面試被問到TCP的可靠性是如何保證的?
2023.10.18

面試被問到TCP的可靠性是如何保證的?
我們知道TCP是可靠的,如果保證這個機制的可靠性還需要一些其他輔助,TCP的可靠性保證包括:重送機制,滑動窗口,流量控制,擁塞控制等。
我們知道TCP是可靠的,我們前面一篇文章講解了三次握手和四次揮手之後進行數據傳輸,它們是建立在序號機制和確認應答機制的基礎之上,如果保證這個機制的可靠性還需要一些其他輔助,TCP的可靠性保證包括:重傳機制,滑動窗口,流量控制,擁塞控制等。
一、重傳機制
tcp的可靠性依賴於序號機制和確認應答機制,即一端發送資料給另一端,另一端都會回復ack包,這樣才保證這條資料發送成功,而在這個過程中會有兩種可能發生:
- 一種是封包未到達接收端,原因是資料遺失或延時了;
- 一種是ack包未到達發送端,原因也是遺失或延遲了。
前者資料未到達接收端,後者資料已到達接收端,只是回覆的ack包遺失了,未到達傳送端。
tcp採用重傳機制解決丟包和重複發送問題,tcp中重傳包括超時重傳,快速重傳,sack和d-sack。
1.超時重傳
顧名思義就是超過一定時間未收到回覆就重新發送數據,這裡比較難以確定是超時重傳的時間RTO,這個時間太大和太小都不合適,應該是比數據包一個來回的時間RTT多一點才合理,但是資料包一個來回的時間RTT不是固定的,會受到網路波動的影響,所以RTT的時間是按照幾次來回時間進行加權平均值和RTT的波動範圍計算出來的,而RTO是在此基礎上透過一些係數換算出來的。
2.快速重傳
雖然有超時重傳,但有些資料包等到真的超時再重傳就有些太慢了,因此linux還有一種重傳機制叫做快速重傳。
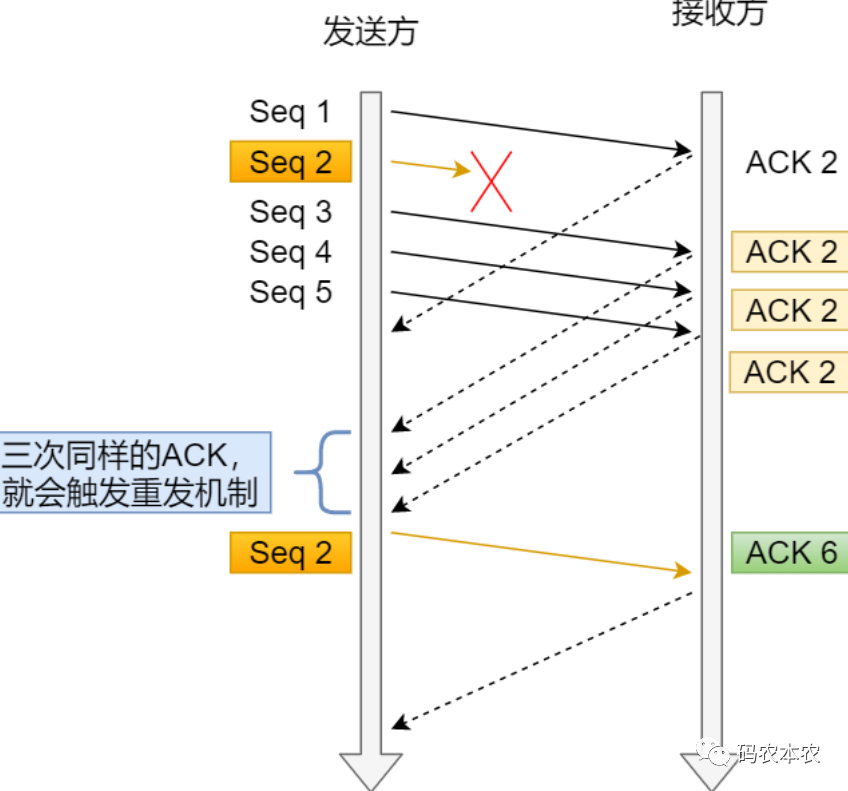
原理是:當發送方發送一條資料seq2後,未能得到ack資料包返回,此時如果後面又連續發送了幾條資料seq3,seq4,seq5,seq6,而後面這幾次收到的ack資料包都是ack2,ack2,ack2,ack2,意思是接收端已經收到了seq2之前的數據,但是seq2還沒有收到,快速重傳機制就是在發送端如果發送了多條數據,但是每個數據包的回覆包的序號都是相同的,例如這個例子中seq3,seq4,seq5,seq6回傳的資料包都是ack2,這個2指的是序號,表示接收端缺少的最大的資料的序號是2 ,發送端應該發送seq2過來,如果有連續的三個ack2,tcp就會判斷需要重發seq2,這種情況可以解決超時重傳等待時間過長的問題,但是新的問題是發送端不知道重新發送seq2還是重新傳送seq3,seq4,seq5,seq6,這種情況下不同版本的linux有不同的實作。
3.麻袋
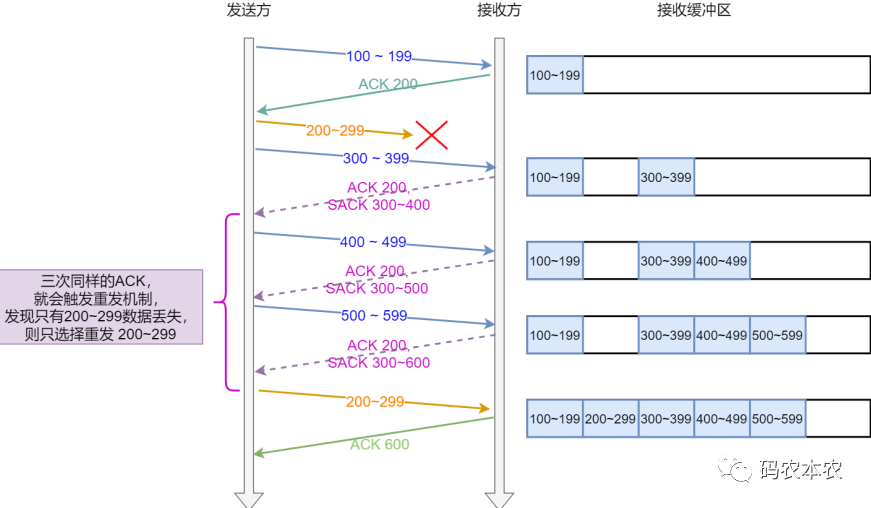
上面的問題丟出來了,linux後面怎麼解決呢,引入sack,這個字段的值會放在tcp頭的選項字段上,就是發生上面例子中的情況下,後面接收端每次收到請求都會回復一個ack和sack,這兩個值中間的部分就是目前接收端缺失的數據,即ack<=x<sack。x就是缺少的那部分數據,這部分數據的序號起始是ack,末端是sack-1,這樣發送端就能知道接收端缺失的是哪部分數據,發送端只需要重新發送這些數據就可以了。
4.d-麻袋
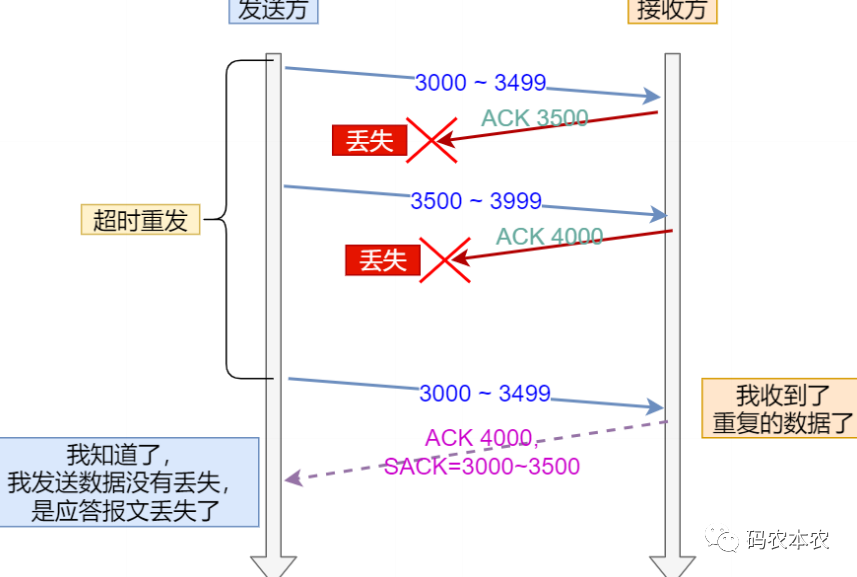
還有一種情況就是發送端發送的資料在網路中延時了,並沒有遺失,那麼在發送端進行重傳後,這個延時的資料又到達了,這樣就造成重複發送,這種情況下會採用d-sack方式,dsack其實就是利用sack處理重複資料的一種方式。還是接收端回覆ack+sack,只不過sack表示目前重複的這條資料的序號,ack表示需要接受的序號,這樣發送端就能知道這條資料已經傳送過了。
不難發現,可以透過ack和sack比較大小來區別這兩種模式,如果ack大於sack就表示是資料重複發送了,如果ack小於sack就表示資料缺失了。
二、滑動窗口
TCP為確保可靠性使用確認應答機制,理論上就是發送端發送一條數據到接收端,接收端收到後回復一個應答數據,一次對話才算結束,然後發送端才會發送下一條數據。
這樣的方式無疑是一種效率極低的方式,所以為了實現可靠以及高效,TCP引入滑動視窗和流量控制
TCP推出滑動視窗的概念,滑動視窗就是接收端和發送端為每個socket開闢一塊空間,只有在接收端滑動視窗空閒的時候才能處理發送端的資料。
原理:發送端每次發送資料到接收端,接收端都會回傳一個滑動視窗大小,表示接收端能接受的最大位元組數,發送方接收到這個滑動視窗大小後可以連續發送多個資料包,只要在滑動視窗範圍內即可。
發送方的滑動視窗有以下區域:
- 已發送還沒有收到回覆區域
- 未發送區域
當已發送的資料得到回復後,滑動視窗會右移。
接收端的滑動視窗有以下區域:
- 已接收但是還沒有被應用程式取走
- 還未接收的區域
如果接收的資料被應用程式取走,則視窗右移。
在滑動視窗範圍內發送端連續發送的幾個資料包,如果中間有一個包的ack遺失了,不一定需要重新發送,發送端可以透過下一個ack確定遺失的這個ack包需要不需要重發。也就是說有了滑動視窗的概念,當ack回復包遺失後不一定需要重發。
發送端的視窗大小是由接收端決定的。
三、流量控制
滑動視窗的概念的提出,使得一次可以發送多個資料包,解決了一次只能處理一個資料包,效率低的問題。但是因為接收端的處理能力是有限的,作為發送端不能源源不斷的給接收端發送數據,如果數據流量大了,接收端處理不了,就只能丟棄數據了,所以必須有一種機制可以控制數據的流量。
TCP的流量控制也恰恰是基於滑動視窗的,滑動視窗由接收端確認後發送給發送端,發送端根據視窗大小進行發送數據,就能保證發送的資料在接收端都能被接收處理。
但是基於滑動視窗實現流量控制TCP考慮了這樣幾個問題:
滑動視窗是socket緩衝區中的一塊空間,socket對應的緩衝區也不是一成不變的,所以如果緩衝區變化對滑動視窗的同步就會造成一些影響。例如接收端通知發送端視窗大小為100,但是此時作業系統把socket緩衝區減小了到了50,收到的資料大於50,就會把包包丟掉就出現了丟包現象。
還有一個問題,糊塗視窗問題,例如因為接收端處理比較慢,滑動視窗為0,視窗處於關閉狀態,一段時間後,視窗出現了可能50個位元組空閒空間,這時候就會把視窗=50通知發送端,發送端接收到視窗=50後,就會發送50字節的數據過來,但是要知道不管發送多少數據,tcp都要給數據包上tcp頭,tcp頭就有20字節,同時還要包ip頭,也是20字節,足足40字節,而發送的資料就只有10字節,性價比是極低的。而且還會佔用頻寬。
tcp在實現基於滑動視窗實現流量控制的時候不得不考慮上面的問題,tcp要如何解決呢?
tcp不允許同時減少緩衝區大小和視窗大小,如果需要減少緩衝區大小,必須先減少視窗大小,一段時間後再減少緩衝區大小。
要解決糊塗視窗的問題,就要避免接收端給發送端回復較小的視窗和避免發送端發送小的資料包。
tcp規定接收端在視窗大小<min(mss,緩衝區的一半)的時候就要關閉視窗(回復接收端視窗為0),這樣就能保證接收端不會發送小的視窗給發送端了。
發送端也要解決發送小資料的問題,發送端是透過nagle演算法進行延遲處理,也就是滿足以下兩個條件中的一個才可以發送:
- 視窗大小大於mss或資料大小大於mss
- 收到上一個資料發送回覆的ack
只要滿足這兩個中一個就可以發送。但是這個演算法一旦開啟就會造成一些資料本身就很小的套件不能及時發送,所以這個演算法開啟要慎重考慮。
tcp依賴上面的機制實現流量控制,具體的流程就是接收端每次都會給發送端回復窗口大小,當接收端很忙的時候,可能窗口就會變小到0,就會通知發送端窗口關閉,此時發送端就不會再發送資料給接收端,當接收端視窗變大後,就會主動回覆發送端視窗大小。
但是這個回應可能會遺失,那麼這是就會出現互相等待的問題,可以理解為死鎖,tcp的解決方案是定義一個時鐘,就是一個定時器,當到達一定時間接收端還沒有通知窗口的話,發送端就會發送探測報文,一般每30-60秒發送一次,發送三次(這裡不同實現可能不一樣,可以配置),如果回復了窗口就開始發送數據,如果回复的窗口依然是0就重置時鐘重新計時,如果最終都沒有打開窗口,發送端可能會發送rst包給服務端終止連接。
四、擁塞控制
滑動視窗和流量控制保證了接收端繁忙的時候,資料不會因為無處放置而丟棄。
但是網路是共享的,網路也會存在很繁忙的情況,如果網路擁堵,也會造成丟包,tcp在沒有收到ack的時候就會重傳,使得網路更加擁堵,丟失資料會更多,就會使得整個網路環境更加糟糕。
tcp為解決網路擁塞帶來的資料遺失問題,提出了擁塞控制。
在擁塞控制機制中的兩個概念:擁塞視窗和擁塞演算法
首先來看怎麼才算擁堵,tcp認為只要是出現超時重傳就算擁擠了。
tcp在發送資料的時候,發送資料的大小受到滑動視窗和擁塞視窗的限制,也就是發送端能發送的最大資料量是擁塞視窗和滑動視窗的的最小值。
擁塞演算法
(1) 慢啟動:
在剛建立連線的時候,滑動視窗和擁塞視窗一致,接下來我們假設滑動視窗和擁塞視窗初始值為100位元組,後面的說明都以此假設為基礎。
慢啟動,就是在初始值的基礎上,發送端向接收端發送100位元組資料包(這裡不要考慮資料包的個數,直接以總位元組數來說明),當所有的ack返回後,擁塞窗口就會在100的基礎上加100。再循環一次就是在200的基礎上加200,再一次就是加800,這種演算法的擁塞窗口是指數級增長的,並且增長速度很快,因此總要有個限制的,這個限制叫做擁塞門限值,這個值預設65535個位元組。當擁塞視窗的值達到這個值後就進入壅塞避免階段。
(2) 擁塞避免:
當擁塞視窗的值達到擁塞門限值後,就會進入擁塞避免階段,在這個階段,例如當前擁塞視窗的值達到了65535個字節,如果這個65535個位元組都發送出去了,當所有的ack返回後,就是在65535個位元組的基礎上加65535個字節,再一次就再加65535個字節,再一次還是加65535個字節,也就不再是指數級增長了,而是線性成長,說穿了就是成長的速度降下來了。但是即便是這樣,擁塞視窗值也處於一個成長狀態。那什麼時候是個頭呢,答案是出現超時重傳的時候。
(3) 擁塞發生:
當發生重傳的時候就意味著擁塞現象發生了,擁塞發生是因為重傳造成的,重傳分為超時重傳和快速重傳,當發生超時重傳的時候說明網絡確實很糟糕了,tcp的做法是將擁塞門限值設定為此時擁塞視窗值的一半,同時將擁塞視窗值設為1.從而再次進入慢啟動階段。而如果發生的是快速重傳,說明網路也不是很糟糕,擁塞視窗值會設定為此時擁塞視窗值的一半,擁塞門限值也會設定為擁塞視窗值的一半,此時如果什麼都不做就會進入擁塞避免階段,但是對於這種情況,tcp會進入快速恢復演算法。
(4) 快速恢復:
就是在目前在目前擁塞門限值的基礎上加3來表示擁塞視窗的大小,接下來重發失敗的數據,收到恢復後就加1,接下來發送新的數據並進入擁塞避免階段。