gemini, these models are not multimodal and are not trained SOTA for multilingual tasks.
Google uses a subset of Gemini's SentencePiece tokenizer to achieve compatibility.
Instruction fine-tuning
The team fine-tuned the Gemma 2B and 7B models, including supervised fine-tuning (SFT) and reinforcement learning based on human feedback (RLHF).
In the supervised fine-tuning phase, the researchers used a dataset consisting of plain text, English, human- and machine-generated question-answer pairs.
In the reinforcement learning stage, a reward model trained based on English preference data and a set of carefully selected high-quality prompts are used as strategies.
The researchers found that these two stages are critical to improving the performance of the model in automatic evaluation and human preference evaluation.
Supervise fine-tuning
The researchers selected data mixtures for supervised fine-tuning based on LM-based parallel evaluation.
Given a set of hold-out prompts, we generate responses from the test model, responses to the same prompts from the baseline model, randomly shuffle them, and then ask a larger, more capable model to express between the two responses. preferences.
The researchers constructed different sets of cues to highlight specific abilities, such as following instructions, being practical, creative, and safe.
We used different LM-based automatic judges, employing a range of techniques such as thought chain prompts, using scoring criteria and charters, etc., in order to be consistent with human preferences.
RLHF
The researchers further used reinforcement learning from human feedback (RLHF) to optimize the model that had been subjected to supervised fine-tuning.
They collected their preference choices from human evaluators and trained a reward function based on the Bradley-Terry model, similar to what the Gemini project did.
The researchers used an improved version of the REINFORCE algorithm and added the Kullback–Leibler regularization term in order to allow the strategy to optimize the reward function while maintaining consistency with the originally adjusted model.
Similar to the previous supervised fine-tuning stage, in order to adjust the hyperparameters and further prevent the reward mechanism from being abused, the researchers used a high-performance model as an automatic evaluation tool and directly compared it with the baseline model.
Performance evaluation
automatic assessment
Google has evaluated Gemma's performance in multiple areas, including physical and social reasoning, question answering, programming, mathematics, common sense reasoning, language modeling, reading comprehension, etc.
The Gemma2B and 7B models were compared against multiple external open source large language models on a range of academic benchmarks.
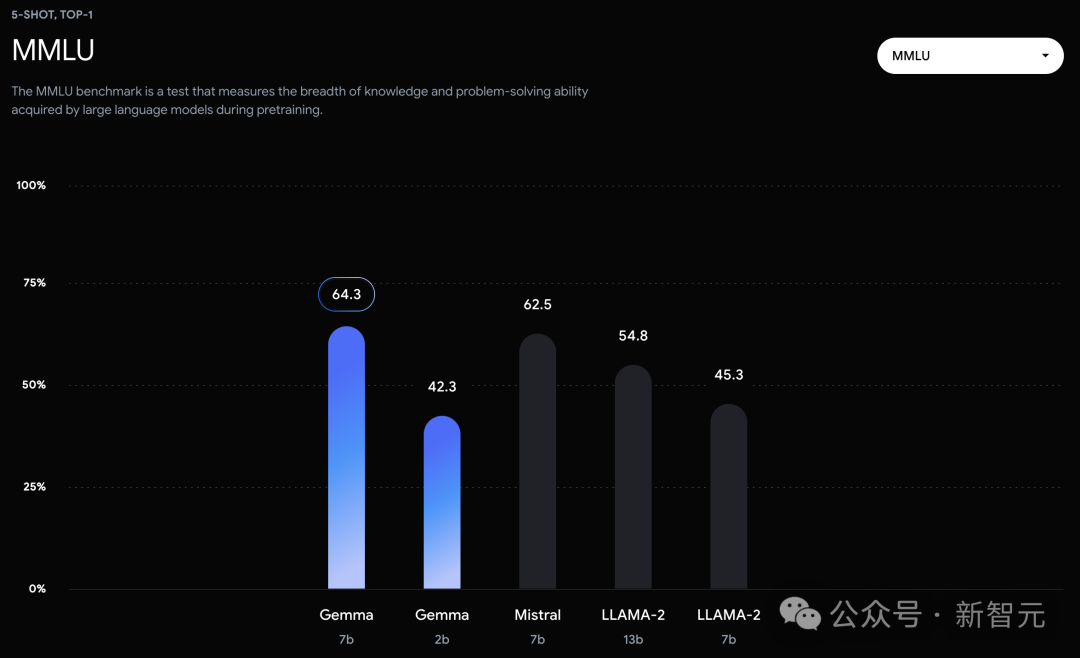
On the MMLU benchmark, the Gemma 7B model not only outperformed all open source models of the same size or smaller, but also outperformed some larger models, including Llama 2 13B.

However, the creators of the benchmark assessed the performance of human experts at 89.8%, and Gemini Ultra is the first model to exceed this standard, indicating that Gemma still has a lot of room for improvement to achieve Gemini and human-level performance.
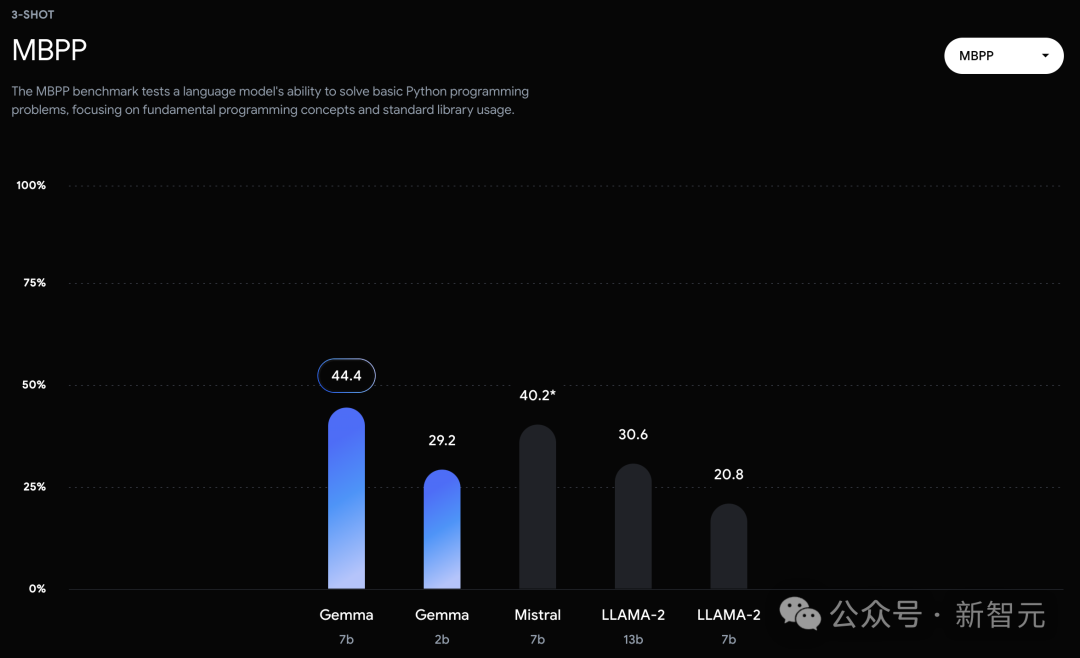
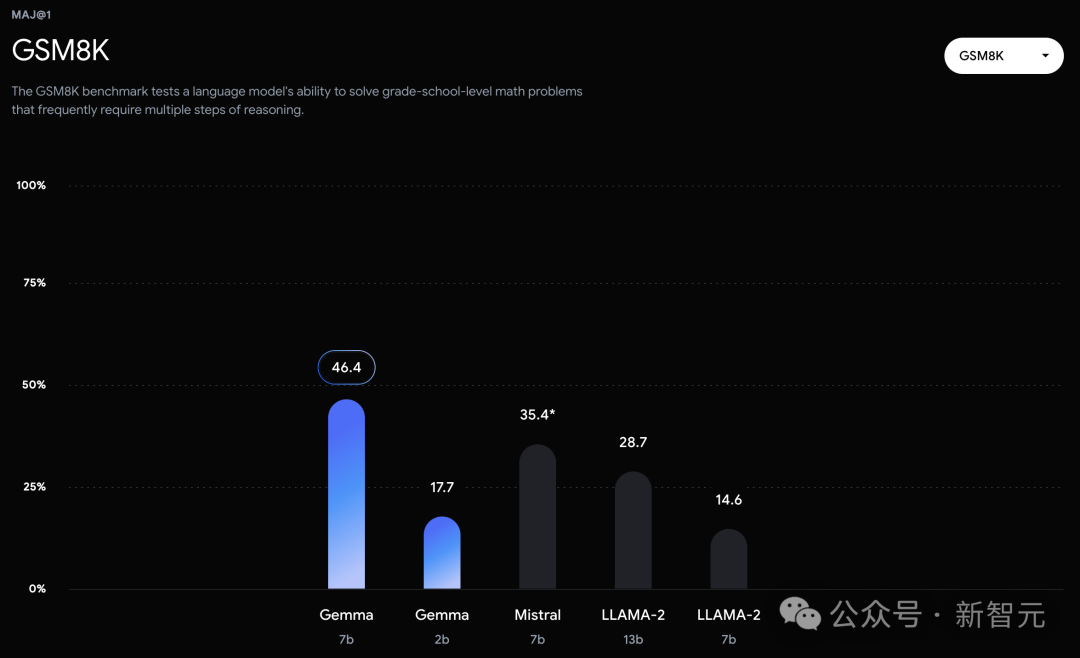
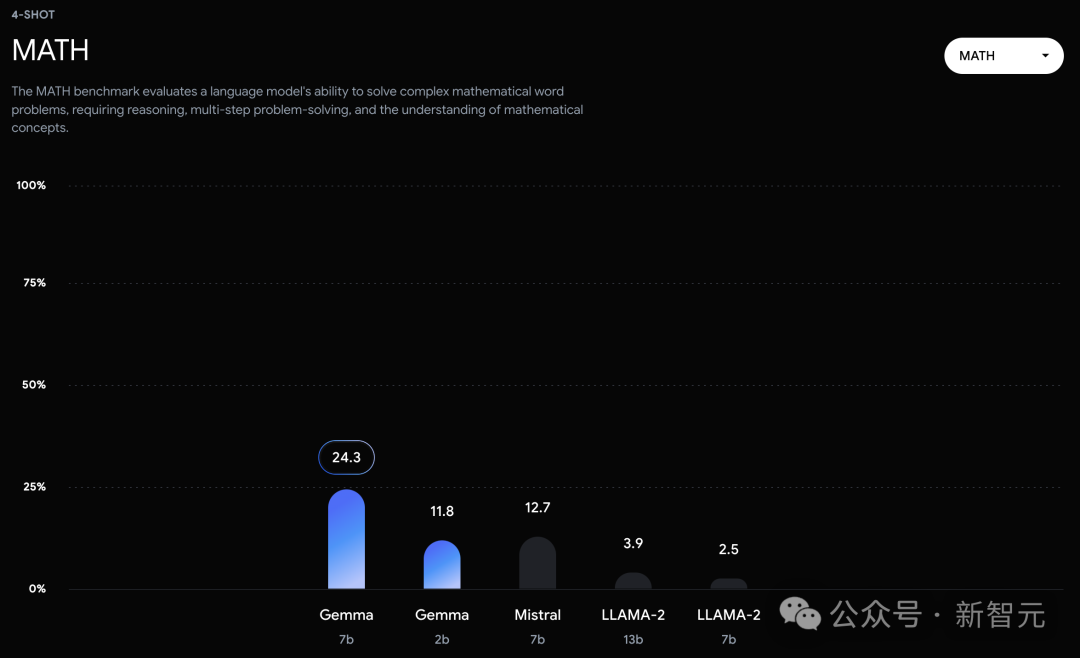
Moreover, the Gemma model performs particularly well in mathematics and programming benchmarks.
In mathematical tasks typically used to evaluate a model's analytical capabilities, the Gemma model leads other models by at least 10 points on the GSM8K and more challenging MATH benchmarks.
Likewise, on HumanEval, they are at least 6 points ahead of other open source models.
Gemma even surpassed the performance of the CodeLLaMA 7B model dedicated to code fine-tuning on MBPP (CodeLLaMA scored 41.4%, while Gemma 7B scored 44.4%).
memory assessment
Recent research has found that even carefully aligned AI models can be vulnerable to new adversarial attacks that can circumvent existing alignment measures.
Such hits have the potential to make a model behave erratically, sometimes even causing it to repeatedly output data that it memorized during training.
Therefore, researchers focus on the "detectable memory" ability of the model, which is considered an upper limit for evaluating the memory ability of the model and has been used as a common definition in many studies.
The researchers conducted a memory test on the Gemma pre-trained model.
Specifically, they randomly selected 10,000 documents from each dataset and used the first 50 tokens of the document as prompts for the model.
The focus of the test is accurate memory, that is, if the model can accurately generate the next 50 tokens based on the input, which are completely consistent with the original text, the model is considered to have "remembered" the text.
In addition, in order to detect whether the model can remember information in a rewritten form, the researchers also tested the model's "approximate memory" ability, which allows for an editing gap of up to 10% between the generated text and the original text.
In Figure 2, the test results of Gemma are compared with the PaLM and PaLM 2 models of similar size.

It can be found that Gemma's memory rate is significantly lower (see the left side of Figure 2).
However, by estimating the "total memory amount" of the entire pre-training data set, a more accurate evaluation result can be obtained (see the right side of Figure 2): Gemma's performance in memorizing training data is equivalent to PaLM.
The issue of memorization of personal information is particularly critical. As shown in Figure 3, the researchers did not find memorized sensitive information.

While some data classified as "personal information" was indeed found to be memorized, the frequency of this occurrence was relatively infrequent.
And these tools tend to produce many false positives (because they only match patterns without considering context), which means the amount of personal information researchers uncover is likely overestimated.
Summary discussion
In general, the Gemma model has improved in many fields such as dialogue, logical reasoning, mathematics and code generation.
In the MMLU (64.3%) and MBPP (44.4%) tests, Gemma not only demonstrated excellent performance, but also showed room for further improvement in the performance of open source large language models.
In addition to the advanced performance achieved on standard test tasks, Google also looks forward to working with the community to promote development in this area.
Gemma learned a lot from the Gemini model project, including coding, data processing, architecture design, instruction optimization, reinforcement learning based on human feedback, and evaluation methods.
At the same time, Google once again emphasized a series of limitations when using large language models.
Despite its excellent performance on standard testing tasks, further research is needed to create a model that is both stable and secure and can reliably perform its intended tasks, including ensuring the accuracy of information, goal alignment of the model, handling complex logical reasoning, and Enhance the model's resistance to malicious input.
The team said that as Gemini pointed out, more challenging and robust test benchmarks are needed.
team member
Core contributors:

Other contributors:

Product Managers, Project Managers, Executive Sponsors, Principals and Technical Leads:
