多模態LLM多到看不過來?先看這26個SOTA模型吧
2024.01.31

目前AI 領域的關注重心正從大型語言模型(LLM)向多模態轉移,於是乎,讓LLM 具備多模態能力的多模態大型語言模型(MM-LLM)就成了一個備受關注的研究主題。
近日,騰訊AI Lab、京都大學和穆罕默德・本・扎耶德人工智慧大學的一個研究團隊發布了一份綜述報告,全面梳理了MM-LLM 的近期進展。文中不僅總結了MM-LLM 的模型架構和訓練流程,而且還整理了26 個目前最佳的MM-LLM。如果你正在考慮研究或使用MM-LLM,不妨考慮從這份報告開始研究,找到最符合你需求的模型。

- 論文標題:MM-LLMs: Recent Advances in MultiModal Large Language Models
- 論文網址:https://arxiv.org/abs/2401.13601
報告概覽
近年來,多模態(MM)預訓練研究進展迅速,讓許多下游任務的表現不斷突破到新的邊界。但是,隨著模型和資料集規模不斷擴大,傳統多模態模型也遭遇了計算成本過高的問題,尤其是從頭開始訓練時。考慮到多模態研究位於多種模態的交叉領域,一種合乎邏輯的方法是充分利用現成的預訓練單模態基礎模型,尤其是強大的大型語言模型(LLM)。
這項策略的目標是降低多模態預訓練的計算成本並提升其效率,這樣一來就催生出了一個全新領域:MM-LLM,即多模態大型語言模型。
MM-LLM 使用LLM 提供認知功能,讓其處理各種多模態任務。 LLM 能提供多種所需能力,例如穩健的語言泛化能力、零樣本遷移能力和情境學習(ICL)。同時,其它模態的基礎模型卻能提供高品質的表徵。考慮到不同模態的基礎模型都是分開預先訓練的,因此MM-LLM 面臨的核心挑戰是如何有效地將LLM 與其它模態的模型連接起來以實現協作推理。
在這個領域內,人們關注的主要焦點是優化提升模態之間的對齊(alignment)以及讓模型與人類意圖對齊。這方面使用的主要工作流程是多模態預訓練(MM PT)+ 多模態指令微調(MM IT)。
2023 年發布的GPT-4 (Vision) 和Gemini 展現了出色的多模態理解和生成能力;由此激發了人們對MM-LLM 的研究熱情。
一開始,研究社群主要關注的是多模態內容理解和文本生成,此類模型包括(Open) Flamingo、BLIP-2、Kosmos-1、LLaVA/LLaVA-1.5、MiniGPT-4、MultiModal-GPT、VideoChat 、Video-LLaMA、IDEFICS、Fuyu-8B、Qwen-Audio。
為了創造出能同時支援多模態輸入和輸出的MM-LLM,還有一些研究工作探討了特定模態的生成,例如Kosmos-2 和MiniGPT-5 研究的是影像生成,SpeechGPT 則聚焦於語音生成。
近期人們關注的重點是模仿類似人類的任意模態到任意模態的轉換,而這或許是一條通往通用人工智慧(AGI)之路。
一些研究的目標是將LLM 與外部工具合併,以達到近似的任意到任意的多模態理解和生成;這類研究包括Visual-ChatGPT、ViperGPT、MM-REACT、HuggingGPT、AudioGPT。
反過來,為了減少級聯繫統中傳播的錯誤,也有一些研究團隊想要打造出端對端式的任意模態MM-LLM;這類研究包括NExT-GPT 和CoDi-2。
圖1 給出了MM-LLM 的時間線。

為了促進MM-LLM 的研究發展,騰訊AI Lab、京都大學和穆罕默德・本・扎耶德人工智慧大學的這個團隊整理出了這份綜述報告。機器之心整理了該報告的主幹部分,尤其是其中對26 個當前最佳(SOTA)MM-LLM 的介紹。
模型架構
這一節,團隊詳細整理了一般模型架構的五大元件,另外也會介紹每個元件的實作選擇,如圖2 所示。
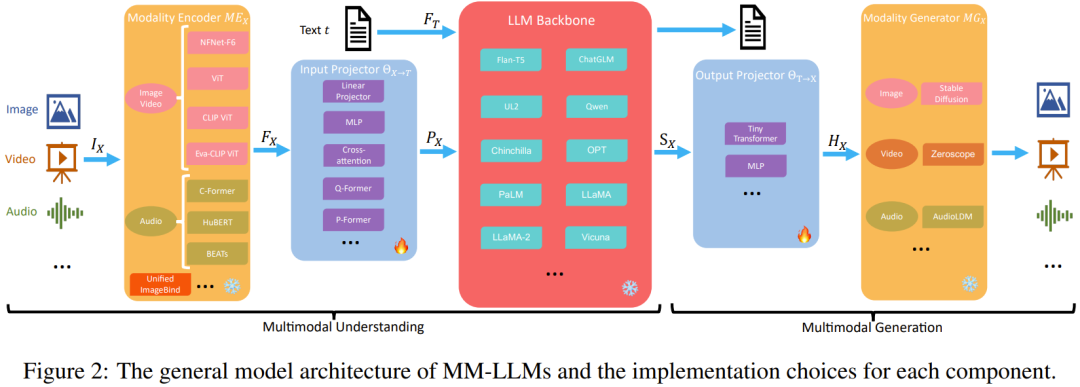
專注於多模態理解的MM-LLM 僅包含前三個組件。
在訓練階段,模態編碼器、LLM 骨幹和模態生成器通常保持在凍結狀態。其最佳化的要點是輸入和輸出投影器。由於投影機是輕量級的元件,因此相較於總參數量,MM-LLM 中可訓練參數的佔比非常小(通常約為2%)。總參數量取決於MM-LLM 中使用的核心LLM 的規模。因此,在針對各種多模態任務訓練MM-LLM 時,可以取得很高的訓練效率。
模態編碼器(Modality Encoder/ME):編碼不同模態的輸入,以獲得對應的特性。
輸入投影機(Input Projector):將已編碼的其它模態的特徵與文字特徵空間對齊。
LLM 骨幹:MM-LLM 使用LLM 作為核心智能體,因此也繼承了LLM 的一些重要特性,例如零樣本泛化、少樣本上下文學習、思維鏈(CoT)和指令遵從。 LLM 骨幹的任務是處理各種模態的表徵,其中涉及與輸入相關的語義理解、推理和決策。它的輸出包括(1) 直接的文字輸出,(2) 其它模態的訊號token(如果有的話)。這些訊號token 可用作引導生成器的指令- 是否產生多模態內容,如果是,則指定要產生的內容。
MM-LLM 常用的LLM 包括Flan-T5、ChatGLM、UL2、Qwen、Chinchilla、OPT、PaLM、LLaMA、LLaMA-2、Vicuna。
輸出投影器:將來自LLM 骨幹的信號token 表徵映射成可被後續模態生成器理解的特徵。
模態產生器:產生不同對應模態的輸出。目前的研究工作通常是使用現有的隱擴散模型(LDM),即使用Stable Diffusion 來合成影像、使用Zeroscope 來合成視訊、使用AudioLDM-2 來合成音訊。
訓練流程
MM-LLM 的訓練流程可分為兩個主要階段:MM PT(多模態預訓練)和MM IT(多模態指令微調)。
MMPT
在預訓練階段(通常是利用XText 資料集),透過優化預先定義的目標來訓練輸入和輸出投影器,使其對齊不同的模態。 (有時也會將參數高效型微調(PEFT)技術用於LLM 骨幹。)
MM資訊技術
MM IT 這種方法需要使用一組指令格式的資料集對預先訓練的MM-LLM 進行微調。透過這個微調過程,MM-LLM 可以泛化到未曾看過的任務,執行新指令,從而增強零樣本效能。
MM IT 包含監督式微調(SFT)和根據人類回饋的強化學習(RLHF),目標是與人類意圖或偏好對齊並提升MM-LLM 的互動能力。
SFT 可將預訓練階段的部分資料轉換成指令感知型的格式。
SFT 之後,RLHF 會對模型進行進一步的微調,這需要有關MM-LLM 所給反應的回饋資訊(例如由人類或AI 標註的自然語言回饋(NLF))。這個過程採用了強化學習演算法來有效整合不可微分的NLF。模型的訓練目標是根據NLF 產生對應的反應。
現有的MM-LLM 在MM PT 和MM IT 階段使用的資料集有很多,但它們都是表3 和表4 中資料集的子集。
目前最佳的MM-LLM
該團隊比較了26 個目前最佳(SOTA)MM-LLM 的架構和訓練資料集規模,如表1 所示。另外他們也簡單總結了每種模型的核心貢獻和發展趨勢。

(1) Flamingo:一系列設計用於處理交織融合的視覺資料和文字的視覺語言(VL)模型,可輸出自由形式的文字。
(2) BLIP-2:提出了一個能更有效率地利用資源的框架,其中使用了輕量級的Q-Former 來連接不同模態,也使用了凍結的LLM。使用LLM,可透過自然語言prompt 引導BLIP-2 執行零樣本影像到文字產生。
(3) LLaVA:率先將指令微調技術遷移到多模態領域。為了解決資料稀疏性問題,LLaVA 使用ChatGPT/GPT-4 創建了一個全新的開源多模態指令遵從資料集和一個多模態指令遵從基準LLaVA-Bench。
(4) MiniGPT-4:提出了一種經過精簡的方法,其中僅訓練一個線性層來對齊預訓練視覺編碼器與LLM。這種高效方法展現出的能力能媲美GPT-4。
(5) mPLUG-Owl:提出了一種全新的用於MM-LLM 的模組化訓練框架,並整合了視覺上下文。為了評估不同模型在多模態任務上的效能,該框架還包含一個指示性的評估資料集OwlEval。
(6) X-LLM:擴展到了包括音訊在內的多個模態,展現出了強大的可擴展性。利用了QFormer 的語言可遷移能力,X-LLM 成功在漢藏語系漢語語境中得到了應用。
(7) VideoChat:開創了一種高效的以聊天為中心的MM-LLM 可用於進行視訊理解對話。這項研究為該領域的未來研究設定了標準,並為學術界和產業界提供了協議。
(8) InstructBLIP:此模型是基於BLIP-2 模型訓練所得到的,在MM IT 階段僅更新了Q-Former。透過引入指令感知型的視覺特徵提取和對應的指令,該模型可以提取靈活且多樣化的特徵。
(9) PandaGPT 是一種開創性的通用模型,有能力理解6 種不同模態的指令並遵照行事:文字、圖像/ 視訊、音訊、熱量、深度和慣性測量單位。
(10) PaLIX:其訓練過程使用了混合的視覺語言目標和單模態目標,包括前綴補全和遮罩token 補全。研究表明,這種方法可以有效用於下游任務,並在微調設定中到達了帕累托邊界。
(11) Video-LLaMA:提出了一種多分支跨模態預訓練框架,讓LLM 可以在與人類對話的同時處理給定視訊的視覺和音訊內容。該框架對齊了視覺與語言以及音訊與語言。
(12) Video-ChatGPT:此模型是專門針對視訊對話任務設計的,可以透過整合時空視覺表徵來產生有關影片的討論。
(13) Shikra:提出了一種簡單但統一的預訓練MM-LLM,並且專門針對參考對話(Referential Dialogue)任務進行了調整。參考對話任務涉及討論影像中的區域和目標。此模型展現了值得稱道的泛化能力,可有效處理未曾見過的情況。
(14) DLP:提出了用於預測理想prompt 的P-Former,並在一個單模態語句的資料集上完成了訓練。這表明單模態訓練可以用於增強多模態學習。
(15) BuboGPT:為了全面理解多模態內容,模型在建構時學習了一個共享式語意空間。其探索了圖像、文字和音訊等不同模態之間的細粒度關係。
(16) ChatSpot:提出了一種簡單卻有效的方法,可為MM-LLM 精細化調整精確引用指令,從而促進細粒度的交互。透過整合精確引用指令(由影像級和區域級指令構成),多粒度視覺語言任務描述得以增強。
(17) Qwen-VL:一種支援英語和漢語的多語言MM-LLM。 Qwen-VL 還允許在訓練階段輸入多張影像,這能提高其理解視覺上下文的能力。
(18) NExT-GPT:這是一種端對端、通用且支援任意模態到任意模態的MM-LLM,支援自由輸入和輸出影像、視訊、音訊和文字。其採用了一種輕量的對齊策略- 在編碼階段使用以LLM 為中心的對齊,在解碼階段使用指令遵從對齊。
(19) MiniGPT-5:這種MM-LLM 整合了轉化成生成式voken 的技術,並整合了Stable Diffusion。它擅長執行交織融合了視覺語言輸出的多模態生成任務。其在訓練階段加入了無分類器指導,以提升生成品質。
(20) LLaVA-1.5:模型基於LLaVA 框架並進行了簡單的修改,包括使用一種MLP 投影,引入針對學術任務調整過的VQA 數據,以及使用響應格式簡單的prompt。這些調整讓模型的多模態理解能力提升了。
(21) MiniGPT-v2:這種MM-LLM 的設計目標是作為多樣化視覺語言多任務學習的一個統一介面。為了打造出能熟練處理多種視覺語言任務的單一模型,每個任務的訓練和推理階段都整合了標識符(identifier)。這有助於明確的任務區分,並最終提升學習效率。
(22) CogVLM:一種開源MM-LLM,其透過一種用在註意力和前饋層中的可訓練視覺專家模組搭建了不同模態之間的橋樑。這能讓多模態特徵深度融合,同時不會損害在下游NLP 任務上的表現。
(23) DRESS:提出了一種使用自然語言回饋來提升與人類偏好的對齊效果的方法。 DRESS 擴展了條件式強化學習演算法以整合不可微分的自然語言回饋,並以此訓練模型根據回饋產生適當的反應。
(24) X-InstructBLIP:提出了一種使用指令感知型表徵的跨模態框架,足以擴展用於助力LLM 處理跨多模態(包括影像/ 視訊、音訊和3D)的多樣化任務。值得注意的是,它不需要特定模態的預訓練就能做到這一點。
(25) CoDi-2:這是一種多模態生成模型,可以出色地執行多模態融合的指令遵從、上下文生成以及多輪對話形式的用戶- 模型交互。它是對CoDi 的增強,使其可以處理複雜的模態交織的輸入和指令,以自回歸的方式產生隱含特徵。
(26) VILA:此模型在視覺任務上的表現出色,並能在維持純文字能力的同時表現出卓越的推理能力。 VILA 之所以性能優異,是因為其充分利用了LLM 的學習能力,使用了圖像- 文本對的融合屬性並實現了精細的文本數據重新混合。
當前MM-LLM 的發展趨勢:
(1) 從專注於多模態理解向特定模態生成發展,並進一步向任意模態到任意模態轉換發展(例如MiniGPT-4 → MiniGPT-5 → NExT-GPT)。
(2) 從MM PT 到SFT 再到RLHF,訓練流程持續不斷優化,力求更好地與人類意圖對齊並增強模型的對話互動能力(例如BLIP-2 → InstructBLIP → DRESS)。
(3) 擁抱多樣化的模態擴展(如BLIP-2 → X-LLM 和InstructBLIP → X-InstructBLIP)。
(4) 整合更高品質的訓練資料集(如LLaVA → LLaVA-1.5)。
(5) 採用更有效率的模型架構,從BLIP-2 和DLP 複雜的Q-Former 和P-Former 輸入投射器模組到VILA 中更簡單卻有效的線性投影機。
基準和性能
為了全面比較各模型的性能,團隊編制了一個表格,其中包含從多篇論文中收集的主要MM-LLM 的數據,涉及18 個視覺語言基準,見表2。

未來方向
團隊最後討論了MM-LLM 領域比較有前景的一些未來研究方向:
- 更強大的模型:增強MM-LLM 的能力,其中主要透過這四個關鍵途徑:擴展模態、實現LLM 多樣化、提升多模態指令微調的資料集品質、增強多模態生成能力。
- 難度更高的基準
- 移動/ 輕量級部署
- 具身智能
- 持續指令微調