當網路傳輸協定SRD遇上DPU
2022.12.27

當網路傳輸協定SRD遇上DPU
SRD 實際工作的關鍵不在於協定,而在於它在硬體中的實現方式。 換種說法,就目前而言,SRD 僅在使用 AWS Nitro DPU 時才有效。

What?
SRD(Scalable Reliable Datagram,可擴展的可靠數據報文),是AWS年推出的協定,旨在解決亞馬遜的雲性能挑戰。 它是專為AWS數據中心網路設計的、基於Nitro晶元、為提高HPC性能實現的一種高吞吐、低延遲的網路傳輸協定。
{kind=link}
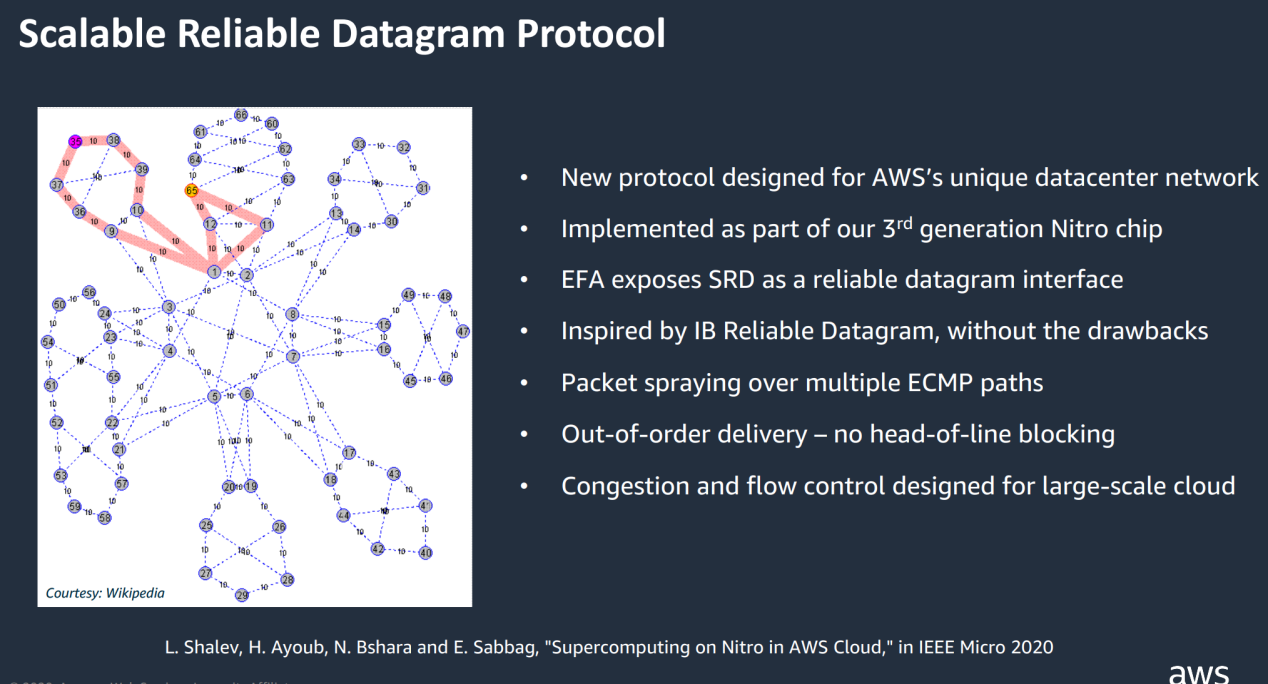
SRD 不保留數據包順序,而是通過盡可能多的網路路徑發送數據包,同時避免路徑過載。 為了最大限度地減少抖動並確保對網路擁塞波動的最快回應,在 AWS 自研的 Nitro chip 中實施 SRD。
SRD 由 EC2 主機上的 HPC/ML 框架通過 AWS EFA(Elastic Fabric Adapter,彈性結構適配器)內核旁路介面使用。
SRD的特點:
- 不保留數據包順序,交給上層消息傳遞層處理
- 通過盡可能多的網路路徑發包,利用ECMP標準,發端控制數據包封裝來控制ECMP路徑選擇,實現多路徑的負載平衡
- 自有擁塞控制演算法,基於每個連接動態速率限制,結合RTT(Round Trip Time)飛行時間來檢測擁塞,可快速從丟包或鏈路故障中恢復
- 由於無序發包以及不支援分段,SRD傳輸時所需要的QP(佇列對)顯著減少
Why?
為什麼不是TCP?
TCP 是IP網路中可靠數據傳輸的主要手段,自誕生以來一直很好地服務於Internet,並且仍然是大多數通信的最佳協定。 但是,它不適合對延遲敏感的處理,TCP 在數據中心最好的往返延遲差不多是 25us,因擁塞(或鏈路故障)等待導致的異常值可以是 50 ms,甚至數秒,帶來這些延遲的主要原因是TCP丟包之後的重傳機制。 另外,TCP傳輸是一對一的連接,就算解決了時延的問題,也難在故障時重新快速連線。
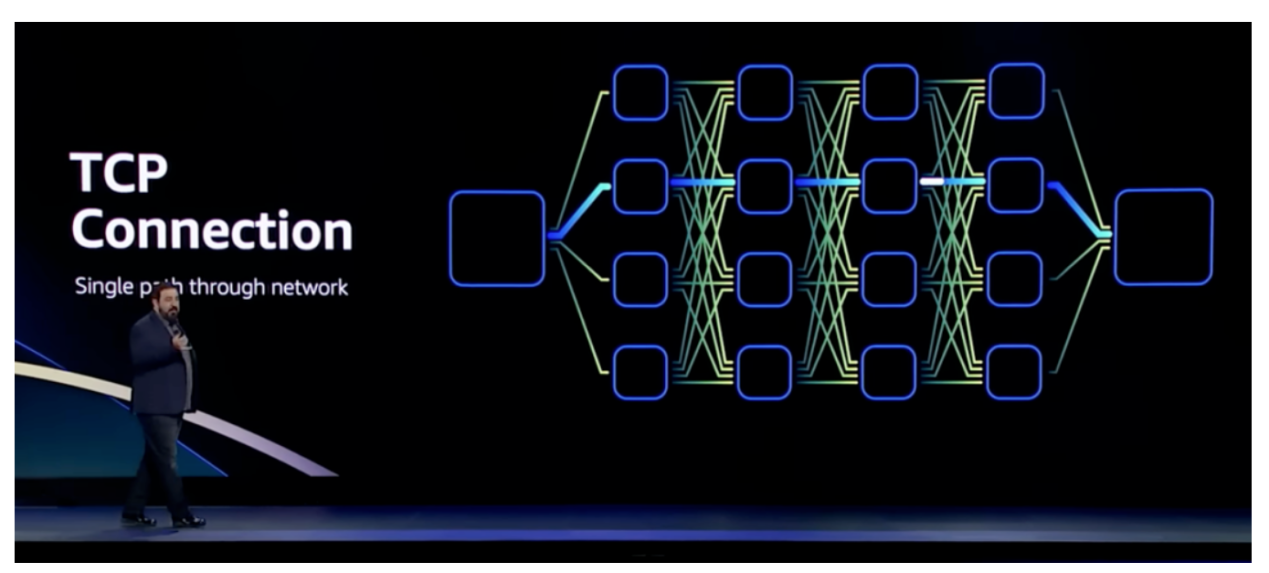
TCP 是通用協定,沒有針對HPC場景進行優化,早在2020 年,AWS 已經提出需要移除TCP。
為什麼不是RoCE?
InfiniBand 是一種用於高性能計算的流行的高輸送量低延遲互連,它支援內核旁路和傳輸卸載。 RoCE(RDMA over Converged Ethernet),也稱為 InfiniBand over Ethernet,允許在乙太網上運行 InfiniBand 傳輸,理論上可以提供 AWS 數據中心中 TCP 的替代方案。
EFA 主機介面與 InfiniBand/RoCE 介面非常相似。 但是 InfiniBand 傳輸不適合 AWS 可擴充性要求。 原因之一是 RoCE 需要 PFC(優先順序流量控制),這在大型網路上是不可行的,因為它會造成隊頭阻塞、擁塞擴散和偶爾的死鎖。 PFC 更適合比 AWS 規模小的數據中心。 此外,即使使用 PFC,RoCE 在擁塞(類似於 TCP)和次優擁塞控制下仍會遭受 ECMP(等價多路徑路由)衝突。
為什麼是SRD?
SRD是專為AWS設計的可靠的、高性能的、低延遲的網路傳輸。 這是數據中心網路數據傳輸的一次重大改進。 SRD受InfiniBand可靠數據報的啟發,結合大規模的雲計算場景下的工作負載,SRD也經過了很多的更改和改進。 SRD利用了雲計算的資源和特點(例如AWS的複雜多路徑主幹網路)來支援新的傳輸策略,為其在緊耦合的工作負載中發揮價值。
任何真實的網路中都會出現丟包、擁塞阻塞等一系列問題。 這不是說每天會發生一次的事情,而是一直在發生。
大多數協定(如 TCP)是按順序發送數據包,這意味著單個數據包丟失會擾亂佇列中所有數據包的準時到達(這種效應稱為“隊頭阻塞”)。 而這實際上會對丟包恢復和輸送量產生巨大影響。
SRD 的創新在於有意通過多個路徑分別發包,雖然包到達后通常是亂序的,但AWS實現了在接收處以極快的速度進行重新排序,最終在充分利用網路吞吐能力的基礎上,極大地降低了傳輸延遲。
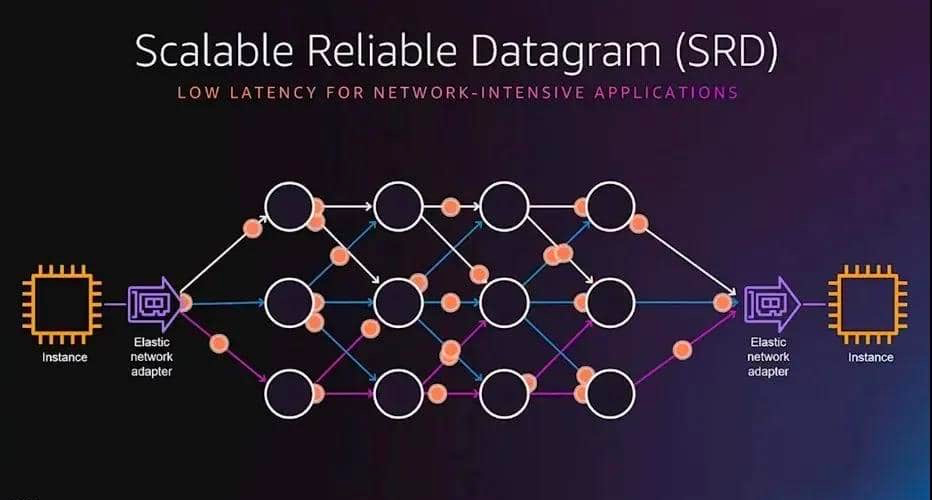
SRD 可以一次性將構成數據塊的所有數據包推送到所有可能路徑,這意味著SRD不會受到隊頭阻塞的影響,可以更快地從丟包場景中恢復過來,保持高輸送量。
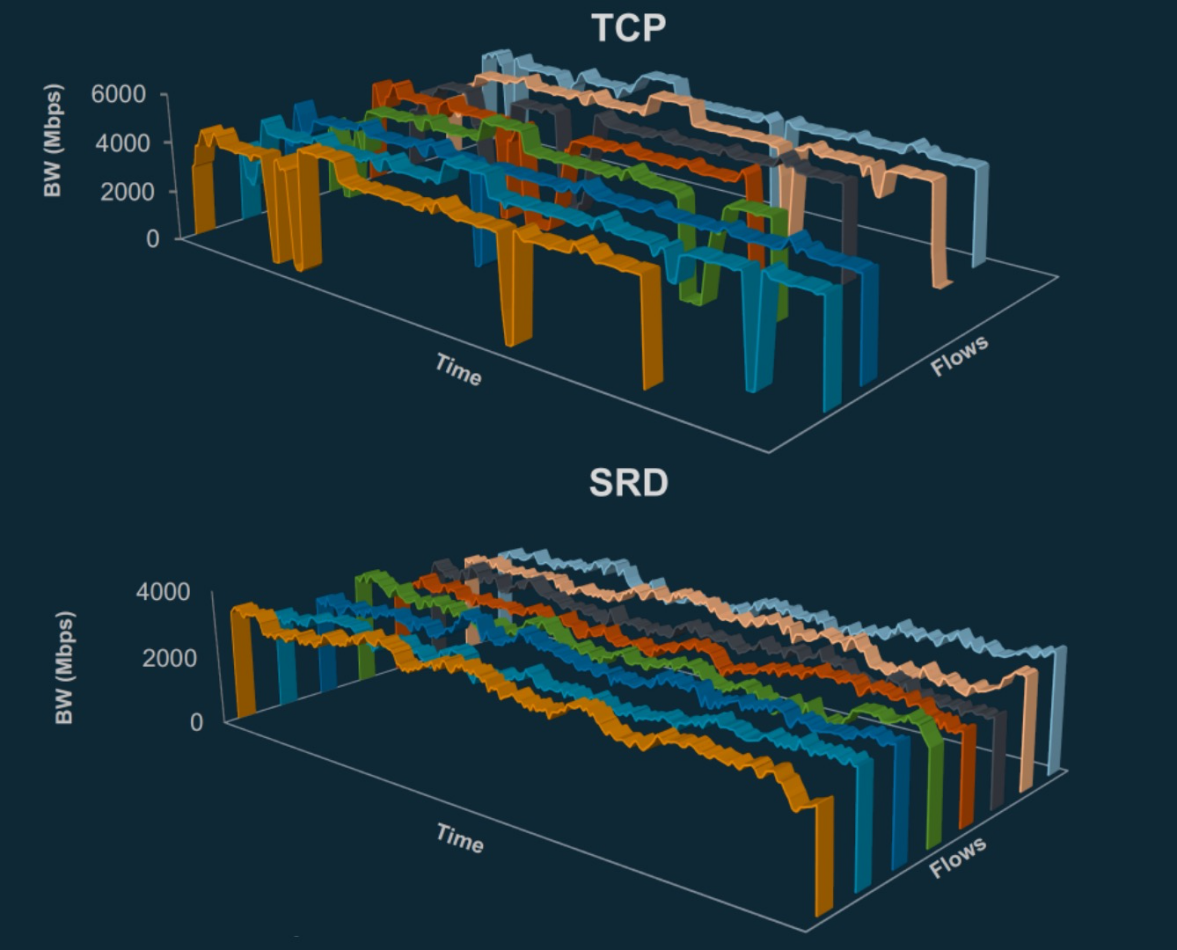{kind=link}
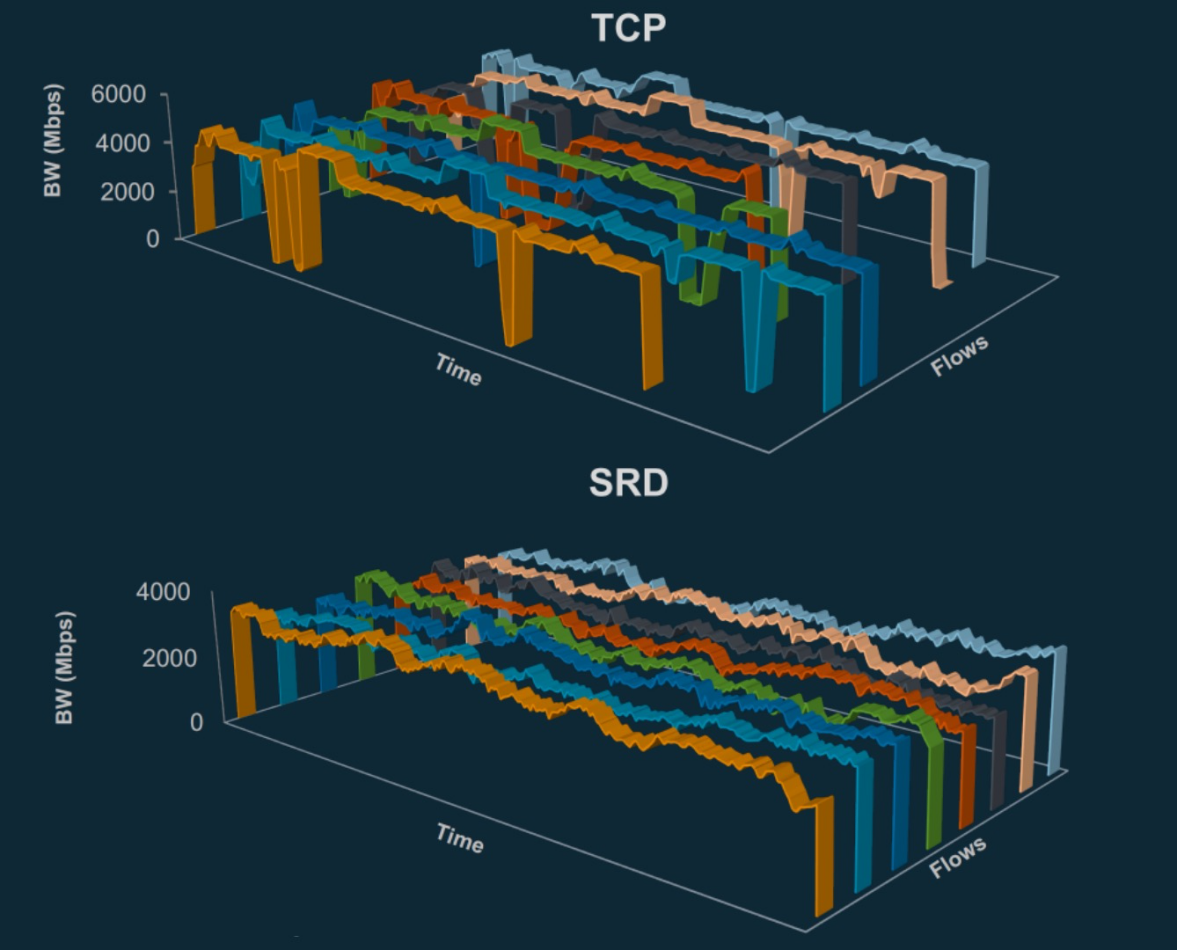
眾所周知,P99尾部延遲代表著只有1%的請求被允許變慢,但這也恰恰反映了網路中所有丟包、重傳和擁塞帶來的最終性能體現,更能夠說明“真實”的網路情況。 SRD能夠讓P99 尾延遲直線下降(大約10倍)。
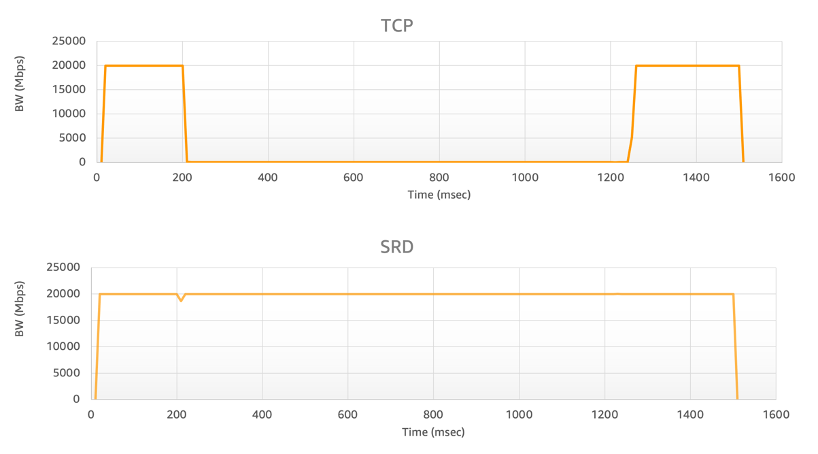
SRD的主要功能包括:
- 亂序交付:取消按順序傳遞消息的約束,消除了隊頭阻塞,AWS在EFA使用者空間軟體堆棧中實現了數據包重排序處理引擎
- 等價多路徑路由(ECMP):兩個EFA實例之間可能有數百條路徑,通過使用大型多路徑網路的一致性流哈希的屬性和SRD對網路狀況的快速反應能力,可以找到消息的最有效路徑。 數據包噴塗(Packet Spraying)可防止出現擁塞熱點,並可以從網路故障中快速無感地恢復
- 快速的丟包回應:SRD對丟包的回應比任何高層級的協定都快得多。 偶爾的丟包,特別是對於長時間運行的HPC應用程式,是正常網路操作的一部分,不是異常情況
- 可擴展的傳輸卸載:使用SRD,與其他可靠協定(如InfiniBand可靠連接IBRC)不同,一個進程可以創建並使用一個佇列對與任何數量的對等方進行通信
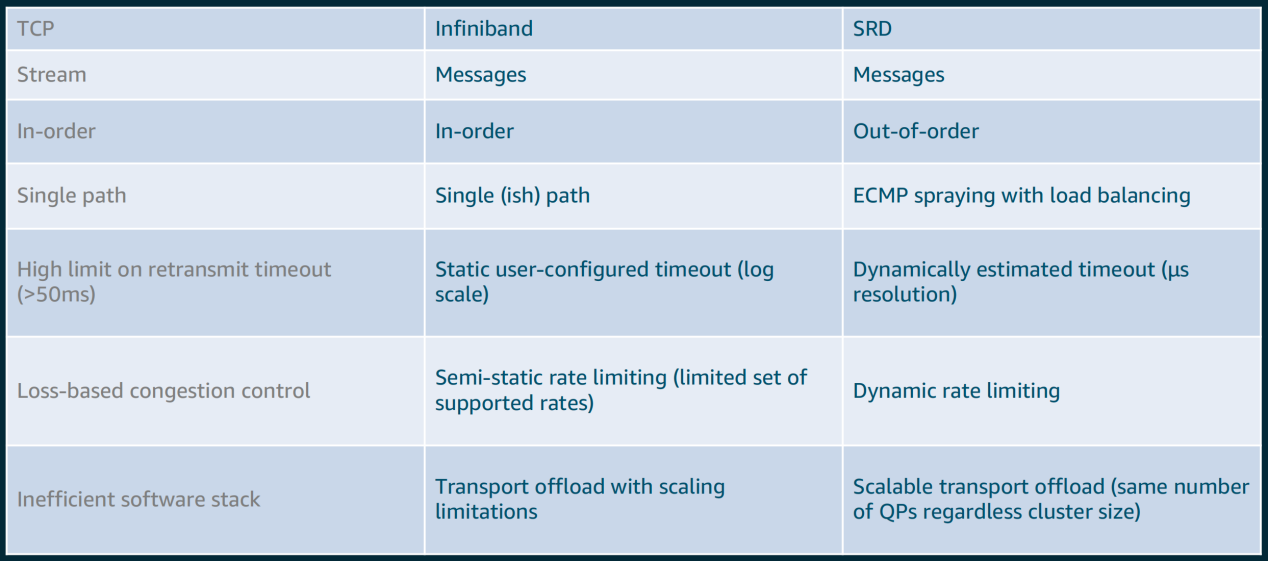
How
SRD 實際工作的關鍵不在於協定,而在於它在硬體中的實現方式。 換種說法,就目前而言,SRD 僅在使用 AWS Nitro DPU 時才有效。
SRD亂序交付的數據包需要重新排序才能被操作系統讀取,而處理混亂的數據包流顯然不能指望“日理萬機”的 CPU。 即便真通過CPU 來完全負責 SRD 協定並重新組裝數據包流,無疑是高射炮打蚊子——大材小用,那會使系統一直忙於處理不應該花費太多時間的事情,而根本無法真正做到性能的提升。
在SRD這一不尋常的“協議保證”下,當網络中的並行導致數據包無序到達時,AWS將消息順序恢復留給上層,因為它對所需的排序語義有更好的理解,並選擇在AWS Nitro卡中實施SRD可靠性層。 其目標是讓SRD盡可能靠近物理網路層,並避免主機操作系統和管理程式注入的性能噪音。 這允許快速適應網路行為:快速重傳並迅速減速以回應佇列建立。
AWS說他們希望數據包在「棧上」重新組裝,他們實際上是在說希望 DPU 在將數據包返回給系統之前,完成將各個部分重新組合在一起的工作。 系統本身並不知道數據包是亂序的。 系統甚至不知道數據包是如何到達的。 它只知道它在其他地方發送了數據並且沒有錯誤地到達。
這裡的關鍵就是 DPU。 AWS SRD 僅適用於 AWS 中配置了 Nitro 的系統。 現在不少使用AWS的伺服器都安裝和配置了這種額外的硬體,其價值在於啟用此功能將能夠提高性能。 使用者需要在自己的伺服器上專門啟用它,如果需要與未啟用 SRD 或未配置 Nitro DPU 的設備通信,就不會得到相應的性能提升。
至於很多人關心的SRD未來是否會開源,只能說讓我們拭目以待吧!