Sora, who is out of the circle, has made DiT popular, even on the GitHub hot list, and has evolved a new version of SiT
2024.02.21

Although it has been released for nearly a week, the impact of OpenAI's large video generation model Sora continues!
Among them, the DiT (Diffusion Transformer) paper "Scalable Diffusion Models with Transformers" written by Bill Peebles, one of Sora's R&D leaders, and Xie Saining, an assistant professor at New York University, is considered to be one of the important technical foundations behind Sora. This paper was accepted by ICCV 2023.

- Paper address: https://arxiv.org/pdf/2212.09748v2.pdf
- GitHub address: https://github.com/facebookresearch/DiT
In the past two days, DiT papers and GitHub projects have become more popular and have regained a lot of attention.
The paper appears on the Trending Research list of PapersWithCode, with nearly 2,700 stars; it also appears on the GitHub Trending list, with the number of stars increasing by hundreds every day, and the total number of stars exceeding 3,000.
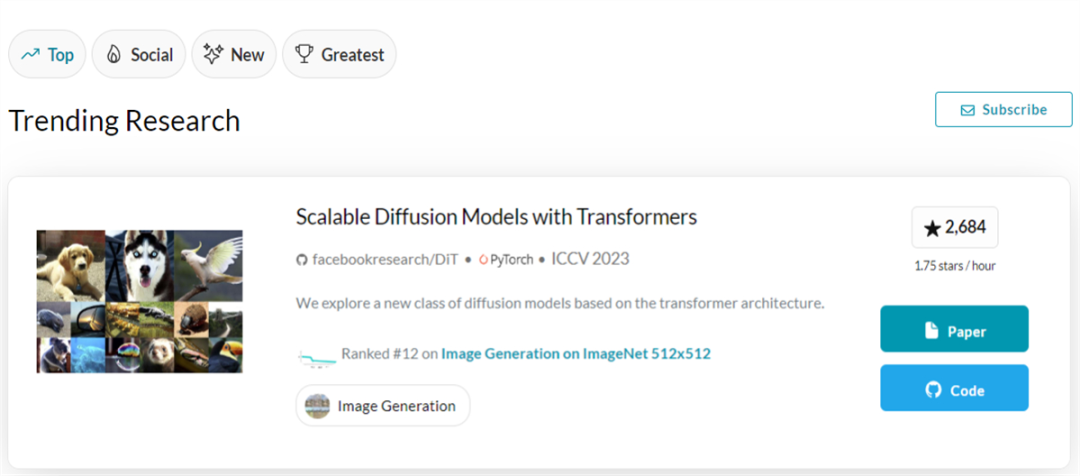
Source: https://paperswithcode.com/
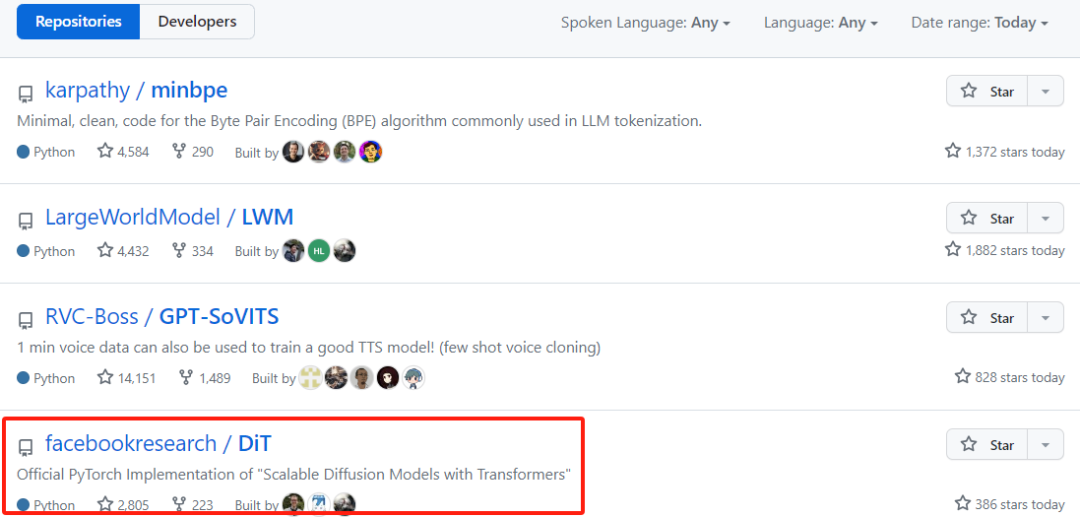
Source: https://github.com/facebookresearch/DiT
The earliest version of this paper is December 2022, and the second version was updated in March 2023. At that time, diffusion models achieved amazing results in image generation, and almost all of these models used convolutional U-Net as the backbone.
Therefore, the purpose of the paper is to explore the implications of architectural choices in diffusion models and provide an empirical baseline for future generative model research. This study shows that U-Net inductive bias is not critical to the performance of diffusion models and can be easily replaced with standard designs such as transformers.
Specifically, the researchers proposed a new diffusion model DiT based on the transformer architecture, and trained a latent diffusion model, replacing the commonly used U-Net backbone network with a Transformer that operates on potential patches. They analyze the scalability of the Diffusion Transformer (DiT) through the forward pass complexity measured in Gflops.
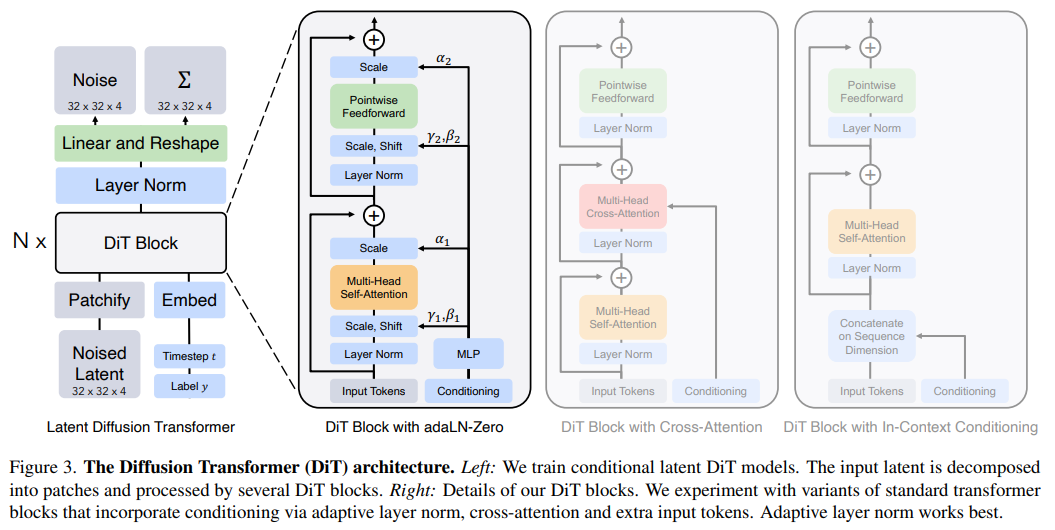
The researchers tried four configurations that varied in model depth and width: DiT-S, DiT-B, DiT-L and DiT-XL.

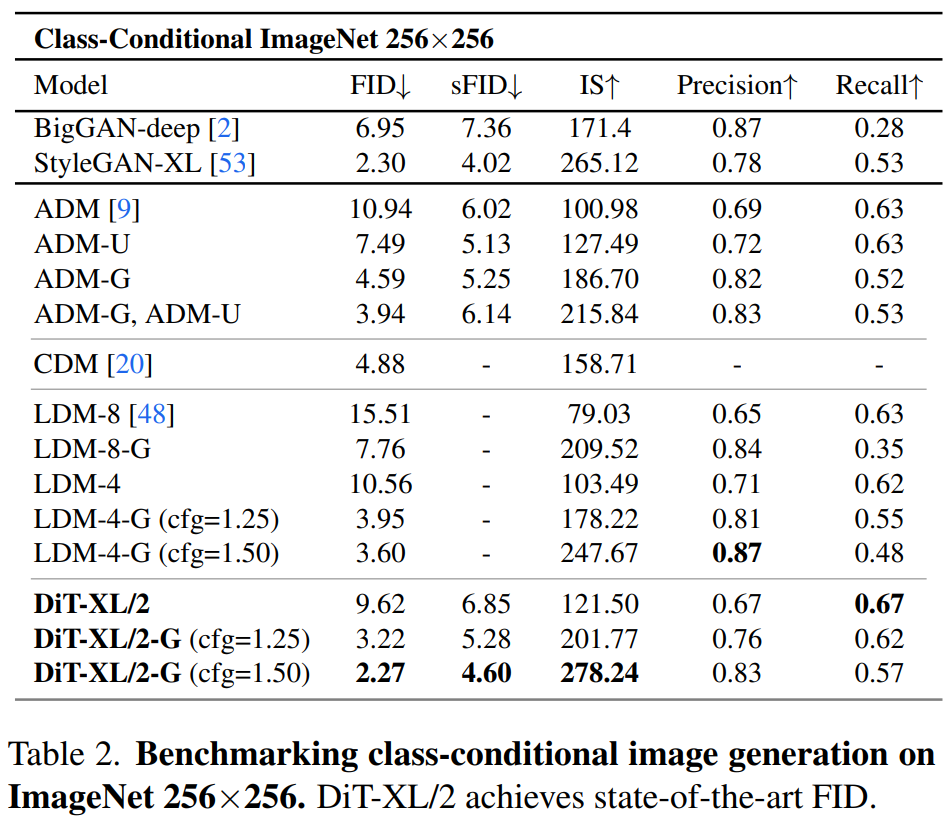
They found that DiT with higher Gflops always had lower FID by increasing the Transformer depth/width or increasing the number of input tokens.
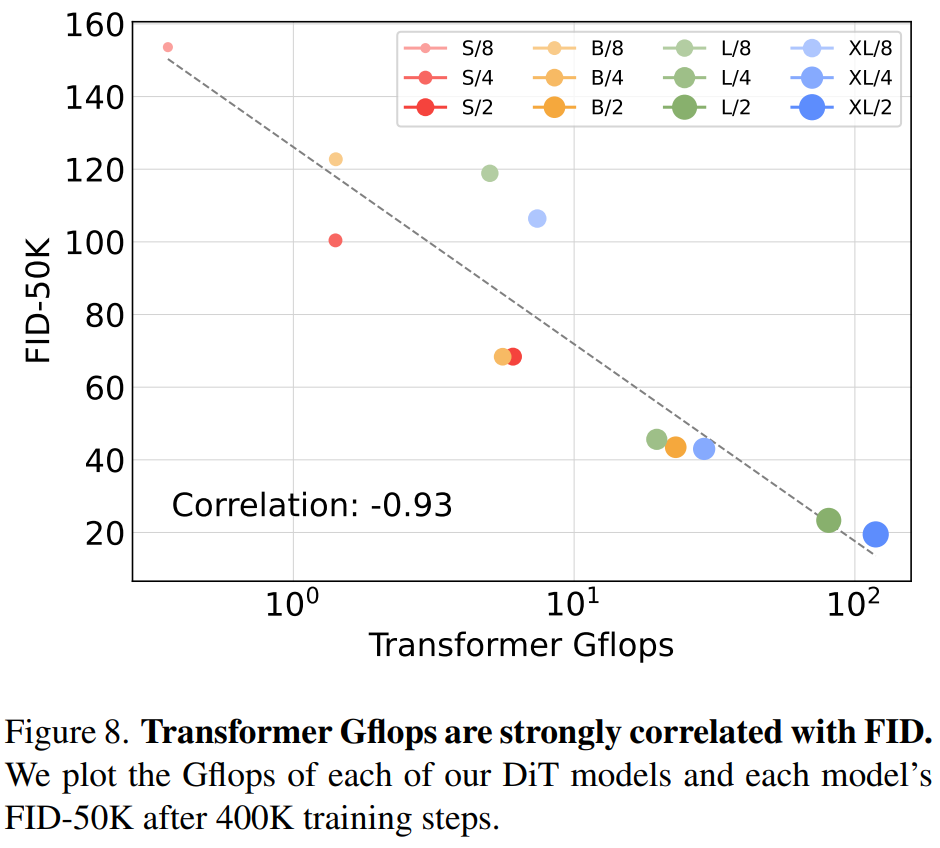
In addition to good scalability, the DiT-XL/2 model outperforms all previous diffusion models on the class-conditional ImageNet 512×512 and 256×256 benchmarks, achieving a FID of 2.27 on the latter SOTA data .
SiT with better quality, speed and flexibility
In addition, DiT also received an upgrade in January this year! Xie Saining and his team launched SiT (Scalable Interpolant Transformer, scalable interpolation Transformer). The same backbone achieves better quality, speed and flexibility.
SiT goes beyond standard diffusion and explores a wider design space through interpolation, says Shesenin.
The paper is titled "SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers".

- Paper address: https://arxiv.org/pdf/2401.08740.pdf
- GitHub address: https://github.com/willisma/SiT
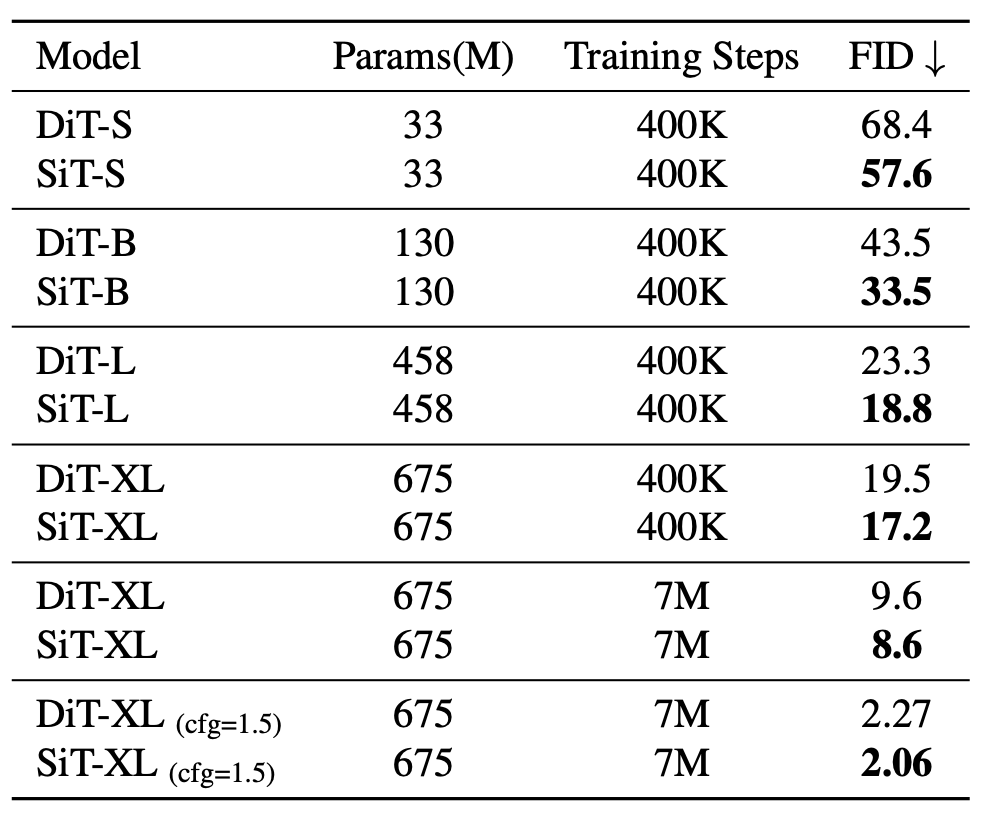
Simply put, SiT integrates a flexible interpolation framework into DiT, enabling nuanced exploration of dynamic transport in image generation. SiT's FID on ImageNet 256 is 2.06, pushing interpolation-based models to new heights.

Nanye Ma, the first author of the paper and an undergraduate student at New York University, interpreted the paper. This paper argues that stochastic interpolation provides a unifying framework for diffusion and flow. However, it was noted that there is a performance difference between DiT based on DDPM (Denoising Diffusion Probabilistic Model) and newer interpolation based models. Therefore, researchers want to explore the source of performance improvement?
They answer this question by gradually transitioning from the DiT model to the SiT model through a series of orthogonal steps in the design space. The performance impact of each move away from the diffusion model was also carefully evaluated.
The researchers found that interpolation and samplers had the greatest impact on performance. They observed huge improvements when switching the interpolation (i.e. distribution path) from variance-preserving to linear and the sampler from deterministic to stochastic.
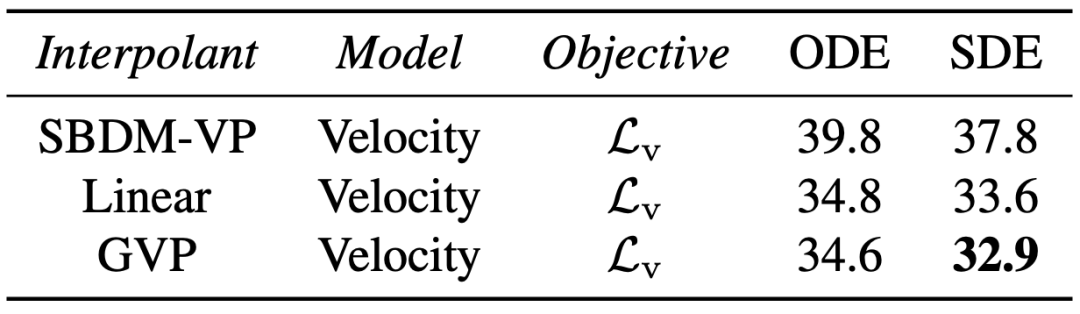
For random sampling, the researchers show that the diffusion coefficient does not need to be tied between training and sampling, and there are many choices in terms of inference time. Both deterministic and stochastic samplers have their advantages under different computational budgets.
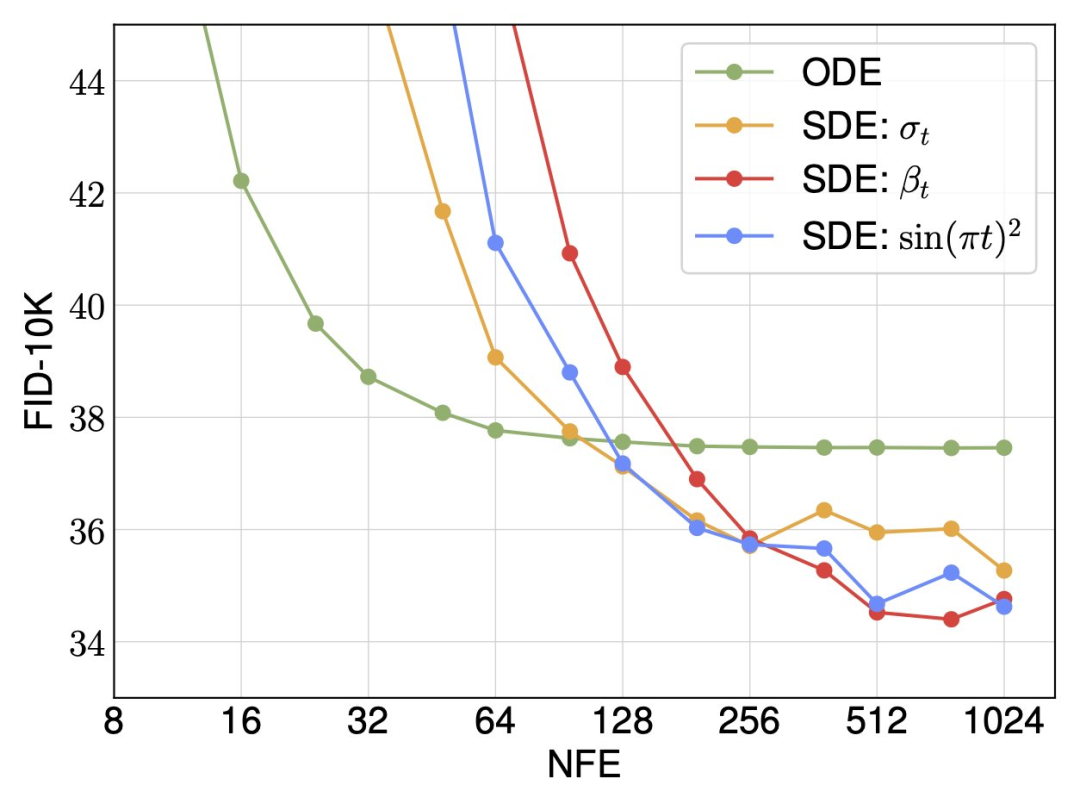
Finally, the researchers describe SiT as a continuous, speed-predictable, linearly schedulable, and SDE sampling model. Like the diffusion model, SiT can achieve performance improvements and is superior to DiT.
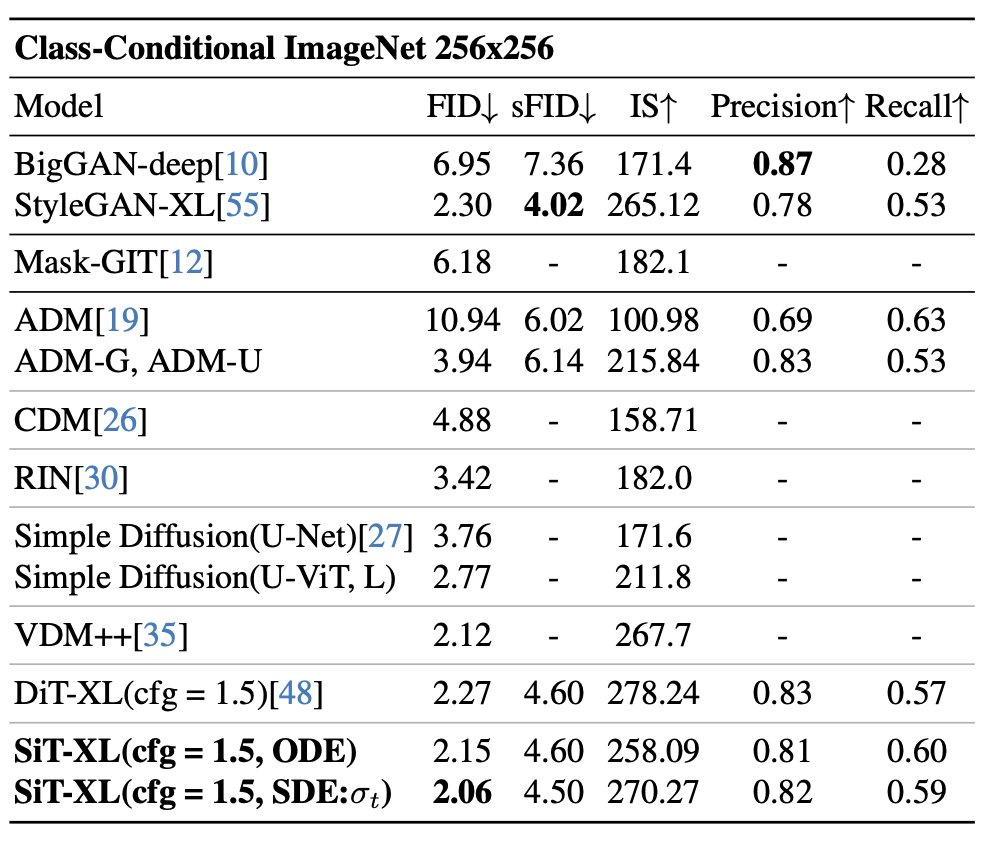
For more information on DiT and SiT please see the original paper.