Meituan Ermi: If there are tens of billions of traffic every day, how do you ensure data consistency?
2022.08.27

Meituan Ermi: If there are tens of billions of traffic every day, how do you ensure data consistency?
Simply put, in a complex system, some data must be processed very complexly, and it may be multiple different subsystems, or even multiple services. The execution of complex business logic for a piece of data in a certain order may eventually produce a piece of valuable system core data, which will be stored in storage, such as a database.
1. Preliminary reminder
In this article, let's continue to talk about the evolution of the previous billion-level traffic architecture. Old rules! Let's first take a look at what the overall architecture diagram looks like when this complex system architecture has evolved to the current stage.
The author reminds again that if there is anything you don’t understand about the complex architecture diagram below, you must go back to the previous article first, because the series of articles must have a clear understanding and understanding of the context.
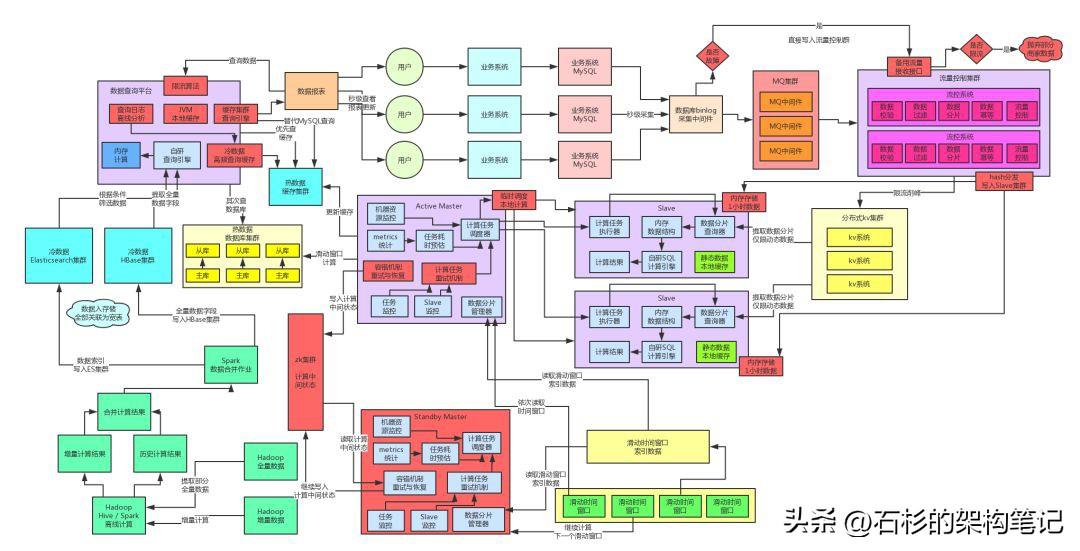
Next, let's talk about how to ensure data consistency in a complex system under the background that a core system carries tens of billions of traffic every day?
2. What is data consistency?
Simply put, in a complex system, some data must be processed very complexly, and it may be multiple different subsystems, or even multiple services.
The execution of complex business logic for a piece of data in a certain order may eventually produce a piece of valuable system core data, which will be stored in storage, such as a database.
Here is a hand-painted coloring picture for you to feel the atmosphere of this scene:
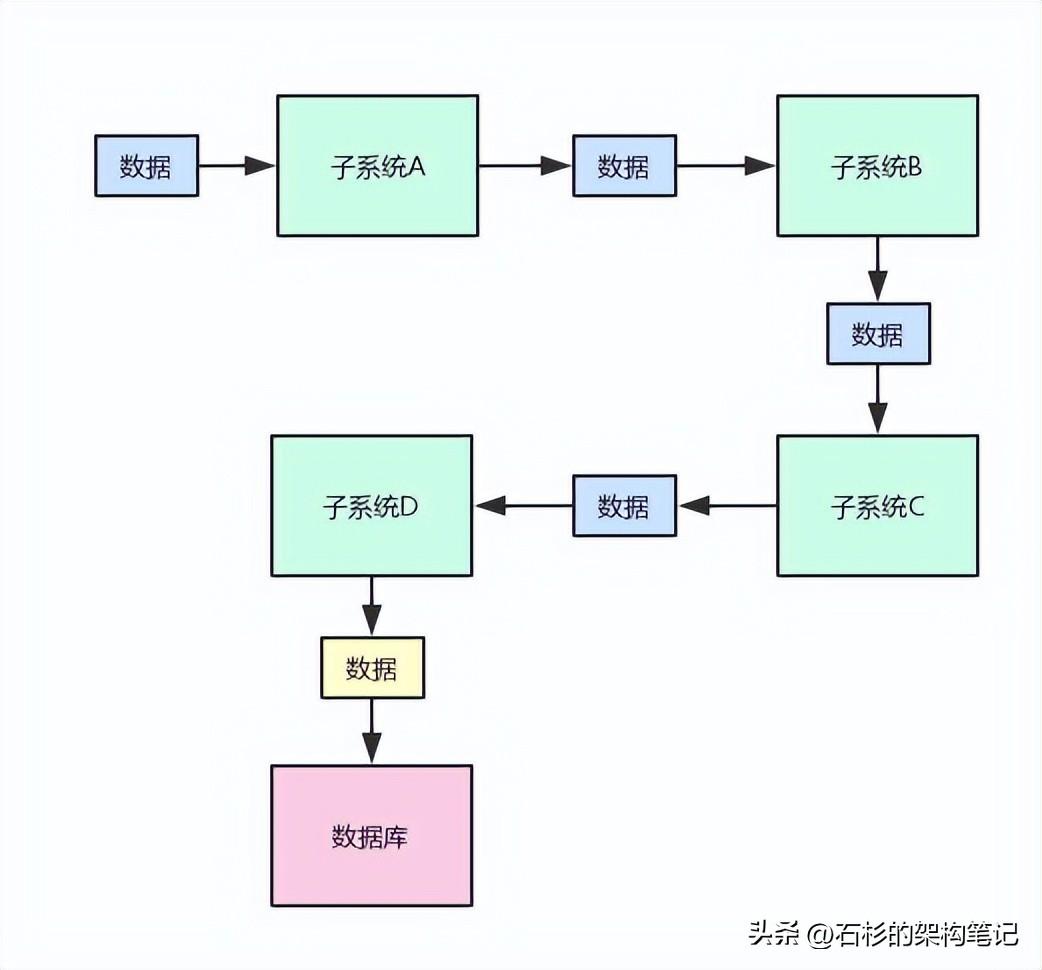
From the above figure, we can see how multiple systems process a piece of data in turn, and finally get a piece of core data and land it in the storage.
Then in this process, the so-called data inconsistency problem may arise.
What does that mean? To give you the simplest example, we originally expected the data change process to be: data 1 -> data 2 -> data 3 -> data 4.
Then the last one that landed in the database should be data 4, right?
The results of it? I don't know why, after the various subsystems in the complex distributed system above, or the cooperative processing of various services, finally a data 87 was produced.
After working for a long time, I made a thing that has nothing to do with the data, and finally landed in the database.
Then, the end user of this system may have seen an inexplicable data 87 through the front-end interface.
This is embarrassing. Users will obviously feel that there is an error in the data, and they will report it to the company's customer service. At this time, the bug will be reported to the engineering team, and everyone will start looking for problems.
The scenario mentioned above is actually a problem of data inconsistency, and it is also a problem that we will discuss in the next few articles.
In fact, in any large-scale distributed system, there will be similar problems. Whether it is e-commerce, O2O, or the data platform system exemplified in this article, it is the same.
3. Sorting out a data computing link
So now that the problem has been clarified, let's take a look at the data platform system, what problems may cause an abnormality in the final stored data?
To understand this problem, let's look back first. In the previously mentioned data platform project, what is the computing link of a finalized data?
Take a look at the picture below:
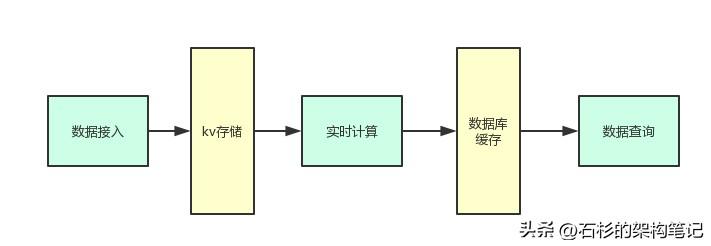
As shown in the figure above, in fact, from the simplest point of view, the link of this data calculation is probably the same as the one above.
- First, the data is obtained through the MySQL binlog collection middleware and forwarded to the data access layer.
- Then, the data access layer will land the original data into the kv storage
- Next, the real-time computing platform will extract data from the kv storage for calculation
- Finally, the calculation results are written to the database + cache cluster. The data query platform will extract data from the database + cache cluster and provide users to query
Seems easy, right?
But even in this system, the data computing link is definitely not that simple.
If you have read the previous series of articles, you should know that this system has introduced a large number of complex mechanisms to support scenarios such as high concurrency, high availability, and high performance.
So in fact, a piece of raw data enters the system and finally landed in the storage, the computing link will also include the following things:
- Current limiting processing at the access layer
- Failed retries at the real-time compute layer
- Degradation mechanism for local memory storage of real-time computing layer
- Aggregation and calculation of data shards, a single piece of data may enter a data shard here
- Multi-level caching mechanism of data query layer
The above are just to name a few. However, even the above mentioned items can complicate the calculation link of a data many times.
Fourth, the data calculation link bug
Now that everyone has understood, in a complex system, a piece of core data may be processed by an extremely complex computing link, with hundreds of turns in the middle, and any possible situation will happen.
Then you can understand how the problem of data inconsistency arises in large distributed systems.
In fact, the reason is very simple. To put it bluntly, it is a bug in the data calculation link.
That is to say, in the process of data calculation, a certain subsystem has a bug, and it is not processed according to our expected behavior, resulting in the final output of the data becomes wrong.
So, why does this bug appear in the data computing link?
The reason is very simple. If you have participated in a large-scale distributed system with hundreds of people, or led the architectural design of a large-scale distributed system developed by hundreds of people, you should be very familiar with the exceptions and errors of core data, and you will feel a headache. endlessly.
In a large-scale distributed system, hundreds of people collaborate in development at every turn. It is very likely that the person in charge of a subsystem or a service has a deviated understanding of the data processing logic, and a hidden bug has been written in the code.
And this bug is not easily triggered, and it has not been detected in the QA test environment. As a result, the system is launched with a time bomb.
Finally, in a special online scenario, this bug was triggered, resulting in a problem with the final data.
5. Inconsistency of e-commerce inventory data
Students who have been in contact with e-commerce may quickly think of a similar classic scene in their minds at this time: inventory in e-commerce.
In a large-scale e-commerce system, inventory data is definitely the core of the core. But in fact, in a distributed system, many systems may use certain logic to update inventory.
This may lead to a problem similar to the above-mentioned scenario, that is, multiple systems update the inventory, but there is a bug in the update of the inventory in a certain system.
This may be because the person in charge of the system did not understand how to update the inventory, or the logic he used when updating did not take into account some special circumstances.
The result of this is that the inventory in the system and the actual inventory in the warehouse do not match up. But I just don't know which link went wrong, causing the inventory data to be wrong.
This is actually a typical data inconsistency problem.
6. How difficult is it to troubleshoot data inconsistencies in large systems
When faced with a large-scale distributed system, if you have never considered the problem of data inconsistency before, then I bet that when the system you are responsible for is online and is reported by customer service that there is a certain core data inconsistency, you will definitely Confused.
Because the processing of a core data, at least it involves the cooperative processing of several systems, and most involves the cooperative processing of more than ten systems.
If you don't keep any logs, or only have some logs, then basically everyone can only stare at each other, everyone staring at their own code.
Everyone is based on the final wrong result of a data, such as data 87. More than 10 people are thinking about their own code repeatedly, thinking hard.
Then everyone madly simulates the operation of their own code in their brains, but just can't figure out why it should be data 4, but a data 87 came out?
So the real problem is this. This data inconsistency problem probably has the following pain points:
Basically, you can't actively perceive data problems in advance. You have to passively wait for users to find out and give feedback to customer service. This is likely to lead to a large number of complaints about your products, the boss is very angry, and the consequences are very serious.
Even if the customer service tells you that the data is wrong, but you can't restore the scene, and there is no evidence left, it is basically a group of engineers who imagine and guess the code.
Even if you solve the problem of data inconsistency once, there may be another time in the future. If you do it like this, several capable guys in the team will spend their time on this kind of shit.