Are there too many multi-modal LLMs to look at? Let’s take a look at these 26 SOTA models first
2024.01.31

he current focus in the AI field is shifting from large language models (LLM) to multimodality. Therefore, the multimodal large language model (MM-LLM) that allows LLM to have multimodal capabilities has become a hot topic. Research Topics.
Recently, a research team from Tencent AI Lab, Kyoto University and Mohamed Bin Zayed University for Artificial Intelligence released a review report, comprehensively sorting out the recent progress of MM-LLM. The article not only summarizes the model architecture and training process of MM-LLM, but also sorts out the 26 current best MM-LLM. If you are considering studying or using MM-LLM, you may consider starting with this report to find the model that best meets your needs.

- Paper title: MM-LLMs: Recent Advances in MultiModal Large Language Models
- Paper address: https://arxiv.org/abs/2401.13601
Report overview
In recent years, multi-modal (MM) pre-training research has progressed rapidly, allowing the performance of many downstream tasks to continue to break through to new boundaries. However, as model and dataset sizes continue to grow, traditional multimodal models also suffer from excessive computational costs, especially when trained from scratch. Considering that multimodal research lies at the intersection of multiple modalities, a logical approach is to make full use of readily available pre-trained single-modal base models, especially powerful large language models (LLMs).
The goal of this strategy is to reduce the computational cost and improve the efficiency of multi-modal pre-training, which has given rise to a new field: MM-LLM, or multi-modal large language model.
MM-LLM uses LLM to provide cognitive functions and allow it to handle various multi-modal tasks. LLM can provide a variety of required capabilities, such as robust language generalization, zero-shot transfer, and contextual learning (ICL). At the same time, the underlying models of other modalities provide high-quality representations. Considering that the basic models of different modalities are pre-trained separately, the core challenge facing MM-LLM is how to effectively connect LLM with models of other modalities to achieve collaborative reasoning.
In this area, the main focus is on optimizing alignment between modalities and aligning models with human intent. The main workflow used in this regard is multi-modal pre-training (MM PT) + multi-modal instruction fine-tuning (MM IT).
GPT-4 (Vision) and Gemini, released in 2023, have demonstrated excellent multi-modal understanding and generation capabilities; thus stimulating research enthusiasm for MM-LLM.
At the beginning, the research community mainly focused on multi-modal content understanding and text generation. Such models include (Open) Flamingo, BLIP-2, Kosmos-1, LLaVA/LLaVA-1.5, MiniGPT-4, MultiModal-GPT, VideoChat , Video-LLaMA, IDEFICS, Fuyu-8B, Qwen-Audio.
In order to create MM-LLM that can support multi-modal input and output at the same time, some research works have explored the generation of specific modalities. For example, Kosmos-2 and MiniGPT-5 study image generation, and SpeechGPT focuses on speech generation. .
Recent focus has been on imitating human-like arbitrary-to-any-modal transitions, which may be a path toward artificial general intelligence (AGI).
Some research aims to merge LLM with external tools to achieve approximate any-to-any multi-modal understanding and generation; such research includes Visual-ChatGPT, ViperGPT, MM-REACT, HuggingGPT, AudioGPT.
Conversely, in order to reduce errors propagated in cascade systems, some research teams want to create end-to-end arbitrary mode MM-LLM; such research includes NExT-GPT and CoDi-2.
Figure 1 gives the timeline of MM-LLM.

In order to promote the research and development of MM-LLM, the team from Tencent AI Lab, Kyoto University and Mohamed Bin Zayed Artificial Intelligence University compiled this review report. Machine Heart has compiled the main part of the report, especially the introduction of the 26 current best (SOTA) MM-LLMs.
Model architecture
In this section, the team details the five major components of the general model architecture, and also introduces the implementation options for each component, as shown in Figure 2.
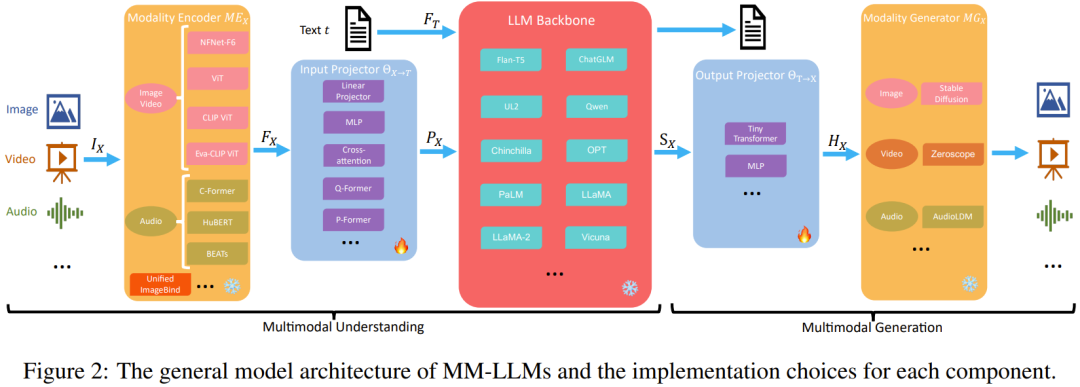
MM-LLM, which focuses on multimodal understanding, only contains the first three components.
During the training phase, the modal encoder, LLM backbone, and modal generator are usually kept in a frozen state. The key points of its optimization are the input and output projectors. Since the projector is a lightweight component, the proportion of trainable parameters in MM-LLM is very small (usually around 2%) compared to the total number of parameters. The total parameter amount depends on the size of the core LLM used in MM-LLM. Therefore, high training efficiency can be achieved when training MM-LLM for various multi-modal tasks.
Modality Encoder/ME: Encodes inputs of different modalities to obtain corresponding features.
Input Projector: Aligns the encoded features of other modalities with the text feature space.
LLM backbone: MM-LLM uses LLM as the core agent, and therefore inherits some important features of LLM, such as zero-shot generalization, few-shot context learning, chain of thought (CoT) and instruction compliance. The LLM backbone is tasked with processing representations of various modalities, which involve semantic understanding, reasoning, and decision-making related to the input. Its output includes (1) direct text output, (2) other modal signal tokens (if any). These signal tokens can be used as instructions to guide the generator - whether to generate multimodal content, and if so, what content to generate.
Commonly used LLMs in MM-LLM include Flan-T5, ChatGLM, UL2, Qwen, Chinchilla, OPT, PaLM, LLaMA, LLaMA-2, and Vicuna.
Output projector: maps the signal token representation from the LLM backbone into features that can be understood by subsequent modal generators.
Modal Generator: Generates output for different corresponding modalities. Current research work usually uses existing latent diffusion models (LDM), that is, using Stable Diffusion to synthesize images, using Zeroscope to synthesize videos, and using AudioLDM-2 to synthesize audio.
Training process
The training process of MM-LLM can be divided into two main stages: MM PT (multi-modal pre-training) and MM IT (multi-modal instruction fine-tuning).
MM PT
In the pre-training phase (usually leveraging the XText dataset), the input and output projectors are trained to align to different modalities by optimizing predefined targets. (Parameter-efficient fine-tuning (PEFT) techniques are also sometimes used for LLM backbones.)
MM IT
MM IT This method requires fine-tuning a pre-trained MM-LLM using a set of instruction-formatted data sets. Through this fine-tuning process, MM-LLM can generalize to unseen tasks and execute new instructions, thereby enhancing zero-shot performance.
MM IT includes supervised fine-tuning (SFT) and reinforcement learning based on human feedback (RLHF), with the goal of aligning with human intentions or preferences and improving the interactive capabilities of MM-LLM.
SFT can convert part of the data from the pre-training stage into an instruction-aware format.
After SFT, RLHF further fine-tunes the model, which requires feedback information about the responses given by MM-LLM (such as natural language feedback (NLF) annotated by humans or AI). This process employs a reinforcement learning algorithm to efficiently integrate non-differentiable NLF. The training goal of the model is to generate the corresponding response based on NLF.
There are many data sets used by existing MM-LLM in the MM PT and MM IT stages, but they are all subsets of the data sets in Table 3 and Table 4.
The best current MM-LLM
The team compared the architectures and training data set sizes of 26 state-of-the-art (SOTA) MM-LLMs, as shown in Table 1. In addition, they also briefly summarized the core contributions and development trends of each model.

(1) Flamingo: A series of visual language (VL) models designed to process intertwined visual data and text, and can output free-form text.
(2) BLIP-2: Proposed a framework that can utilize resources more efficiently, using lightweight Q-Former to connect different modalities, and also using frozen LLM. Using LLM, BLIP-2 can be guided through natural language prompts to perform zero-shot image-to-text generation.
(3) LLaVA: Take the lead in migrating instruction fine-tuning technology to the multi-modal field. To solve the problem of data sparsity, LLaVA created a new open source multi-modal compliance dataset and a multi-modal compliance benchmark LLaVA-Bench using ChatGPT/GPT-4.
(4) MiniGPT-4: A streamlined approach is proposed in which only one linear layer is trained to align the pretrained visual encoder with the LLM. This efficient method demonstrates capabilities comparable to GPT-4.
(5) mPLUG-Owl: A new modular training framework for MM-LLM is proposed and integrates visual context. To evaluate the performance of different models on multi-modal tasks, the framework also includes an indicative evaluation dataset OwlEval.
(6) X-LLM: Expanded to multiple modalities including audio, showing strong scalability. Taking advantage of the language transferability capability of QFormer, X-LLM has been successfully applied in the Chinese context of the Sino-Tibetan language family.
(7) VideoChat: Pioneering an efficient chat-centric MM-LLM for video understanding conversations. This study sets standards for future research in this area and provides protocols for academia and industry.
(8) InstructBLIP: This model is trained based on the BLIP-2 model, and only the Q-Former is updated in the MM IT stage. By introducing instruction-aware visual feature extraction and corresponding instructions, the model can extract flexible and diverse features.
(9) PandaGPT is a groundbreaking general-purpose model with the ability to understand and act on instructions in 6 different modalities: text, image/video, audio, thermal, depth, and inertial measurement units.
(10) PaLIX: Its training process uses a mixture of visual language objectives and single-modality objectives, including prefix completion and mask token completion. Research shows that this approach can be used effectively on downstream tasks and reaches the Pareto frontier in a fine-tuned setting.
(11) Video-LLaMA: A multi-branch cross-modal pre-training framework is proposed to allow LLM to process the visual and audio content of a given video while conversing with humans. The framework aligns vision and language as well as audio and language.
(12) Video-ChatGPT: This model is specially designed for video conversation tasks and can generate discussions about videos by integrating spatiotemporal visual representations.
(13) Shikra: A simple but unified pre-trained MM-LLM is proposed and specifically tuned for the Referential Dialogue task. The reference dialogue task involves discussing regions and objects in an image. The model exhibits commendable generalization capabilities and can effectively handle unseen situations.
(14) DLP: P-Former is proposed for predicting ideal prompts, and training is completed on a single-modal sentence data set. This shows that single-modal training can be used to enhance multi-modal learning.
(15) BuboGPT: In order to comprehensively understand multi-modal content, this model learns a shared semantic space when building. It explores fine-grained relationships between different modalities such as images, text, and audio.
(16) ChatSpot: A simple yet effective method is proposed to fine-tune precise reference instructions for MM-LLM, thereby promoting fine-grained interactions. Multi-granularity visual language task descriptions are enhanced by integrating precise reference instructions (consisting of image-level and region-level instructions).
(17) Qwen-VL: A multilingual MM-LLM supporting English and Chinese. Qwen-VL also allows multiple images to be input during the training phase, which improves its ability to understand visual context.
(18) NExT-GPT: This is an end-to-end, universal and any-modality-to-any-modality MM-LLM that supports free input and output of images, videos, audio, and text. It adopts a lightweight alignment strategy - using LLM-centered alignment in the encoding stage and instruction compliance alignment in the decoding stage.
(19) MiniGPT-5: This MM-LLM integrates the technology of converting into generative tokens and integrates Stable Diffusion. It is good at performing multi-modal generation tasks that interweave visual language output. It adds classifier-free guidance during the training phase to improve the quality of generation.
(20) LLaVA-1.5: This model is based on the LLaVA framework with simple modifications, including using an MLP projection, introducing VQA data adjusted for academic tasks, and using prompts with a simple response format. These adjustments improve the model’s multimodal understanding capabilities.
(21) MiniGPT-v2: This MM-LLM is designed to serve as a unified interface for multi-task learning of diverse visual languages. To create a single model that can handle multiple visual language tasks proficiently, identifiers are integrated into the training and inference stages of each task. This facilitates clear task differentiation and ultimately improves learning efficiency.
(22) CogVLM: An open source MM-LLM that bridges different modalities through a trainable visual expert module used in attention and feed-forward layers. This enables deep fusion of multi-modal features without compromising performance on downstream NLP tasks.
(23) DRESS: A method is proposed to use natural language feedback to improve alignment with human preferences. DRESS extends conditional reinforcement learning algorithms to incorporate non-differentiable natural language feedback and thereby train the model to generate appropriate responses based on the feedback.
(24) X-InstructBLIP: A cross-modal framework using instruction-aware representations is proposed, which is scalable enough to assist LLM in processing diverse tasks across multiple modalities (including image/video, audio, and 3D). Notably, it does this without requiring modality-specific pre-training.
(25) CoDi-2: This is a multimodal generative model that can excellently perform multimodal fusion of command compliance, context generation, and user-model interaction in the form of multi-turn dialogues. It is an enhancement to CoDi that enables it to handle complex modal interleaved inputs and instructions, generating latent features in an autoregressive manner.
(26) VILA: This model performs well on visual tasks and exhibits superior reasoning capabilities while maintaining text-only capabilities. The reason why VILA performs well is that it fully exploits the learning ability of LLM, uses the fusion properties of image-text pairs and achieves fine text data remixing.
Current development trends of MM-LLM:
(1) Develop from focusing on multi-modal understanding to specific modality generation, and further develop to any mode to any mode conversion (such as MiniGPT-4 → MiniGPT-5 → NExT-GPT).
(2) From MM PT to SFT to RLHF, the training process continues to be optimized, striving to better align with human intentions and enhance the conversational interaction capabilities of the model (such as BLIP-2 → InstructBLIP → DRESS).
(3) Embrace diverse modal extensions (such as BLIP-2 → X-LLM and InstructBLIP → X-InstructBLIP).
(4) Integrate higher quality training data sets (such as LLaVA → LLaVA-1.5).
(5) Adopt a more efficient model architecture, from the complex Q-Former and P-Former input projector modules in BLIP-2 and DLP to the simpler but effective linear projector in VILA.
Benchmarks and performance
In order to comprehensively compare the performance of each model, the team compiled a table containing data from the main MM-LLM collected from multiple papers, involving 18 visual language benchmarks, see Table 2.

future direction
The team finally discussed some promising future research directions in the MM-LLM field:
- More powerful model: Enhance the capabilities of MM-LLM, mainly through these four key ways: expanding modalities, diversifying LLM, improving the quality of data sets for multi-modal instruction fine-tuning, and enhancing multi-modal generation capabilities.
- A more difficult benchmark
- Mobile/lightweight deployment
- embodied intelligence
- Continuous instruction fine-tuning