深入聊聊Web3 世界中的協議和硬盤:IPFS
2023.01.06

深入聊聊Web3 世界中的協議和硬盤:IPFS
在Web3.0 的世界裡,有很多技術都可以替代這三項技術,並且把事情做的更好。而其中最優秀的項目之一,是一個集成了協議、資源加速和存儲於一身的技術:IPFS。
在Web2.0 的世界裡,協議通常是HTTP,資源加速通常是CDN,對象存儲通常是OSS。
在Web3.0 的世界裡,有很多技術都可以替代這三項技術,並且把事情做的更好。而其中最優秀的項目之一,是一個集成了協議、資源加速和存儲於一身的技術:IPFS。
本文將會介紹IPFS 是什麼,以及它的運行原理。
IPFS 的白皮書在2014 年7 月發布,其中提到了很多技術方案的暢想。它的理念和傳統的Web2.0 中HTTP、CDN 和OSS 截然不同。
在介紹IPFS 之前,先來回顧一下HTTP、CDN 和OSS 的優勢和弊端。
為什麼HTTP、CDN、OSS 這些技術在Web3 的世界裡玩不轉了?
HTTP 的優勢與弊端
這裡指的HTTP 是HTTP1.1 和HTTP2.0。
它的優勢是處理小文件的傳輸。
但是現代互聯網的數據傳輸存在5 點挑戰:
- 託管和分發的數據量已經達到PB 級別。
- 跨組織的大數據計算。
- 分發海量高清視頻。
- 海量數據的鏈接和版本管理。
- 防止重要文件丟失。
將以上總結為:海量數據,無處不在。
而這些,都是HTTP 難以應對的。所以隨著互聯網持續不斷的發展,HTTP 遲早會退出歷史的舞台。
CDN 的優勢與弊端
CDN 主要目的是為了加速靜態資源的訪問速度,這也是它主要的優勢。其次可以抵抗DDOS 攻擊,維護也比較方便。
但缺點很明顯,搭建CDN 服務器的過程比較複雜,成本也高,所以一般都會買服務端的CDN,但價格也不算低。
OSS 的優勢與弊端
這裡指的OSS 是雲服務商的OSS 服務。
OSS 的優勢就是高可靠、易擴展、速度快、邊緣計算。在此之上可能還會有鏡像、備份、安全、脫敏等一系列高級功能。總結來說就兩個字:省心。
缺點也很明顯,價格非常貴。但是所有OSS 服務商都把低成本也算做它的優勢之一。事實上在數據量少的情況下感受不出來,可一旦數據量激增後,高昂的價格實在讓人無力接受,這一點我有深刻的體會。
當然OSS 貴的真正原因不是存儲成本高,而是帶寬成本高。
現代互聯網的問題
上述的問題都屬於技術的範疇,除此之外,還有一個根本性的問題。現代互聯網模式的問題。
技術問題、成本問題、效率問題
因為現代互聯網都是中心化的模式。這種模式成本極高,需要構建中心化大規模的服務器集群,而且在高峰期容易出現服務阻塞延遲、低谷期大量資源限制浪費等問題,效率很低。這種模式很依靠中心化服務商的存儲和帶寬。儘管有了彈性計算等技術可以緩解這種情況,但解決不了根本模式的問題。
IPFS 可以共享存儲和帶寬,這樣可以更高效利用資源,降低成本。
IPFS 可以有效地去重文件、消除冗餘。
數據所有權問題
現代的互聯網很容易丟失數據。因為數據都是在中心化的服務器集群上,服務商擁有數據的管理權利。儘管大型服務商都有數據備份和容災方案。但是偶爾還是會發生意外。最重要的是,服務商可以以任何理由刪除我們的數據,比如說你的數據不合法,說你違反平台規定。作為一個普通人,是很難和服務商對抗的,一些重要的數據就這麼不知不覺間消失了。
IPFS 可以永久保存數據。
嚴重依賴主幹網
現代互聯網嚴重依賴主幹網,一旦主幹網發生故障,就會發生大規模服務中斷和延遲。
IPFS 不依賴主幹網,即使網絡不發達的地區,IPFS 一樣有很好的表現。
審查機制問題
由於現代互聯網應用都是中心化網絡,也就導致統治者可以讓整個國家的人民都無法訪問某個網站或者App,在國內這種做法也稱為牆。
IPFS 是IP 是分佈式的,幾乎無法被牆。
生態問題
雖然服務商支付了大額的費用幫我們搭建服務器集群為我們提供產品。但是羊毛出在羊身上。它們會通過會員費、廣告費等一些列手段收走我們的錢。甚至為了獲利,喪失底線,濫用用戶隱私,不斷越界,做虛假廣告,惡意彈窗廣告,限製網速擠牙膏,甚至出賣我們的數據,收取公關費用刪帖封號等。
除了上面這些問題外,互聯網安全也是一個令人頭痛的問題。比如各種反人類的驗證碼。
在過去我們沒有選擇,雖然難以忍受,但也只能忍氣吞聲,用著互聯網在互聯網上罵互聯網。但是現在不一樣了,我們有更好的選擇。在IPFS 世界裡,這些問題統統不復存在。
愛奇藝之前推出過一個小品,笑不活了,用來諷刺現代互聯網。有人把它搬運到了知乎,感興趣的話可以去看一下:www.zhihu.com/zvideo/1433…。
這是一些我們不想看到的結果:

IPFS 是什麼?
IPFS 有很多定義。
從它的論文來定義,IPFS 是一個按照內容索引的、版本化的、點對點的文件系統。
從技術的角度來定義,IPFS 是一個長滿默克爾樹(merkle-trees)的森林。
從商業的角度來定義,IPFS 是一個點對點的超文本協議。
它會讓互聯網更快、更安全、更開放。
IPFS 介紹
IPFS 是一個縮寫,全稱Inter Planetary File System,星際文件系統。
它是點對點的星際文件系統,從這種角度上來說,它對標的是整個互聯網,而不是某個協議,或者某個文件存儲系統。它更像單一的BitTorrent 集群(swarm)。
IPFS 作者介紹
作者是Juan Benet,按照中國人的習慣音譯為胡安。美國人,1988 年出生,畢業於斯坦福大學,是一個不折不扣的技術牛人。
胡安也是Protocol Labs(協議實驗室)、IPFS 和Filecoin 的創始人。
2014 年他創建了Protocol Labs,同年啟動了IPFS 項目。
Protocol Labs 是IPFS 和Filecoin 的官方組織,它的目標是如何構建下一代互聯網。
在4 年後,也就是2018 年,他入選了財富雜誌的40 under 40 名單。
IPFS 基於哪些技術?
IPFS 的核心技術
IPFS 的核心原則是將所有數據作為同一默克爾有向無環圖(Merkle DAG)的一部分來建模。
它採用但不限於以下技術:
- 基於分佈式哈希表DHT 進行內容尋址。
- 基於Git 模型進行對像管理。
- 基於默克爾對象關聯。
- 基於點對點技術。
- 基於全球化命名空間IPNS。
通過以上的各種技術,解決了海量數據、高並發、大吞吐量、文件丟失等一系列問題。
而它做的事情,總結來說只有三點:規定瞭如何上傳文件、如何檢索文件、如何下載文件。
你可能會問,這些技術大多不都是過去P2P 領域的技術嗎?沒錯,IPFS 就是一個P2P 集大成者,它沒有憑空創造很多技術或者概念,而是站在了巨人的肩膀上。
為什麼是點對點?
現代互聯網資源,都需要一個http 地址才能獲取,所以我們瀏覽器的收藏夾裡存儲了大量的網址。這種模式就是基於位置的尋址模式。
但仔細想想,其實我們只在乎資源的內容是不是我們想要的,而不在乎資源在哪裡。
我們需要的資源,一定也會有其他人需要。如果我們附近有人的電腦上下載了這份資源,我們只需要從這個人的電腦上直接下載就可以了,沒必要再去這份文件的源頭上面獲取。這種模式就是基於內容的尋址模式。
點對點的傳輸模式是以上的基礎。
IPFS 的運行原理
我們在IPFS 上傳文件,需要經過如下幾個步驟。
- IPFS 首先會把文件以256 kb 為一個單位分成若干個小數據塊,然後分別打上哈希指紋。哈希指紋是一個唯一的字符串,能和數據塊一一對應。
- 然後IPFS 將每兩個小數據塊的哈希值再進行哈希運算,得到一個新的哈希。它會重複這個過程,直到將所有的數據塊的哈希值全部計算成一個哈希值為止。最終的這個哈希值,就是根哈希(Root Hash),也叫做CID(Content Identifier)。這個過程就是構建Merkle DAG 的過程,也就是IPFS 的核心原則。
- IPFS 會去除重複文件。因為每個文件都會對應一個哈希值,哈希值一致就意味著是重複的文件。IPFS 會去除重複的文件,不過每個節點都可以保留這個節點的備份。
- 每個IPFS 都會存儲它所需要的數據,用DHT 來記錄每個節點存儲了哪些數據。DHT 是內容ID(CID)和用戶ID(PeerID)的映射。IPFS 會向其他所有在線節點發送我們的文件信息,但不是真實的文件,而是一個結構。包含了CID 和PeerID。每個節點都會更新自己的哈希表。所以這個過程非常快。就像是程序中的複制變量地址,而不是複制實際的變量內存空間類似。
- 當我們需要獲取某個文件時,會通過文件的哈希值去尋找這個文件在哪些人的電腦上,然後從這些人的電腦進行下載。如果我們需要的文件存儲在100 個人的電腦上,而現在這100 個人同時在線,那麼我們可以同時和這100 個人進行傳輸文件,最後再組合成完整的文件。這樣的下載速度理論上會比從一個人那兒下載快100 倍。這也就是IPFS 主要的工作邏輯。
數據塊的的數據結構大致如下:
data:包含不超過256 kb 的數據。
links:連接到其他數據塊。
如果某個文件非常大,那麼就會首先把它的內容生成N 個數據塊,再從它們上層創建一個數據塊,links 指向其他所有數據塊。
IPFS 為什麼需要Git?
一旦文件的內容髮生了變化,那麼原來的哈希值就會失效。所以IPFS 的文件內容是不可變的。
但是如果我們需要更新文件的內容怎麼辦?
為了追踪文件的更新,IPFS 引入了版本控制模型,和Git 基本上是一致的。
我們第一次將文件上傳到IPFS 時。IPFS 會創建一個Commit 對象。它的結構大致如下:
- parent:指向上一個commit,第一次commit 指向none。
- object:文件內容。
如果我們需要更新文件內容,首先把新的文件上傳到IPFS。
IPFS 會為我們創建新的Commit 對象,它的commit 會指向上一個commit 對象。
這樣我們就可以追踪文件內容的變化了。
IPFS 無法確保始終有資源
如果擁有某個資源的全部節點全部下線,那麼這個資源將會永遠無法下載。就像BT 下載時沒有種子。
為了解決這個問題,我們需要有對應的方案。
IPFS 有兩個方案。
- 通過激勵機制鼓勵節點多存儲文件,並且長期在線分享。
- 主動分發文件,保證始終有在線備份。
而這個激勵機制就是Filecoin,關於Filecoin 我們後面再聊。
IPFS 和區塊鍊是什麼關係?
嚴格來說兩者沒有關係,IPFS 並沒有使用任何區塊鏈技術。不過區塊鏈行業的人依然都知道IPFS 這個東西,原因是IPFS 團隊的另一個產品Filecoin 和區塊鏈有關係。
IPFS 和Filecoin 的關係
Filecoin 是一個區塊鏈應用,可以簡單理解為一種數字貨幣。
兩者沒有直接的關係,只是一個團隊的兩個產品。
不過IPFS 會為Filecoin 提供底層支持,Filecoin 也會為IPFS 注入更多活力。
我們在IPFS 的運行原理中講到,我們最終是在其他用戶的電腦上下載的文件,而從其他用戶電腦下載是需要一定網絡成本的。為了鼓勵大家都給其他人分享資源,IPFS 有一種激勵模型,叫做BitSwap。
如果我們的電腦有很多空閒的存儲空間,可以通過Filecoin 存儲資源,分享給別人。而我們給別人分享,會得到Filecoin 的獎勵。
IPFS 為什麼叫IPFS?
IPFS 叫做星際文件系統。這個名字可不僅僅是因為炫酷、未來感或者科幻感。而是它真的很適合在星際之間傳輸數據。
胡安的野心也並不僅僅是取代互聯網那麼簡單。伊隆馬斯克在想辦法讓人類遷移火星,但肯定不會一下子讓全體地球人都移居火星。在未來很可能會存在部分人在地球,部分人在火星的情況。
如果在火星獲取地球的一個網頁,延遲非常久,發射一次信號需要4-24 分鐘。一個來回就需要8-48 分鐘。這種延遲非常難以忍受。可是一旦有任意一個火星上的人獲取到了這個網頁,那麼其他火星人就可以通過獲取這個人電腦的網頁來避免這個延遲。
所以IPFS 是一個名副其實的宇宙級傳輸協議。
IPFS 怎麼用?
IPFS 的官網是ipfs.tech/。
在官網的中間有安裝方式。IPFS 的安裝方式有兩種,桌面客戶端和CLI。
我們選擇下載桌面客戶端。
我們主要是通過這個客戶端來參與到IPFS 網絡中的。
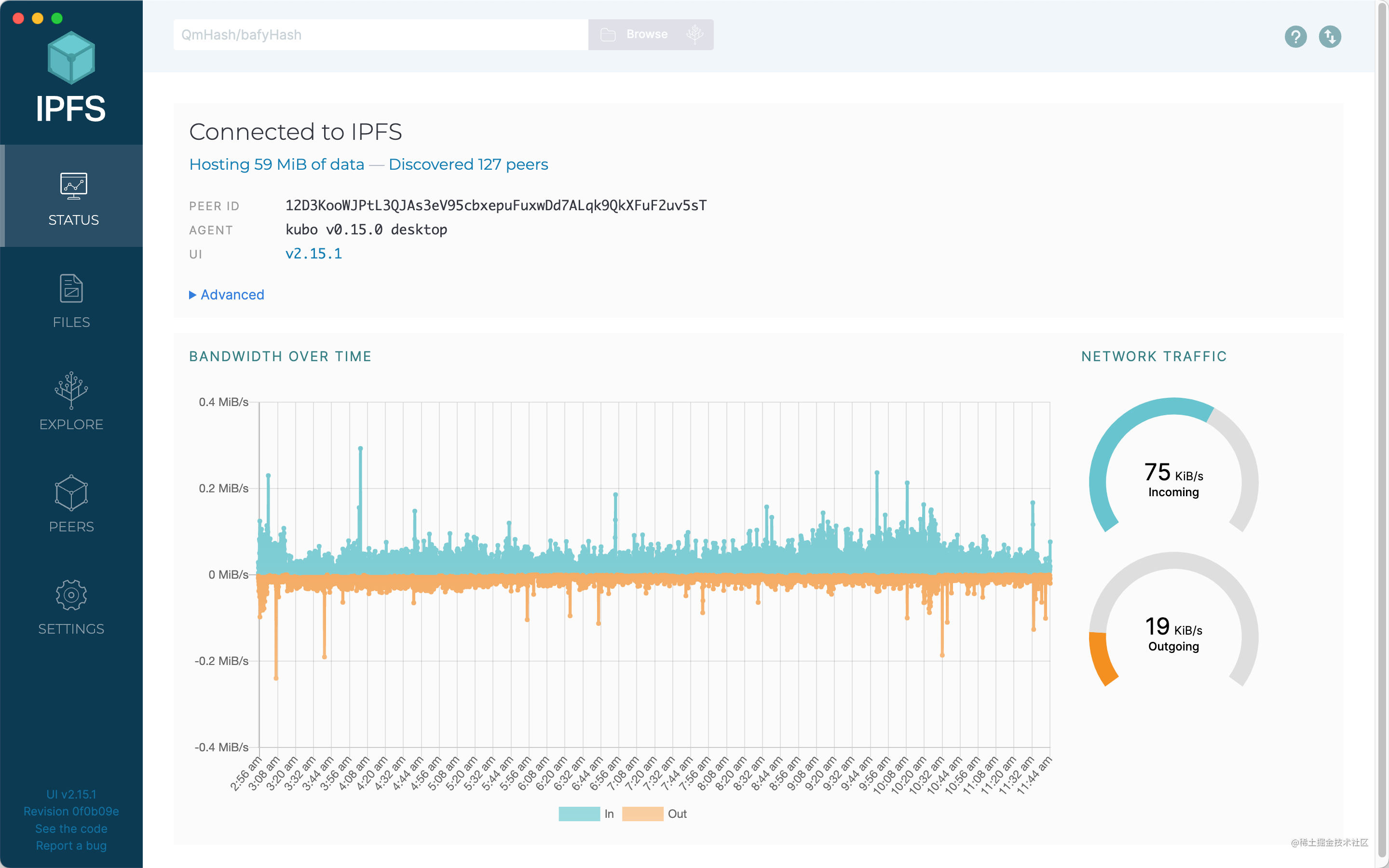
左側有五個菜單,我分別介紹下它們的作用。
Status
這個頁面是一些總攬數據,包含了託管數據大小、在線節點、節點ID、代理版本、UI 版本、實時帶寬等信息。
Files
在這裡可以上傳和刪除文件。
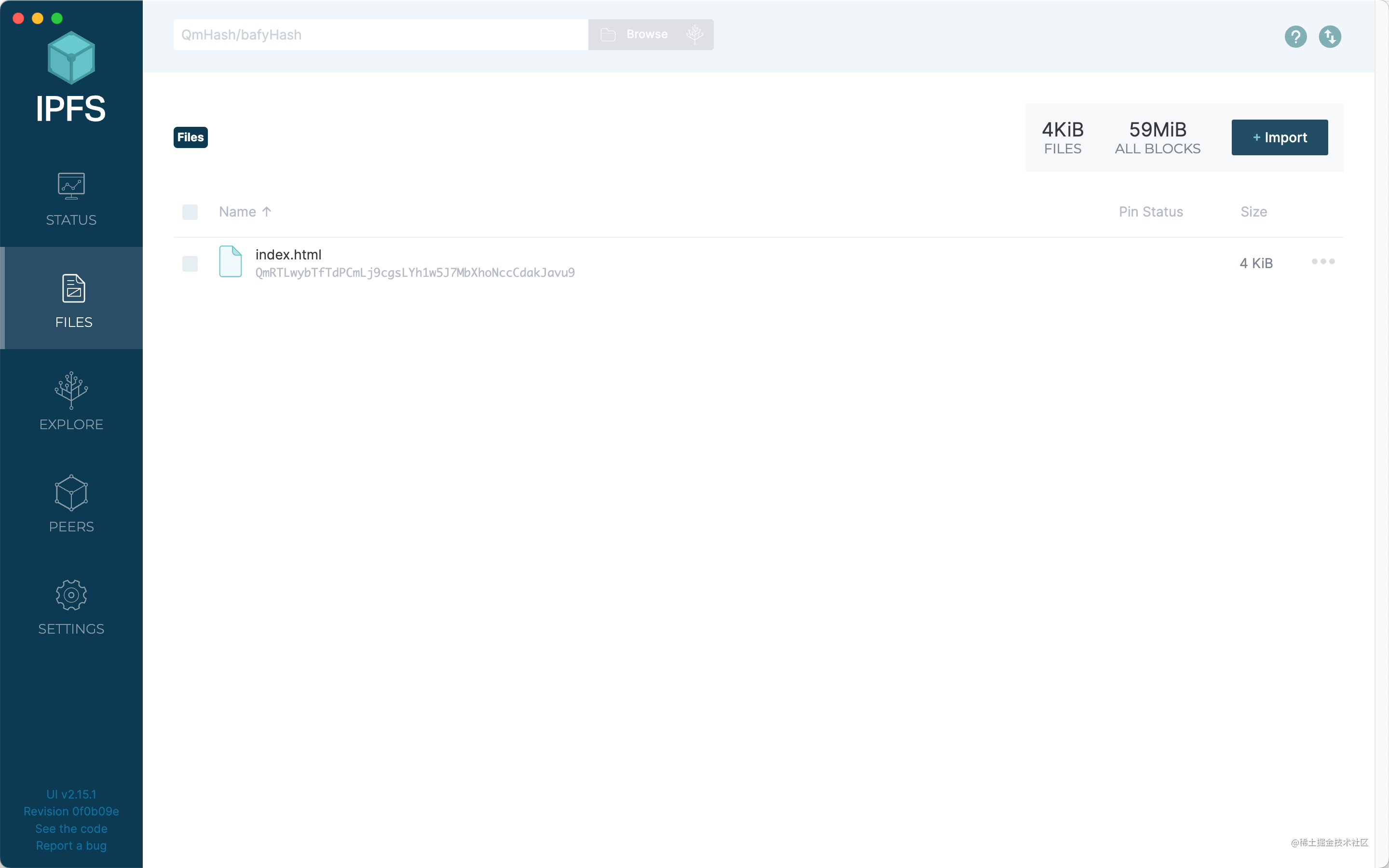
點擊import 按鈕,可以選擇上傳的文件或者文件夾。
它的上傳速度非常快,但是實際上並沒有進行文件上傳的操作,它只是把文件進行了哈希運算,並且把CID 和PID 分發到當前所有在線的節點中。
上傳完成之後,我們會得到一個CID。點擊文件的右側三個點,選擇Copy CID,就可以將這個CID 分享給其他IPFS 用戶了。
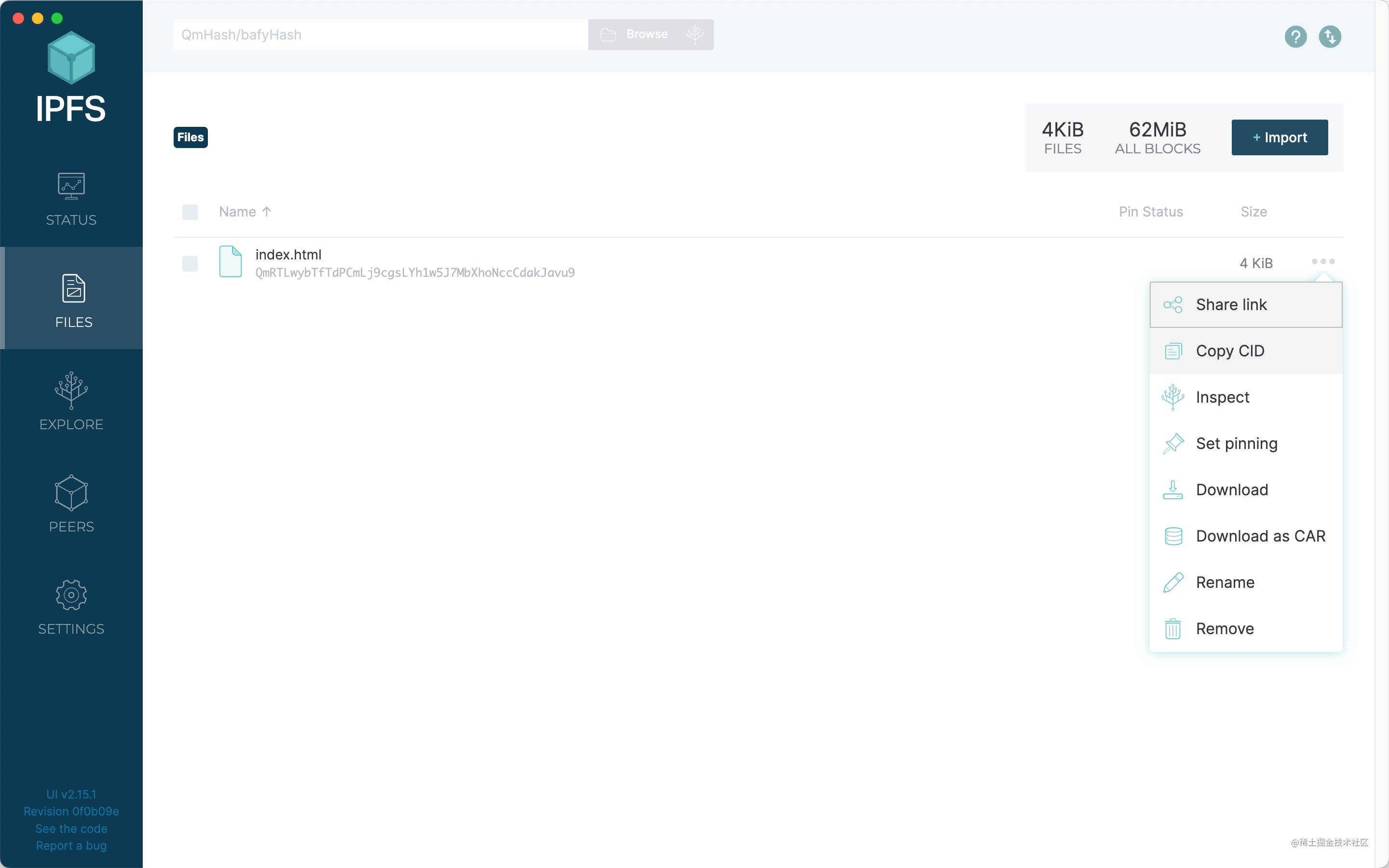
其他用戶拿到CID 後,可以在IPFS 的客戶端頂部的搜索框中進行搜索。
如果能夠搜索到,就可以進行預覽或者下載了。
另外瀏覽器中也可以使用IPFS 協議。直接在瀏覽器中輸入ipfs://{cid},就可以直接打開文件資源。不過這需要在本地啟動IPFS 客戶端。
如果未來IPFS 發展非常順利的話,這項功能可能會被內置到瀏覽器中,而不再需要單獨啟動客戶端。
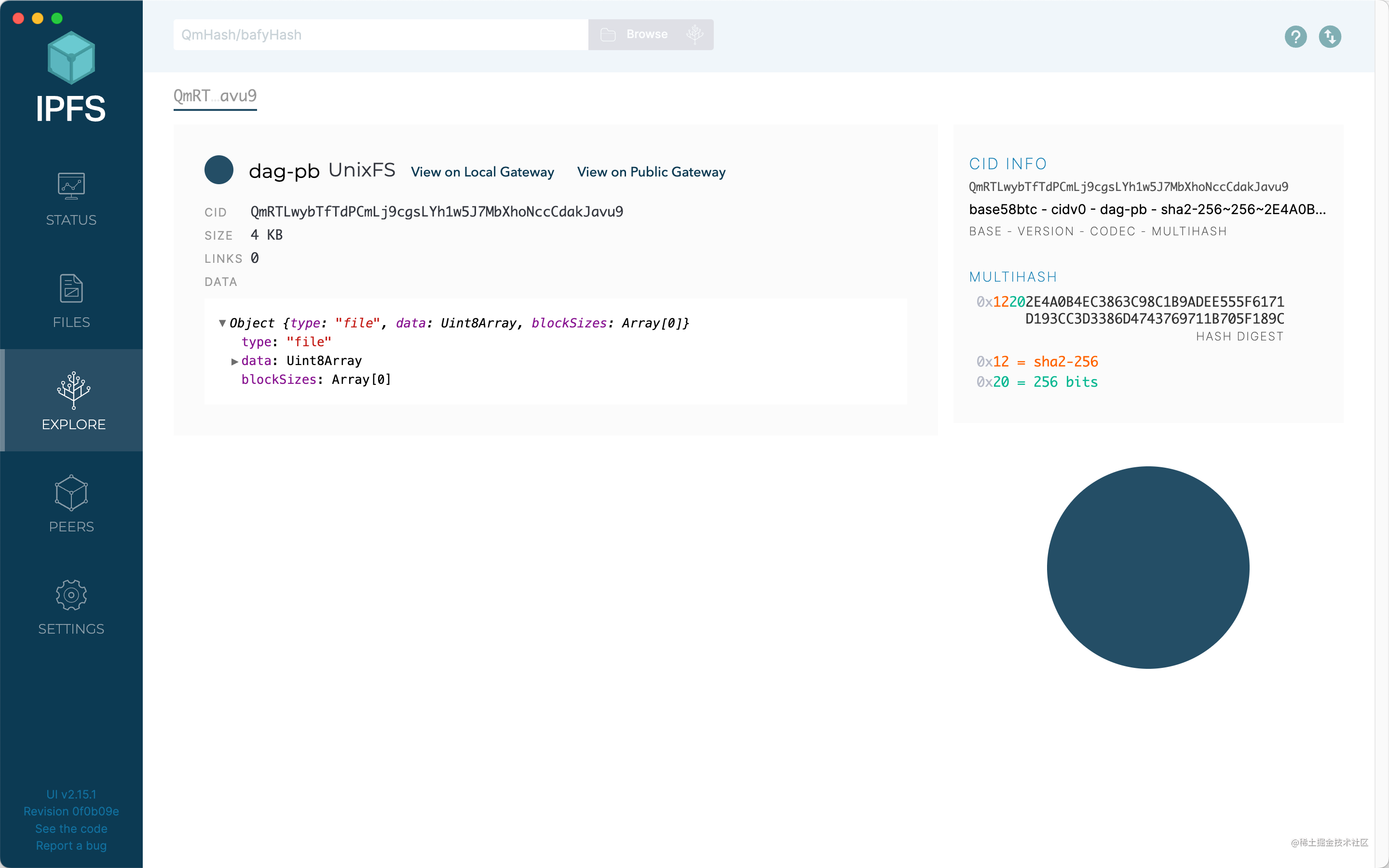
Explore
在這裡可以進行CID 搜索,獲取尋址IPLD 節點、文件對象、CID 信息等。
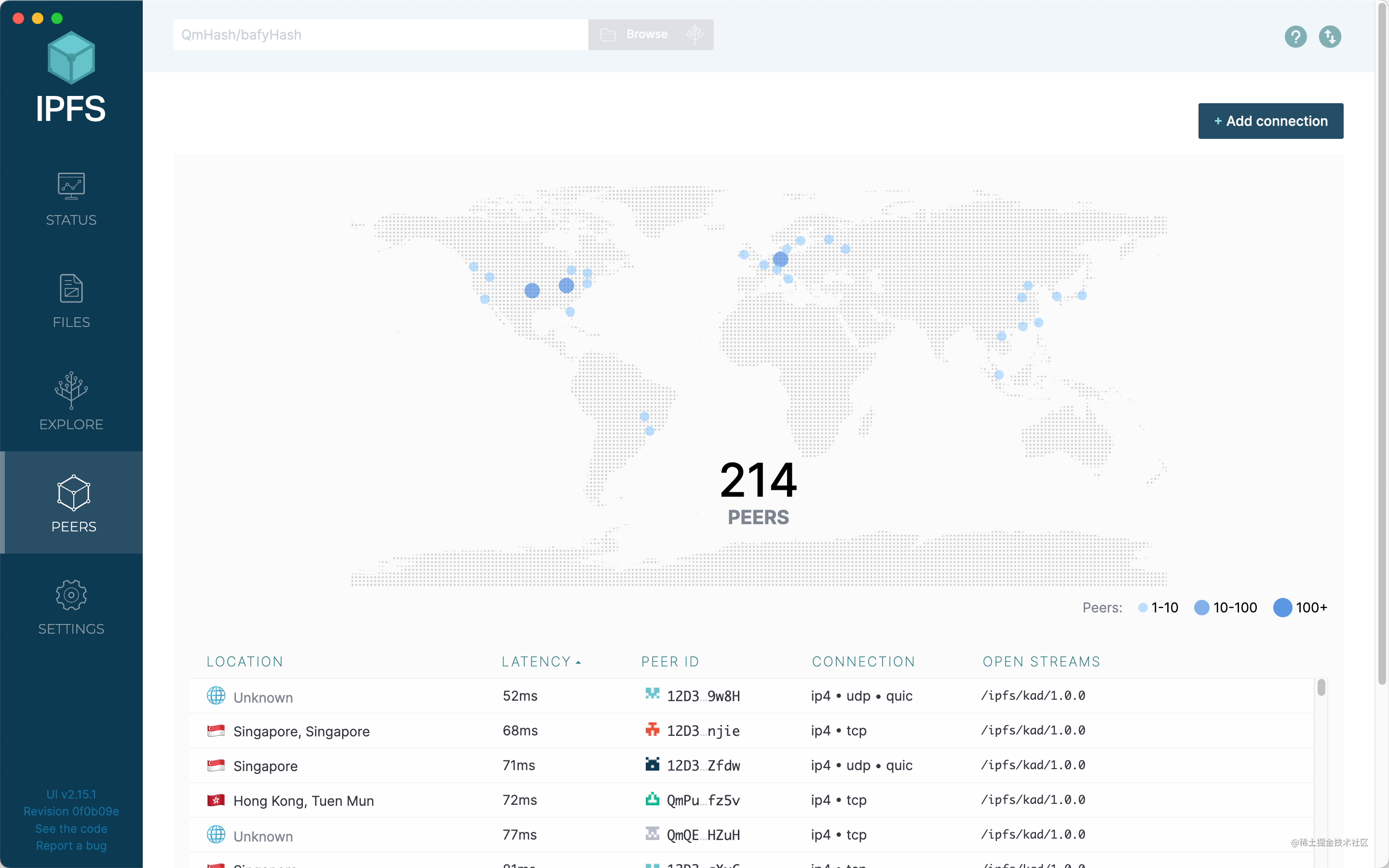
Peers
在這裡可以看到其他的節點的信息。
包括節點所在物理地址、延遲、節點ID、傳輸協議、連接協議等。
節點越多,我們的體驗就會越好。
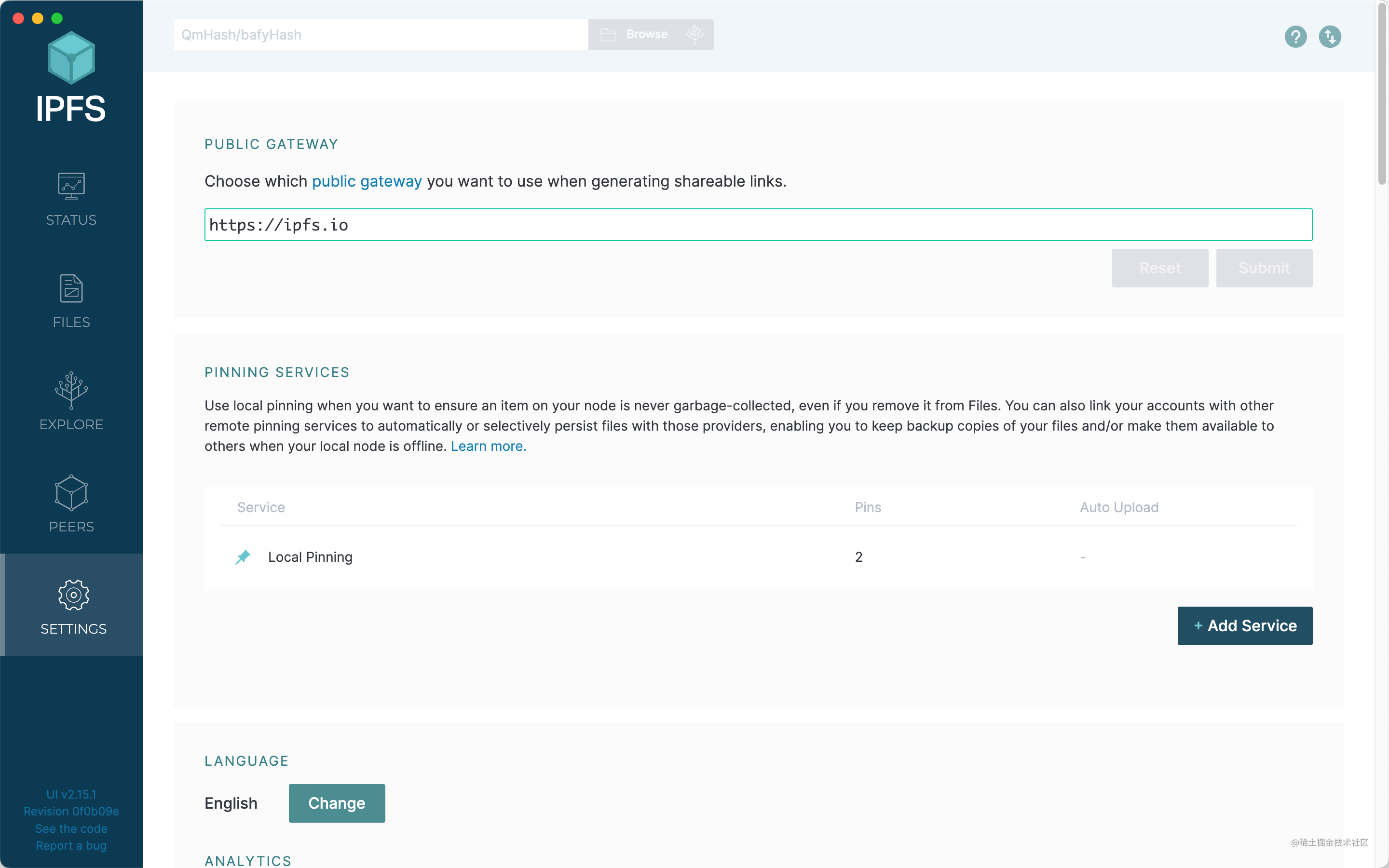
Settings
在這裡可以修改分享鏈接的網關、固定服務、語言、IPFS JSON 配置等內容。
IPFS 的缺點和Pin 服務
聊了那麼多IPFS 的優點,IPFS 似乎是一個無限趨向完美的技術。
但它真的是完美無瑕嗎?並不是。IPFS 也有所有P2P 應用都有的一個缺點,那就是如果持有某個文件的所有的節點全部下線,我們將再也無法下載到這個文件。
這個問題也很好解決,如果我們想要某個文件永遠都可以被下載,那麼就把這個文件存儲在我們本地的IPFS 系統中,並且我們本地的IPFS 永遠在線就可以了。
但是很明顯,讓電腦24 小時開機的話,那和服務器沒什麼區別了。
這種事兒在Web2.0 裡面不都是租用某個雲服務去做嗎?Web3 裡面同樣有人幹這事兒。
這種服務被稱為Pin 服務,也就是固定的意思。
Pin 服務的作用是將某個文件固定在IPFS 系統中。
Pinata 是一個專門為NFT 提供IPFS Pin 服務的平台,它也是目前IPFS 生態中做的最大的Pin 服務平台之一。
但是Pinata 並不是免費的,類似的平台也都這樣,通過某種規則進行收費,有點像Web2.0 時代的網盤。
有人認為這種方案並不是長期可行的方案,因為當固定的文件體積非常大了之後,Pinata 的價格也會非常昂貴,目前最高的價格是每月1000 美元。
其實不難總結,目前的互聯網世界裡,不存在100% 免費、絕對去中心化、絕對有保證的永久存儲。
如果真的要實現這種設想,那麼需要每個人擁有一個7*24 小時在線開機的網絡存儲設備。有點像某些科幻小說中構想的那樣,人類在出生時就會在體內植入某個設備。甚至人類可以改寫基因,讓嬰兒從母體中自行發育出這種設備,就像是我們的某個器官一樣,只不過它可以存儲數據,連接到其他人。
我可以斷言,這個時代終將來臨。而步入這個時代的速度,將會取決於能源、網絡、磁盤、計算等一系列科技領域的發展程度。