出圈的Sora帶火DiT,連登GitHub熱榜,已進化出新版SiT
2024.02.21

雖然已經發布近一周時間,OpenAI 影片生成大模型Sora 的影響仍在繼續!
其中,Sora 研發負責人之一Bill Peebles 與紐約大學助理教授謝賽寧撰寫的DiT(擴散Transformer)論文《Scalable Diffusion Models with Transformers》被認為是此次Sora 背後的重要技術基礎之一。論文被ICCV 2023 接收。

- 論文網址:https://arxiv.org/pdf/2212.09748v2.pdf
- GitHub 網址:https://github.com/facebookresearch/DiT
這兩天,DiT 論文和GitHub 專案的熱度水漲船高,重新收穫大量關注。
論文出現在PapersWithCode 的Trending Research 榜單上,星標數量已近2700;還登上了GitHub Trending 榜單,星標數量每日數百增長,Star 總量已超3000。
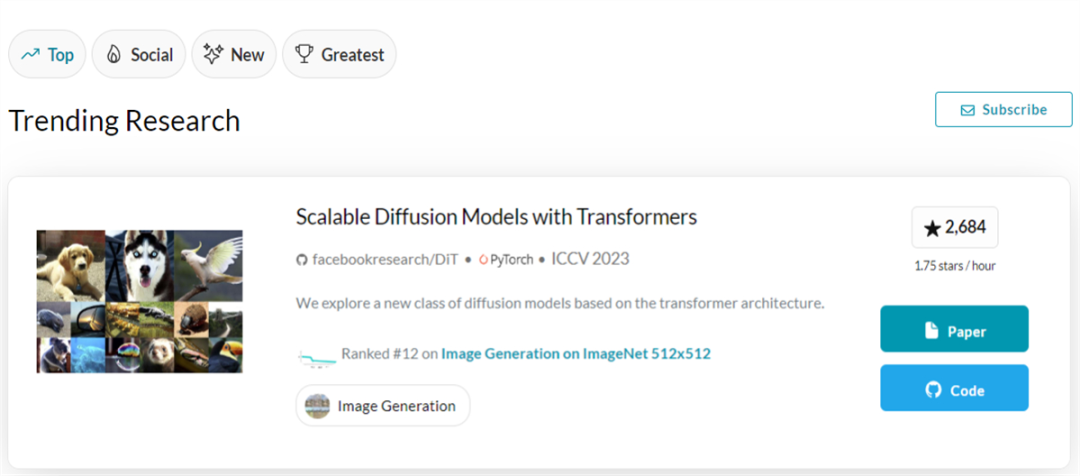
資料來源:https://paperswithcode.com/
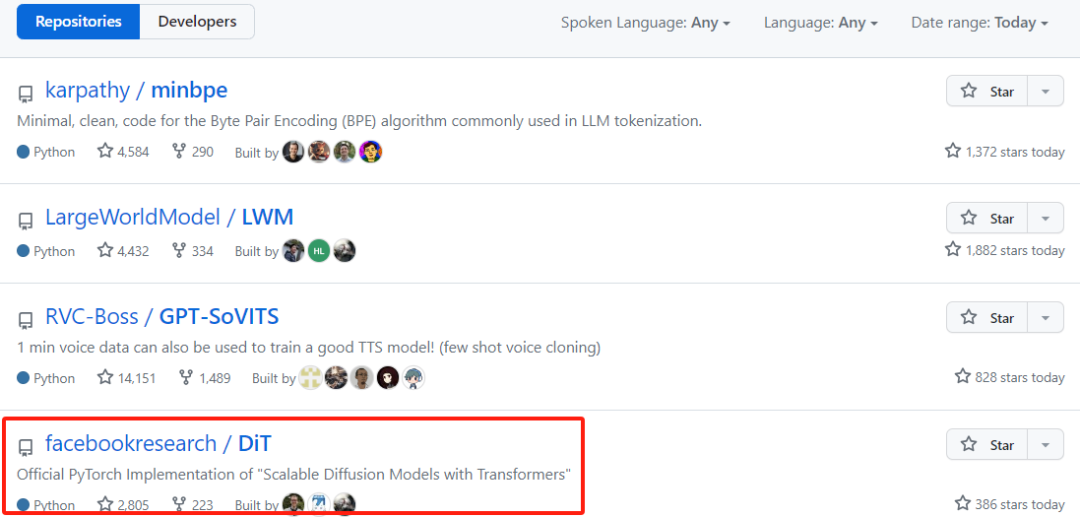
來源:https://github.com/facebookresearch/DiT
這篇論文最早的版本是2022 年12 月,2023 年3 月更新了第二版。當時,擴散模型在影像生成方面取得了驚人的成果,幾乎所有這些模型都使用卷積U-Net 作為主幹。
因此,論文的目的是探討擴散模型中架構選擇的意義,並為未來的生成模型研究提供經驗基線。該研究表明,U-Net 歸納偏壓對擴散模型的性能不是至關重要的,並且可以輕鬆地用標準設計(如transformer)取代。
具體來說,研究者提出了一種基於transformer 架構的新型擴散模型DiT,並訓練了潛在擴散模型,以對潛在patch 進行操作的Transformer 取代常用的U-Net 主幹網路。他們以Gflops 衡量的前向傳遞複雜度來分析擴散Transformer (DiT) 的可擴展性。
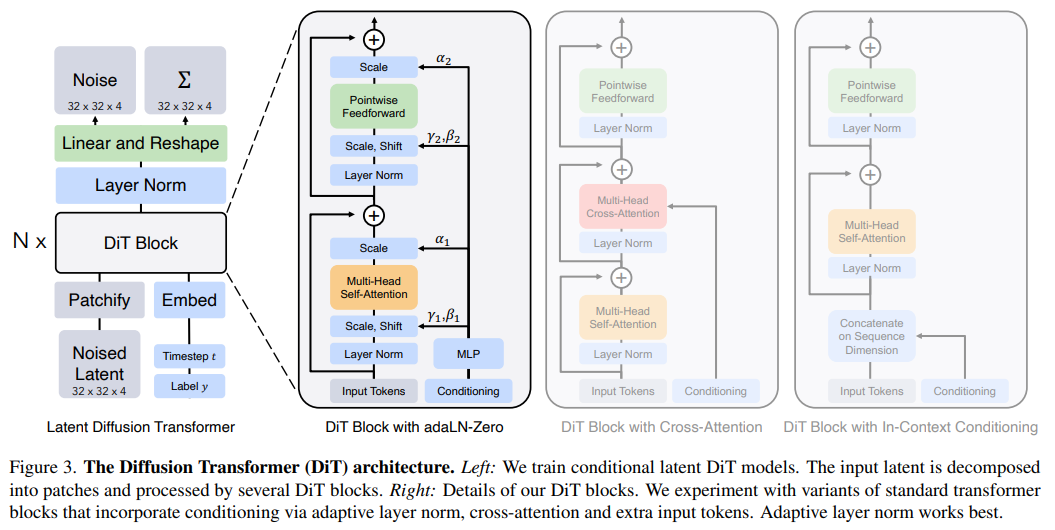
研究者嘗試了四種因模型深度和寬度而異的配置:DiT-S、DiT-B、DiT-L 和DiT-XL。

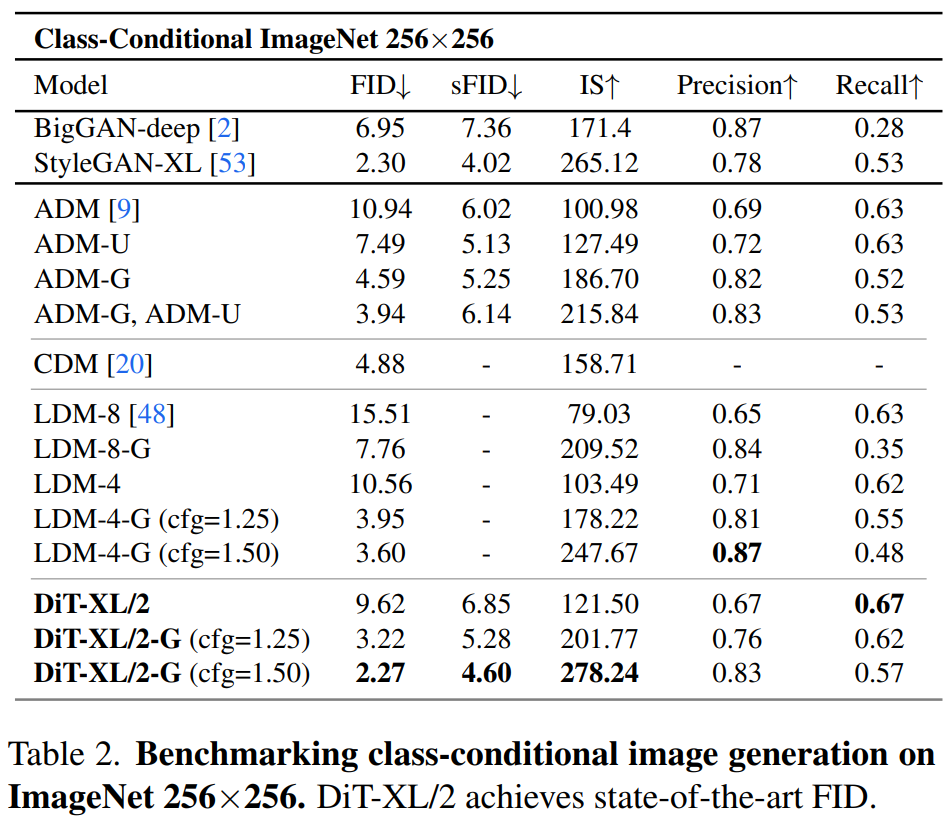
他們發現,透過增加Transformer 深度/ 寬度或增加輸入token 數量,具有較高Gflops 的DiT 始終具有較低的FID。
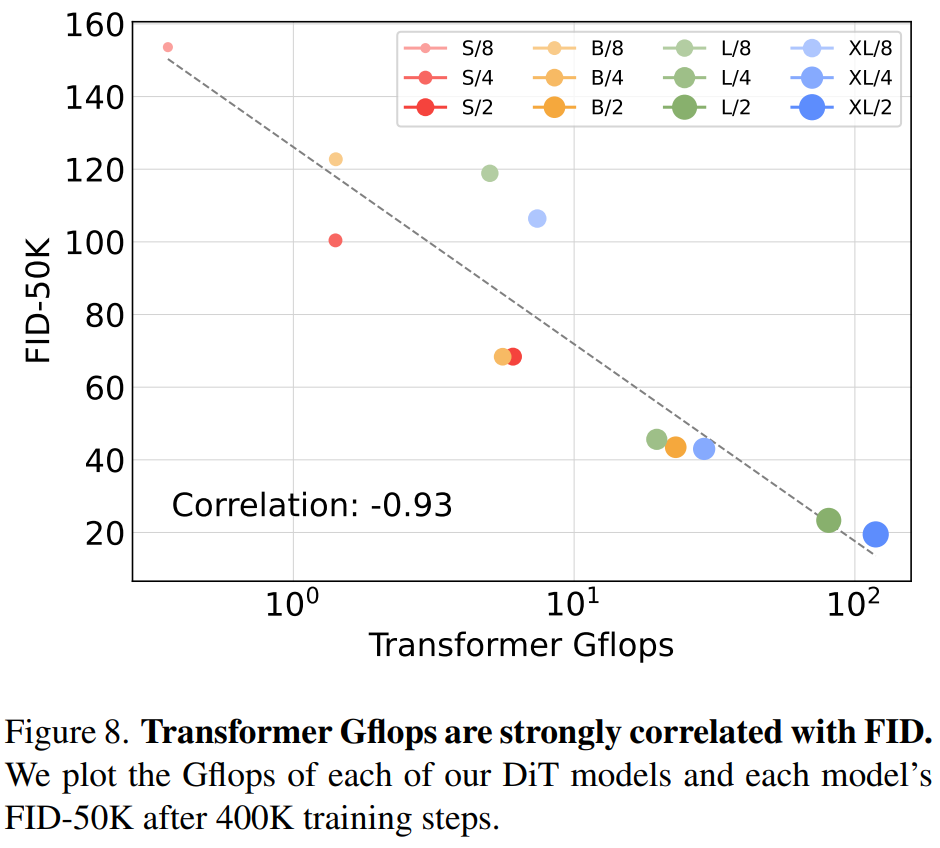
除了良好的可擴展性之外,DiT-XL/2 模型在class-conditional ImageNet 512×512 和256×256 基準上的效能優於所有先前的擴散模型,在後者上實現了2.27 的FID SOTA 數據。
品質、速度、靈活性更好的SiT
另外,DiT 還在今年1 月迎來了升級!謝賽寧及團隊推出了SiT(Scalable Interpolant Transformer,可擴展插值Tranformer),相同的骨幹實現了更好的品質、速度和靈活性。
謝賽寧表示,SiT 超越了標準擴散並透過插值來探索更廣闊的設計空間。
論文標題為《SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers》。

- 論文網址:https://arxiv.org/pdf/2401.08740.pdf
- GitHub 網址:https://github.com/willisma/SiT
簡單來講,SiT 將靈活的插值框架整合到了DiT 中,從而能夠對影像生成中的動態傳輸進行細微的探索。 SiT 在ImageNet 256 的FID 為2.06,將基於內插的模型推向了新的高度。

論文一作、紐約大學本科生Nanye Ma 對這篇論文進行了解讀。本文認為,隨機插值為擴散和流提供了統一的框架。但又注意到, 基於DDPM(去噪擴散機率模型)的DiT 與較新的基於插值的模型之間存在性能差異。因此,研究者想要探究性能提升的來源是什麼?
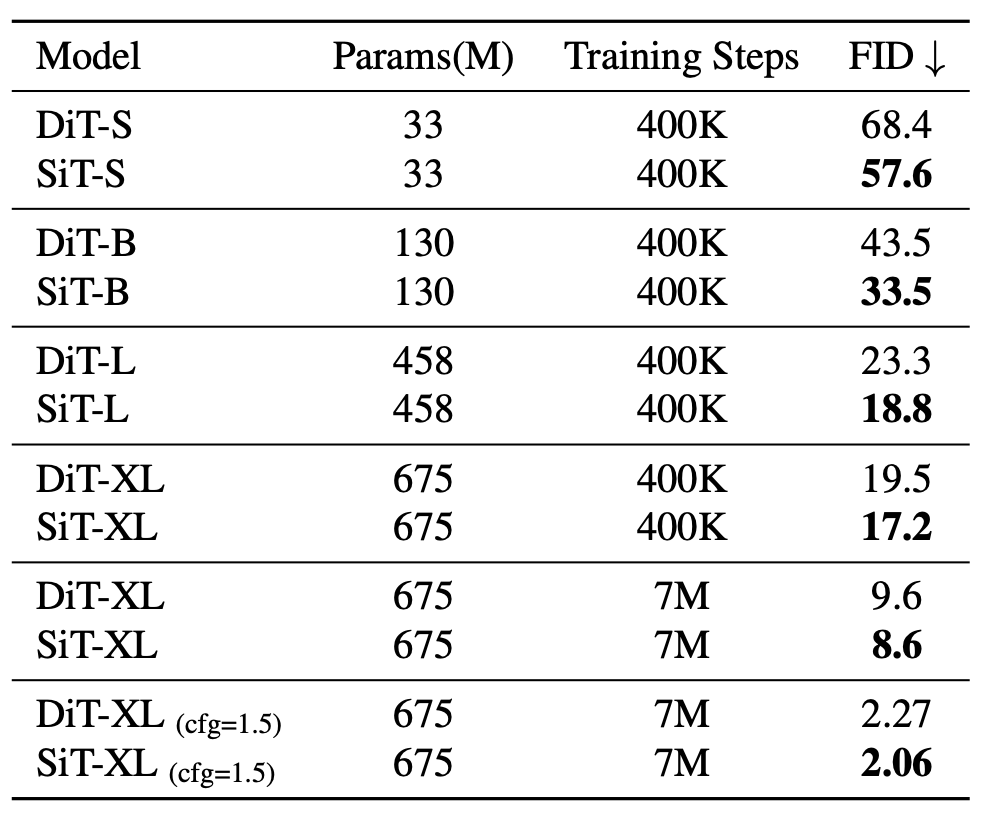
他們透過設計空間中的一系列正交步驟,逐漸地從DiT 模型過渡到SiT 模型來解答這個問題。同時仔細評估了每個遠離擴散模型的舉措對性能的影響。
研究者發現,插值和採樣器對性能的影響最大。當將插值(即分佈路徑)從方差保留切換到線性以及將採樣器從確定性切換到隨機性時,他們觀察到了巨大的改進。
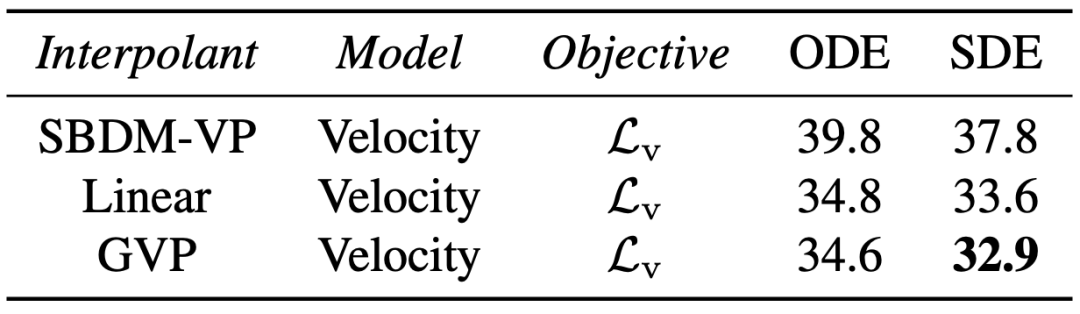
對於隨機採樣,研究者表明擴散係數不需要在訓練和採樣之間綁定,在推理時間方面可以有很多選擇。同時確定性和隨機採樣器在不同的計算預算下各有其優勢。
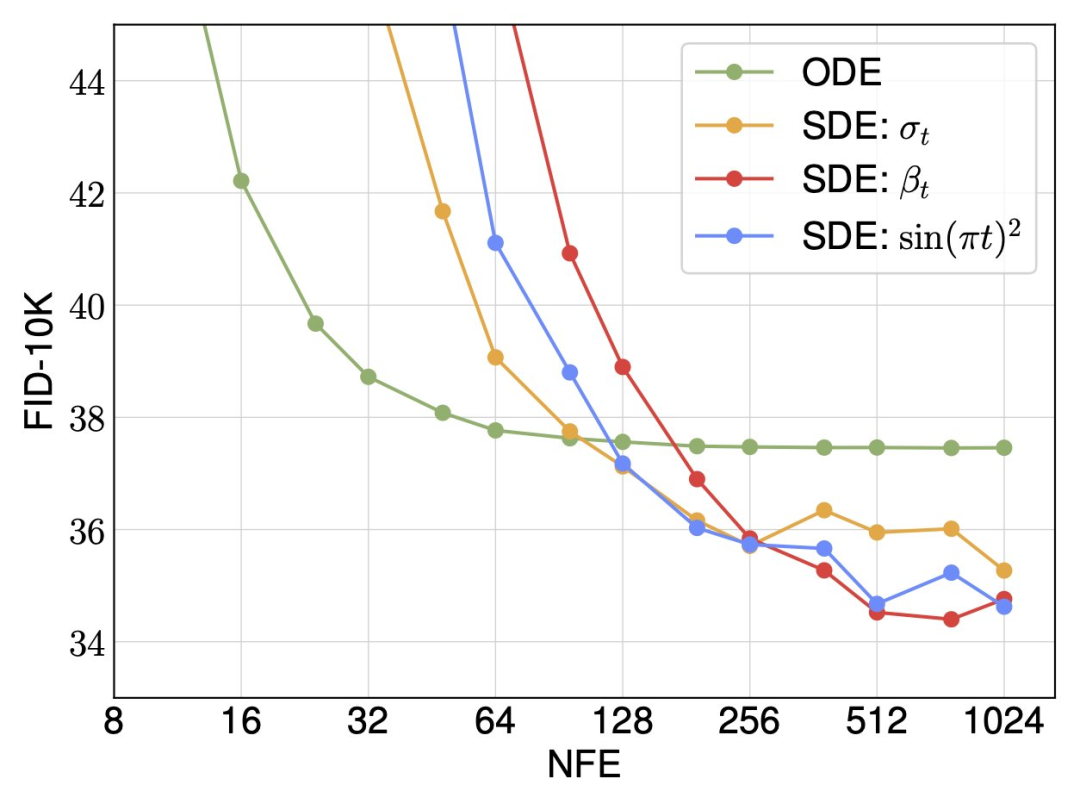
最後,研究者將SiT 描述為連續、速度可預測、線性可調度和SDE 取樣的模型。與擴散模型一樣,SiT 可以實現性能提升,並且優於DiT。
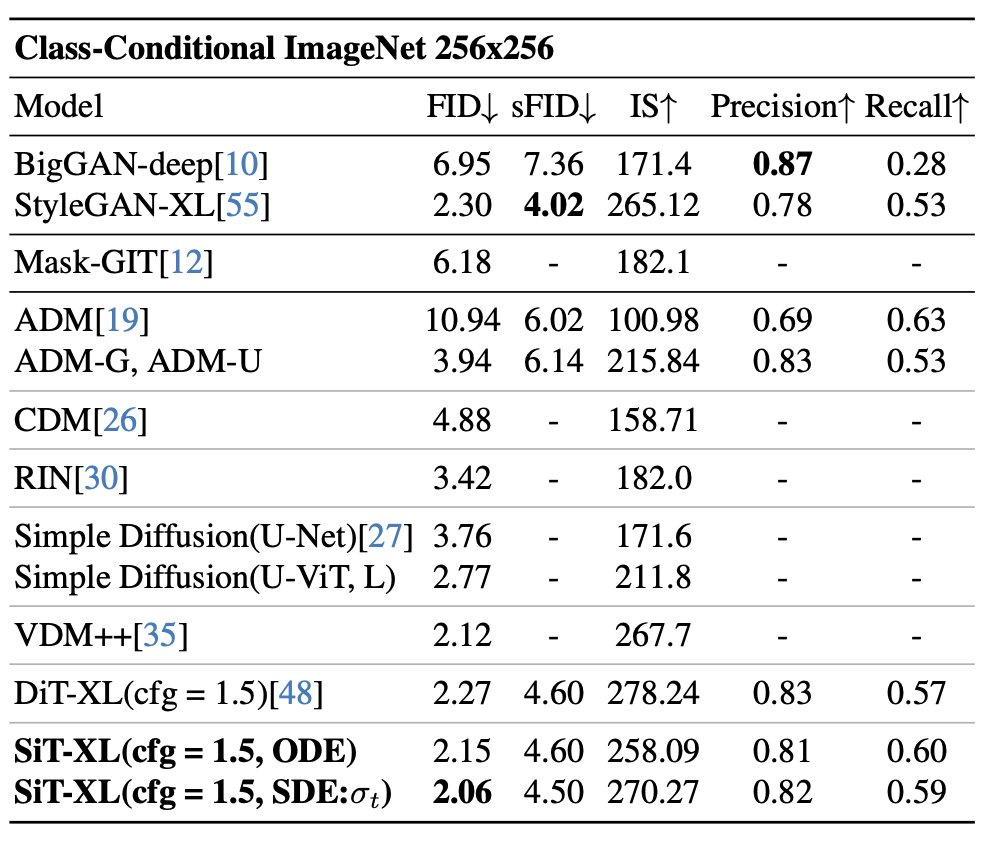
更多關於DiT 和SiT 的內容請參閱原始論文。