The latest research from Google MIT proves that it is not difficult to obtain high-quality data, and large models are the way back.
2024.01.14

Obtaining high-quality data has become a major bottleneck in current large model training.
A few days ago, OpenAI was sued by the New York Times and demanded billions of dollars in compensation. The complaint lists multiple evidence of plagiarism by GPT-4.
The New York Times even called for the destruction of almost all large models such as GPT.

Many big names in the AI industry have long believed that “synthetic data” may be the best solution to this problem.

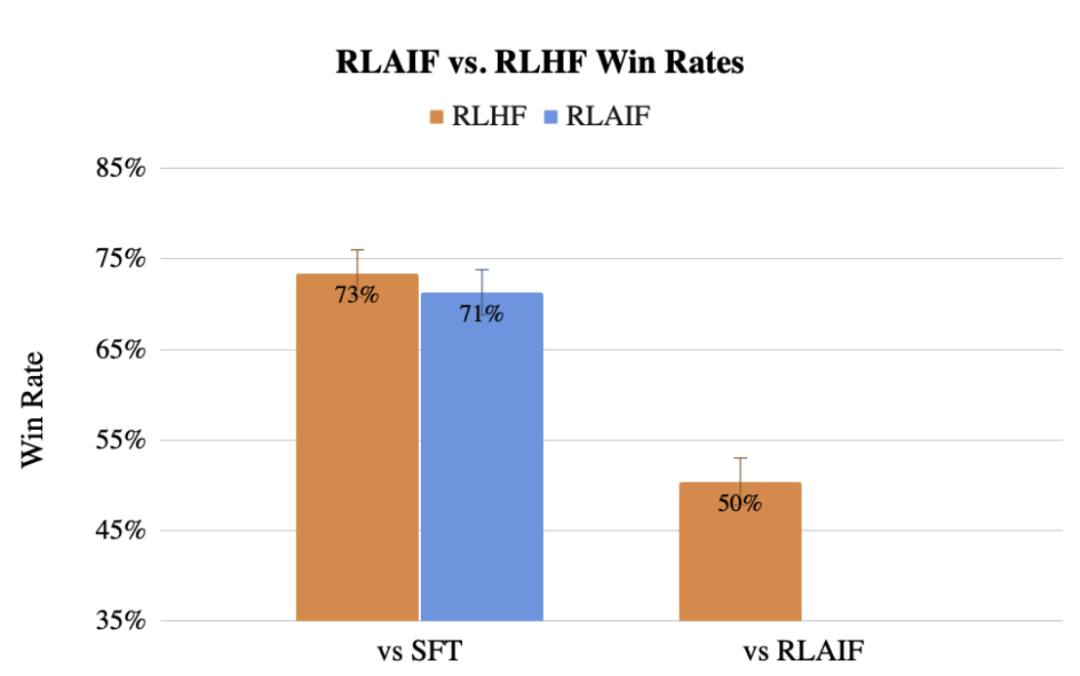
Previously, the Google team also proposed RLAIF, a method that uses LLM to replace human labeling preferences, and the effect is not even inferior to humans.
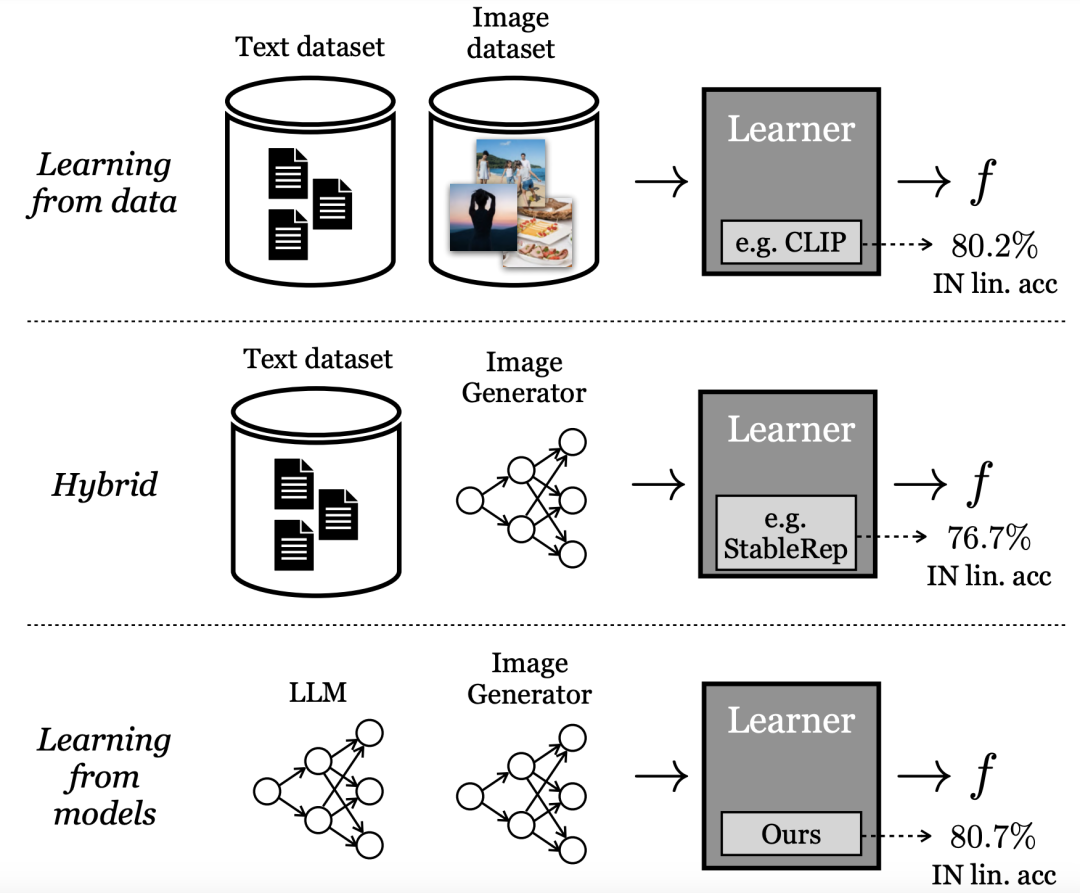
Now, researchers at Google and MIT have discovered that learning from large models can lead to representations of the best models trained using real data.
This latest method, called SynCLR, is a method of learning virtual representations entirely from synthetic images and synthetic descriptions, without any real data.

Paper address: https://arxiv.org/abs/2312.17742
Experimental results show that the representation learned through the SynCLR method can be as good as the transmission effect of OpenAI's CLIP on ImageNet.
Learning from generative models
Currently the best performing "visual representation" learning methods rely on large-scale real-world data sets. However, there are many difficulties in collecting real data.
In order to reduce the cost of collecting data, the researchers in this article asked a question:
Is synthetic data sampled from off-the-shelf generative models a viable path towards curating datasets at scale to train state-of-the-art visual representations?
Rather than learning directly from data, Google researchers call this model "learning from models." As a data source for building large-scale training sets, models have several advantages:
- Provides new control methods for data management through its latent variables, conditional variables and hyperparameters.
- Models are also easier to share and store (because models are easier to compress than data), and can produce an unlimited number of data samples.
A growing body of literature examines these properties and other advantages and disadvantages of generative models as a data source for training downstream models.
Some of these methods adopt a hybrid model, i.e., mix real and synthetic datasets, or require one real dataset to generate another synthetic dataset.
Other methods attempt to learn representations from purely “synthetic data” but lag far behind the best performing models.
In the paper, the latest method proposed by the researchers uses generative models to redefine the granularity of visualization classes.
As shown in Figure 2, four images were generated using 2 hints: "A golden retriever wearing sunglasses and a beach hat riding a bicycle" and "A cute golden retriever sitting in a house made of sushi".
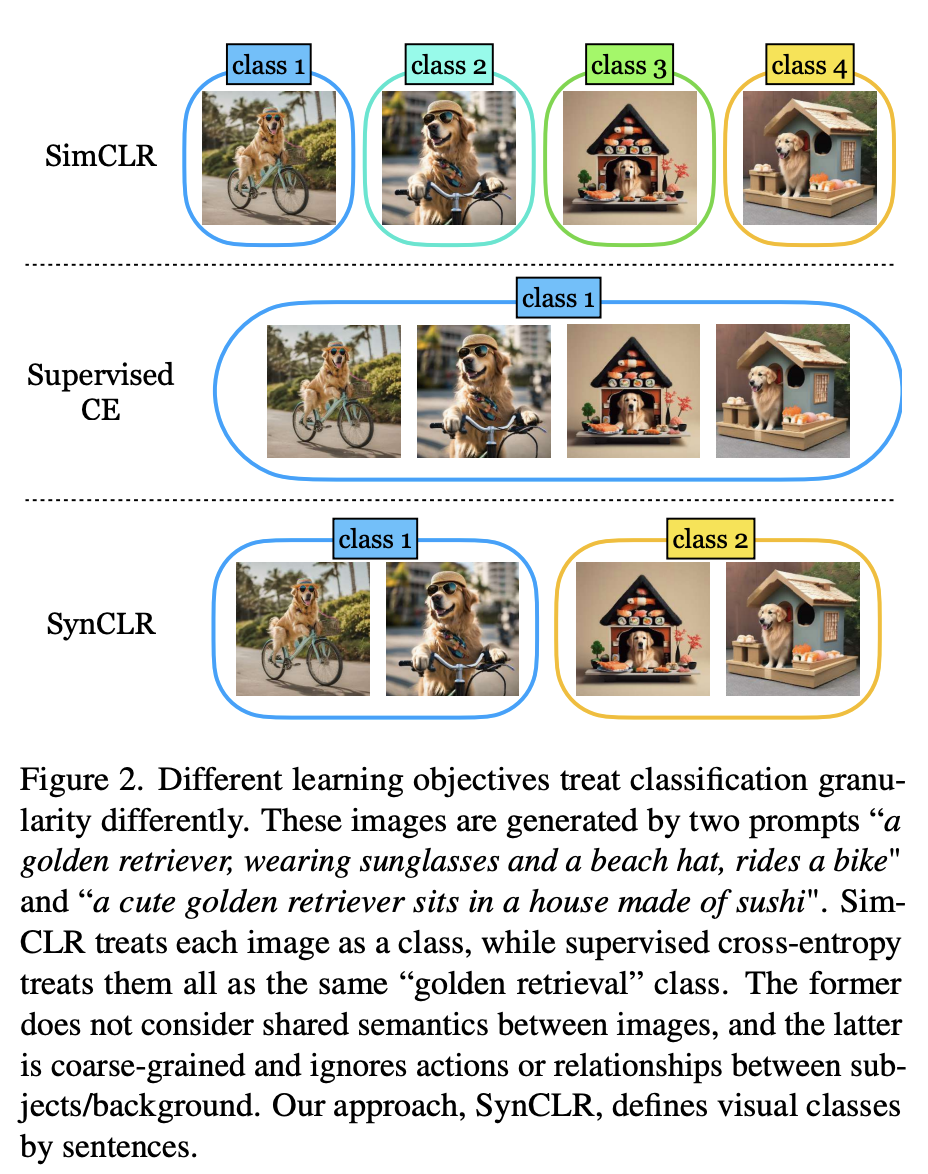
Traditional self-supervised methods (such as Sim-CLR) treat these images as different classes and the embeddings of different images are separated without explicitly considering the shared semantics between images.
At the other extreme, supervised learning methods (i.e., SupCE) treat all these images as a single class (such as “golden retriever”). This ignores semantic nuances in the images, such as a dog riding a bicycle in one pair of images and a dog sitting in a sushi house in another.
In contrast, the SynCLR approach treats descriptions as classes, i.e. one visual class per description.
This way, we can group the images according to the two concepts "riding a bicycle" and "sitting in a sushi restaurant."
This granularity is difficult to mine in real data because collecting multiple images by a given description is non-trivial, especially when the number of descriptions increases.
However, text-to-image diffusion models fundamentally have this capability.
By simply conditioning on the same description and using different noise inputs, text-to-image diffusion models can generate different images that match the same description.
Specifically, the authors study the problem of learning visual encoders without real image or text data.
State-of-the-art methods rely on the utilization of 3 key resources: a language generative model (g1), a text-to-image generative model (g2), and a curated list of visual concepts (c).
Pre-processing consists of three steps:
(1) Use (g1) to synthesize a comprehensive set of image descriptions T that cover various visual concepts in C;
(2) For each title in T, use (g2) to generate multiple images, ultimately generating an extensive synthetic image dataset X;
(3) Train on X to obtain the visual representation encoder f.
Then, llama-27b and Stable Diffusion 1.5 are used as (g1) and (g2) respectively because of their fast inference speed.
Synthetic description
In order to leverage the power of powerful text-to-image models to generate large training image datasets, a collection of descriptions that not only accurately describe images but also exhibits diversity to encompass a wide range of visual concepts is first needed.
In this regard, the authors developed a scalable method to create such a large set of descriptions, leveraging the contextual learning capabilities of large models.
Three examples of synthetic templates are shown below.

The following is a context description generated using Llama-2. The researchers randomly sampled three context examples in each inference run.
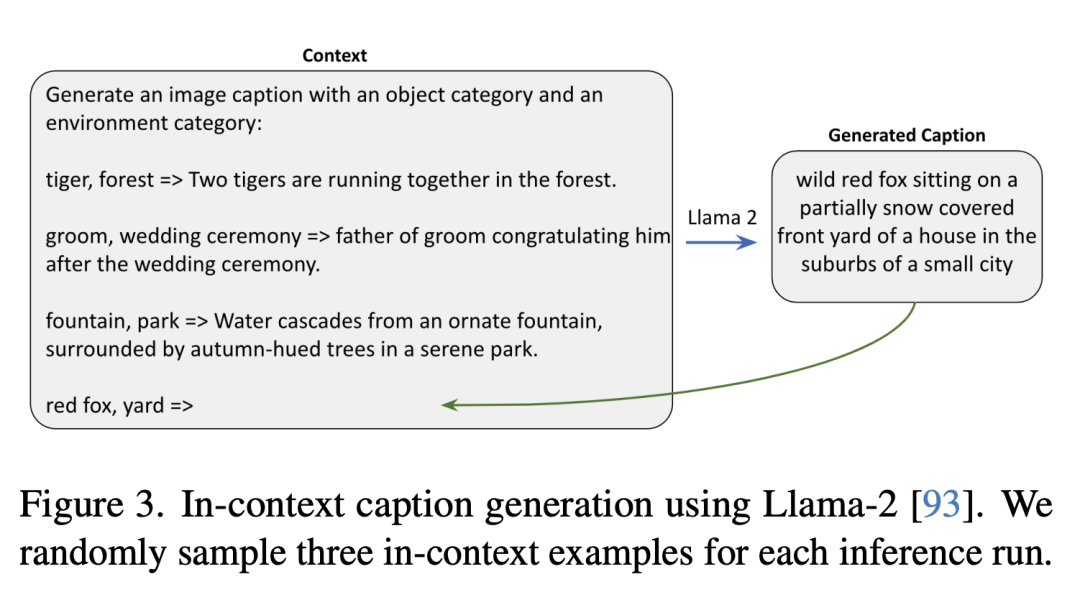
composite image
For each text description, the researchers started the back-diffusion process with different random noise, resulting in various images.
In this process, the classifier-free bootstrapping (CFG) ratio is a key factor.
The higher the CFG scale, the better the quality of the samples and the consistency between text and images, while the lower the scale, the greater the diversity of the samples and the closer they are to the original conditional distribution of the image based on the given text.

representation learning
In the paper, the representation learning method is based on StableRep.
The key component of the method proposed by the authors is the multi-positive contrast learning loss, which works by aligning (in embedding space) images generated from the same description.
In addition, various techniques from other self-supervised learning methods were also combined in the study.
Comparable to OpenAI’s CLIP
For the experimental evaluation, the researchers first conducted ablation studies to evaluate the effectiveness of various designs and modules within the pipeline, and then continued to expand the amount of synthetic data.
The figure below is a comparison of different description synthesis strategies.
The researchers report the ImageNet linear evaluation accuracy and average accuracy on nine fine-grained datasets. Each item here includes 10 million descriptions and 4 pictures per description.
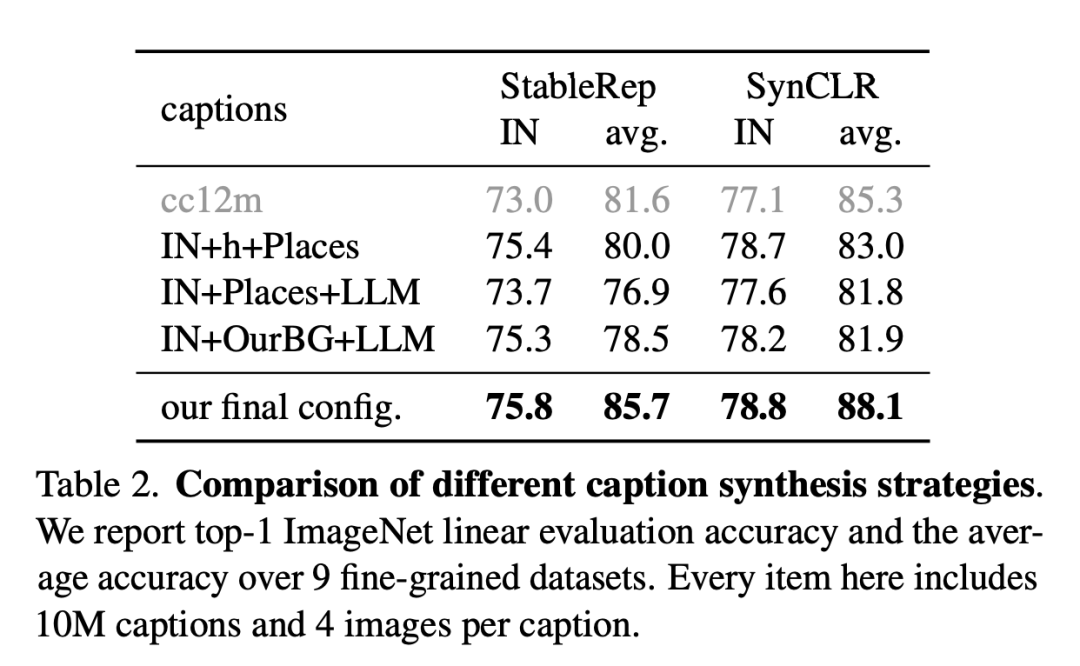
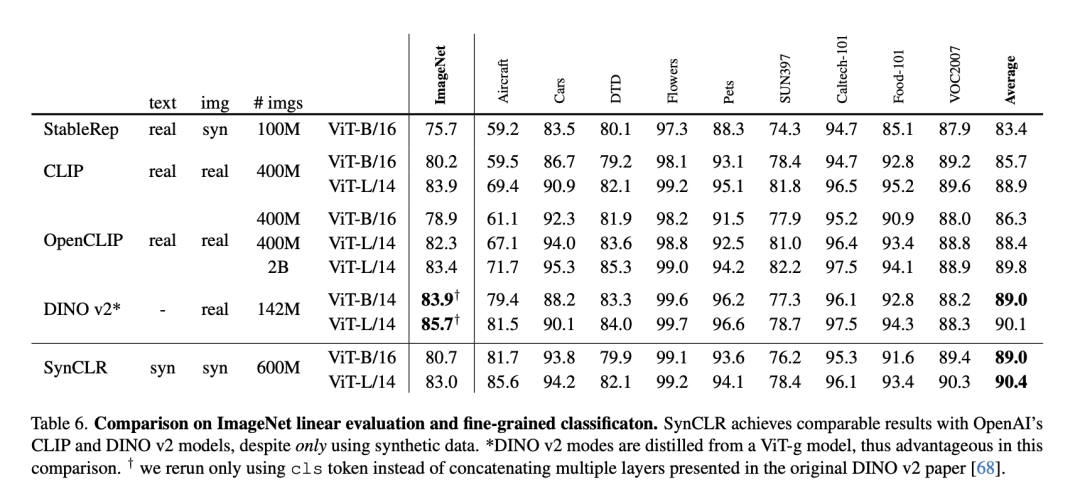
The table below compares ImageNet linear evaluation to fine-grained classification.
Despite using only synthetic data, SynCLR achieved comparable results to OpenAI’s CLIP and DINO v2 models.
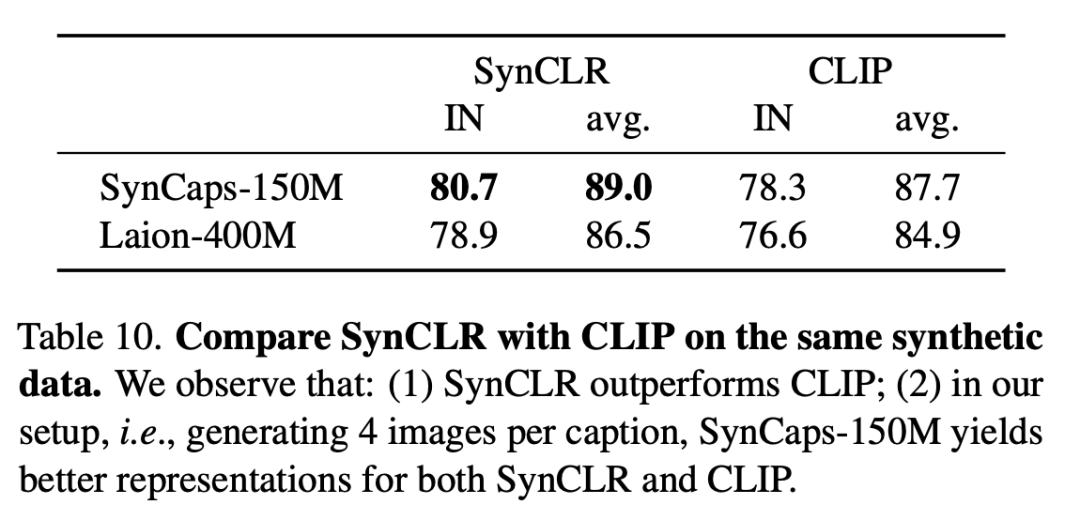
The following table compares SynCLR and CLIP on the same synthetic data. It can be seen that SynCLR is significantly better than CLIP.
Specifically set to generate 4 images per title, SynCaps-150M provides better representation for SynCLR and CLIP.
The PCA visualization is as follows. Following DINO v2, the researchers calculated PCA between patches of the same set of images and colored them based on their first 3 components.
Compared with DINO v2, SynCLR is more accurate for drawings of cars and airplanes, but slightly less accurate for drawings that can be drawn.

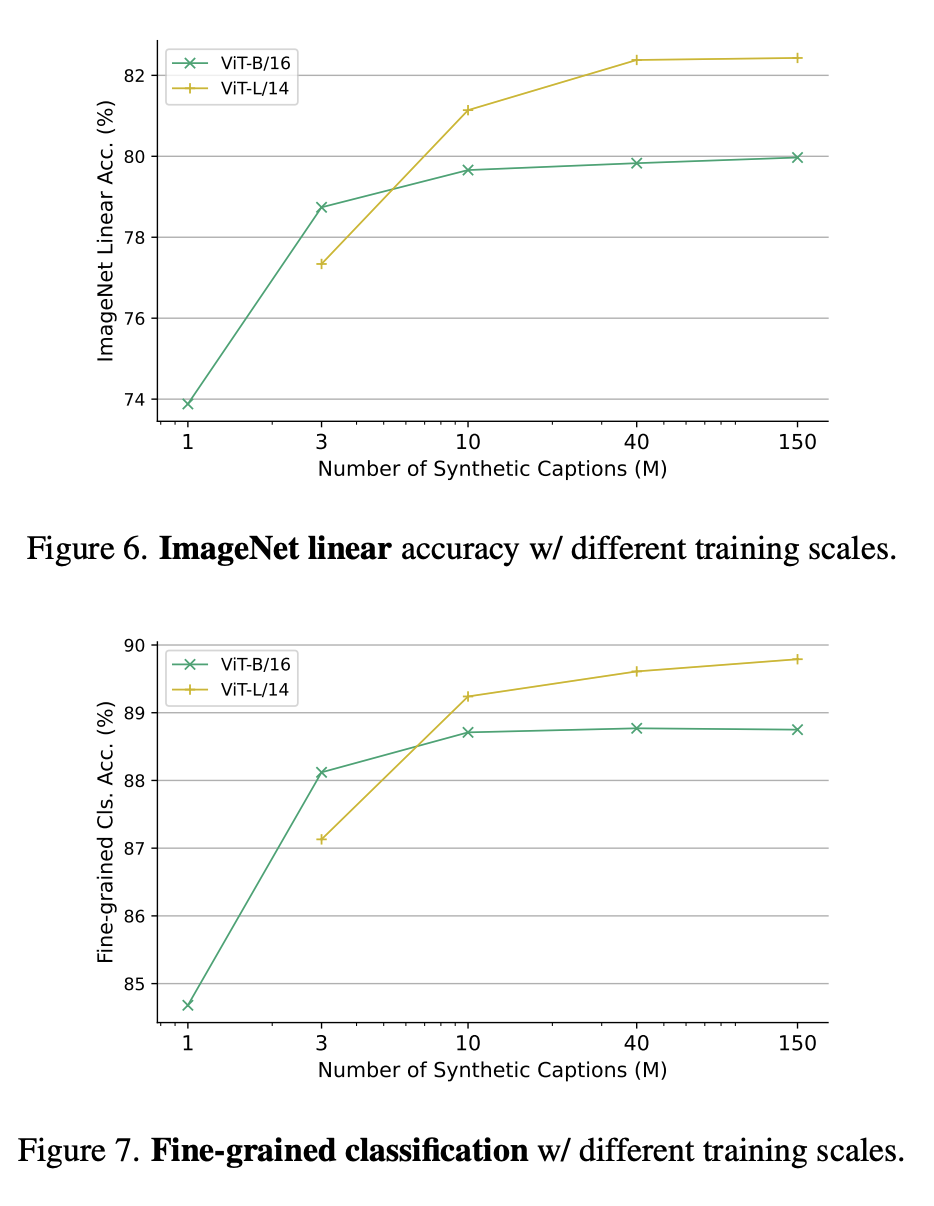
Figures 6 and 7 respectively show the linear accuracy of ImageNet under different training scales and the fine classification under different training parameter scales.
Why learn from generative models?
One compelling reason is that generative models can operate on hundreds of data sets simultaneously, providing a convenient and efficient way to curate training data.
In summary, the latest paper investigates a new paradigm for visual representation learning - learning from generative models.
Without using any real data, SynCLR learns visual representations that are comparable to those learned by state-of-the-art general-purpose visual representation learners.